Articles published in peer-reviewed journals are only a tip of the scientific iceberg. Professional organizations want you to believe that these published articles are carefully selected to be the most important and scientifically credible articles. In reality, peer-review is unreliable, invalid, and editorial decisions are based on personal preferences. For this reason, the censoring mechanism is often hidden. Part of the movement towards open science is to make the censoring process transparent.
I therefore post the decision letter and the reviews from JEP:General. I sent my ms “z-curve: an even better p-curve” to this journal because it published two articles on the p-curve method that are highly cited. The key point of my ms. is to point out that the p-curve app produces a “power” estimate of 97% for hand-coded articles by Leif Nelson, while z-curve produces an estimate of 52%. If you are a quantitative scientist, you will agree that this is a non-trivial difference and you are right to ask which of these estimates is more credible. The answer is provided by simulation studies that compare p-curve and z-curve and show that p-curve can dramatically overestimate “power” when the data are heterogeneous (Brunner & Schimmack, 2020). In short, the p-curve app sucks. Let the record show that JEP-General is happy to get more citations for a flawed method. The reason might be that z-curve is able to show publication bias in the original articles published in JEP-General (Replicability Rankings). Maybe Timothy J. Pleskac is afraid that somebody looks at his z-curve, which shows a few too many p-values that are just significant (ODR = 73% vs. EDR = 45%).
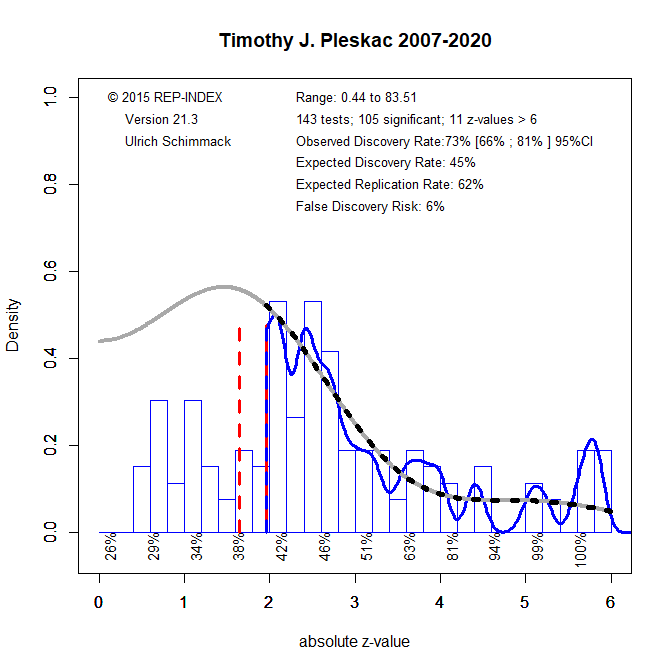
Unfortunately for psychologists, statistics is an objective science that can be evaluated using either mathematical proofs (Brunner & Schimmack, 2020) and simulation studies (Bartos & Schimmack, 2021; Brunner & Schimmack, 2020). It is just hard for psychologists to follow the science, if the science doesn’t agree with their positive illusions and inflated egos.
==========================================================
XGE-2021-3638
Z-curve 2.0: An Even Better P-Curve
Journal of Experimental Psychology: General
Dear Dr. Schimmack,
I have received reviews of the manuscript entitled Z-curve 2.0: An Even Better P-Curve (XGE-2021-3638) that you recently submitted to Journal of Experimental Psychology: General. Upon receiving the paper I read the paper. I agree that Simonsohn, Nelson, & Simmons’ (2014) P-Curve paper has been quite impactful. As I read over the manuscript you submitted, I saw there was some potential issues raised that might help help advance our understanding of how to evaluate scientific work. Thus, I asked two experts to read and comment on the paper. The experts are very knowledgeable and highly respected experts in the topical area you are investigating.
Before reading their reviews, I reread the manuscript, and then again with the reviews in hand. In the end, both reviewers expressed some concerns that prevented them from recommending publication in Journal of Experimental Psychology: General. Unfortunately, I share many of these concerns. Perhaps the largest issue is that both reviewers identified a number formal issues that need more development before claims can be made about the z-curve such as the normality assumptions in the paper. I agree with Reviewer 2 that more thought and work is needed here to establish the validity of these assumptions and where and how these assumptions break down. I also agree with Reviewer 1 that more care is needed when defining and working with the idea of unconditional power. It would help to have the code, but that wouldn’t be sufficient as one should be able to read the description of the concept in the paper and be able to implement it computationally. I haven’t been able to do this. Finally, I also agree with Reviewer 1 that any use of the p-curve should have a p-curve disclosure table. I would also suggest ways to be more constructive in this critique. In many places, the writing and approach comes across as attacking people. That may not be the intention. But, that is how it reads.
Given these concerns, I regret to report that that I am declining this paper for publication in Journal of Experimental Psychology: General. As you probably know, we can accept only small fraction of the papers that are submitted each year. Accordingly, we must make decisions based not only on the scientific merit of the work but also with an eye to the potential level of impact for the findings for our broad and diverse readership. If you decide to pursue publication in another journal at some point (which I hope you will consider), I hope that the suggestions and comments offered in these reviews will be helpful.
Thank you for submitting your work to the Journal. I wish you the best in your continued research, and please try us again in the future if you think you have a manuscript that is a good fit for Journal of Experimental Psychology: General.
Sincerely,
Timothy J. Pleskac, Ph.D.
Associate Editor
Journal of Experimental Psychology: General
Reviewers’ comments:
Reviewer #1: 1. This commentary submitted to JEPG begins presenting a p-curve analysis of early work by Leif Nelson.
Because it does not provide a p-curve disclosure table, this part of the paper cannot be evaluated.
The first p-curve paper (Simonsohn et al, 2014) reads: “P-curve disclosure table makes p-curvers accountable for decisions involved in creating a reported p-curve and facilitates discussion of such decisions. We strongly urge journals publishing p-curve analyses to require the inclusion of a p-curve disclosure table.” (p.540). As a reviewer I am aligning with these recommendation and am *requiring* a p-curve disclosure table, as in, I will not evaluate that portion of the paper, and moreover I will recommend the paper be rejected unless that analysis is removed, or a p-curve disclosure table is included, and is then evaluated as correctly conducted by the review team in an subsequent round of evaluation. The p-curve disclosure table for the Russ et al p-curve, even if not originally conducted by these authors, should be included as well, with a statement that the authors of this paper have examined the earlier p-curve disclosure table and deemed it correct. If an error exists in the literature we have to fix it, not duplicate it (I don’t know if there is an error, my point is, neither do the authors who are using it as evidence).
2. The commentary then makes arguments about estimating conditional vs unconditional power. While not exactly defined in the article, the authors come pretty close to defining conditional power, I think they mean by it the average power conditional on being included in p-curve (ironically, if I am wrong about the definition, the point is reinforced). I am less sure about what they mean by unconditional power. I think they mean that they include in the population parameter of interest not only the power of the studies included in p-curve, but also the power of studies excluded from it, so ALL studies. OK, this is an old argument, dating back to at least 2015, it is not new to this commentary, so I have a lot to say about it.
First, when described abstractly, there is some undeniable ‘system 1’ appeal to the notion of unconditional power. Why should we restrict our estimation to the studies we see? Isn’t the whole point to correct for publication bias and thus make inferences about ALL studies, whether we see them or not? That’s compelling. At least in the abstract. It’s only when one continues thinking about it that it becomes less appealing. More concretely, what does this set include exactly? Does ‘unconditional power’ include all studies ever attempted by the researcher, does it include those that could have been run but for practical purposes weren’t? does it include studies run on projects that were never published, does it include studies run, found to be significant, but eventually dropped because they were flawed? Does it include studies for which only pilots were run but not with the intention of conducting confirmatory analysis? Does it include studies which were dropped because the authors lost interest in the hypothesis? Does it include studies that were run but not published because upon seeing the results the authors came up with a modification of the research question for which the previous study was no longer relevant? Etc etc). The unconditional set of studies is not a defined set, without a definition of the population of studies we cannot define a population parameter for it, and we can hardly estimate a non-existing parameter. Now. I don’t want to trivialize this point. This issue of the population parameter we are estimating is an interesting issue, and reasonable people can disagree with the arguments I have outlined above (many have), but it is important to present the disagreement in a way that readers understand what it actually entails. An argument about changing the population parameter we estimate with p-curve is not about a “better p-curve”, it is about a non-p-curve. A non-p-curve which is better for the subset of people who are interested in the unconditional power, but a WORSE p-curve for those who want the conditional power (for example, it is worse for the goals of the original p-curve paper). For example, the first paper using p-curve for power estimation reads “Here is an intuitive way to think of p-curve’s estimate: It is the average effect size one expects to get if one were to rerun all studies included in p-curve”. So a tool which does not estimate that value, but a different value, it is not better, it is different. The standard deviation is neither better nor worse than the mean. They are different. It would be silly to say “Standard Deviation, a better Mean (because it captures dispersion and the mean does not)”. The standard deviation is better for someone interested in dispersion, and the standard deviation is worse for someone interested in the central tendency. Exactly the same holds for conditional vs unconditional power. (well, the same if z-curve indeed estimated unconditional power, i don’t know if that is true or not. Am skeptical but open minded).
Second, as mentioned above, this distinction of estimating the parameter of the subset of studies included in p-curve vs the parameter of “all studies” is old. I think that argument is seen as the core contribution of this commentary, and that contribution is not close to novel. As the quote above shows, it is a distinction made already in the original p-curve paper for estimating power. And, it is also not new to see it as a shortcoming of p-curve analysis. Multiple papers by Van Assen and colleagues, and by McShane and colleagues, have made this argument. They have all critiqued p-curve on those same grounds.
I therefore think this discussion should improve in the following ways: (i) give credit, and give voice, to earlier discussions of this issue (how is the argument put forward here different from the argument put forward in about a handful of previous papers making it, some already 5 years ago), (ii) properly define the universe of studies one is attempting to estimate power for (i.e., what counts in the set of unconditional power), and (iii) convey more transparently that this is a debate about what is the research question of interest, not of which tool provides the better answer to the same question. Deciding whether one wants to estimate the average power of one or another set of studies is completely fair game of an issue to discuss, and if indeed most readers don’t think they care about conditional power, and those readers use p-curve not realizing that’s what they are estimating, it is valuable to disabuse them of their confusion. But it is not accurate, and therefore productive, to describe this as a statistical discussion, it is a conceptual discussion.
3. In various places the paper reports results from calculations, but the authors have not shared neither the code nor data for those calculations, so these results cannot be adequately evaluated in peer-review, and that is the very purpose of peer-review. This shortcoming is particularly salient when the paper relies so heavily on code and data shared in earlier published work.
Finally, it should be clearer what is new in this paper. What is said here that is not said in the already published z-curve paper and p-curve critique papers?
Reviewer #2:
The paper reports a comparison between p-curve and z-curve procedures proposed in the literature. I found the paper to be unsatisfactory, and therefore cannot recommend publication in JEP:G. It reads more like a cropped section from the author’s recent piece in meta-psychology than a standalone piece that elaborates on the different procedures in detail. Because a lot is completely left out, it is very difficult to evaluate the results. For example, let us consider a couple of issues (this is not an exhaustive list):
– The z-curve procedure assumes that z-transformed p-values under the null hypothesis follow a standard Normal distribution. This follows from the general idea that the distribution of p-values under the null-hypothesis is uniform. However, this general idea is not necessarily true when p-values are computed for discrete distributions and/or composite hypotheses are involved. This seems like a point worth thinking about more carefully, when proposing a procedure that is intended to be applied to indiscriminate bodies of p-values. But nothing is said about this, which strikes me as odd. Perhaps I am missing something here.
– The z-curve procedure also assumes that the distribution of z-transformed p-values follows a Normal distribution or a mixture of homoskedastic Normals (distributions that can be truncated depending on the data being considered/omitted). But how reasonable is this parametric assumption? In their recently published paper, the authors state that this is as **a fact**, but provide no formal proof or reference to one. Perhaps I am missing something here. If anything, a quick look at classic papers on the matter, such as Hung et al. (1997, Biometrics), show that the cumulative distributions of p-values under different alternatives cross-over, which speaks against the equal-variance assumption. I don’t think that these questions about parametric assumptions are of secondary importance, given that they will play a major in the parameter estimates obtained with the mixture model.
Also, when comparing the different procedures, it is unclear whether the reported disagreements are mostly due to pedestrian technical choices when setting up an “app” rather than irreconcilable theoretical commitments. For example, there is nothing stopping one from conducting a p-curve analysis on a more fine-grained scale. The same can be said about engaging in mixture modeling. Who is/are the culprit/s here?
Finally, I found that the writing and overall tone could be much improved.
The reviewer comments seem quite reasonable. Your re-analysis of Leif Nelson is meaningful and of interest, but the first reviewer’s comments about a disclosure table are justified given the reputational context. Especially in a paper about data, your own data should be held to standard.
Publishing these private communications is a breach of etiquette, but only a minor issue here. As for the attack on JEP-General trying to get more citations, and especially the personal attack on Pleskac being afraid of his own z-curve, these are definitely unwarranted. Throwing accusations just because people did not rule in your favor is an unpleasant practice.
Dear Anonymous Coward,
you think that the reviewer comments are reasonable, but they do not address the main point of the ms. Here is the key issue. Two methods aim to estimate the same parameter. One method produces an estimate of 97%. The other method produces an estimate of 52%. Is this a problem for you? If so, how do the reviewers address this problem? They don’t. So, they do not address the key issue of the manuscript. Reasonable?
If the lack of a disclosure table is a problem, the editor could have just asked for it. To reject the paper because some information was missing is not reasonable.
Why was the ms. rejected? We don’t really know and you may not like my speculations, but the fact remains that JEP-General was not interested in pointing out that a method that was published in their journal produces biased results.
I think you are engaging in conspiracy theorism, if you believe that the associate editor is motivated by wanting to protect the journal from a paper that criticizes prior work in the same journal. Do you believe that the APA has a smoke-filled back room where editors, associate editors, and reviewers strike deals with one another to keep out certain threatening ideas? None of this is to say that the ideas in your paper are incorrect, but it seems a tad hypocritical for someone who likes to point out the weaknesses of peer review, that you would be unwilling to accept skepticism and try to overcome it, rather than resorting to lazy name-calling.
I totally understand that somebody who is unfamiliar with the topic would think my reaction is based on motivated biases and hurt ego. However, one has to wonder why somebody would reject a paper that points out that a published method can lead to biased estimates that are 30 percentage points to high. Does that not warrant publication, maybe after a revision that takes care of the petty objections that were raised?