Background: A previous blog post shared a conversation between Bill von Hippel and Ulrich Schimmack about Bill’s Replicability Index (Part 1). To recapitulate, I had posted statistical replicability estimates for several hundred social psychologists (Personalized P-Values). Bill’s scores suggested that many of his results with p-values just below .05 might not be replicable. Bill was dismayed by his low R-Index but thought that some of his papers with very low values might be more replicable than the R-Index would indicate. He suggested that we put the R-Index results to an empirical test. He chose his paper with the weakest statistical evidence (interaction p = .07) for a replication study. We jointly agreed on the replication design and sample size. In just three weeks the study was approved, conducted, and the results were analyzed. Here we discuss the results.
…. Three Weeks Later
Bill: Thanks to rapid turnaround at our university IRB, the convenience of modern data collection, and the programming skills of Sam Pearson, we have now completed our replication study on Prolific. We posted the study for 2,000 participants, and 2,031 people signed up. For readers who are interested in a deeper dive, the data file is available at https://osf.io/cu68f/ and the pre-registration at https://osf.io/7ejts.
To cut to the chase, this one is a clear win for Uli’s R-Index. We successfully replicated the standard effect documented in the prior literature (see Figure A), but there was not even a hint of our predicted moderation of that effect, which was the key goal of this replication exercise (see Figure B: Interaction F(1,1167)=.97, p=.325, and the nonsignificant mean differences don’t match predictions). Although I would have obviously preferred to replicate our prior work, given that we failed to do so, I’m pleased that there’s no hint of the effect so I don’t continue to think that maybe it’s hiding in there somewhere. For readers who have an interest in the problem itself, let me devote a few paragraphs to what we did and what we found. For those who are not interested in Darwinian Grandparenting, please skip ahead to Uli’s response.

Previous work has established that people tend to feel closest to their mother’s mother, then their mother’s father, then their father’s mother, and last their father’s father. We replicated this finding in our prior paper and replicated it again here as well. The evolutionary idea underlying the effect is that our mother’s mother knows with certainty that she’s related to us, so she puts greater effort into our care than other grandparents (who do not share her certainty), and hence we feel closest to her. Our mother’s father and father’s mother both have one uncertain link (due to the possibility of cuckoldry), and hence put less effort into our care than our mother’s mother, so we feel a little less close to them. Last on the list is our father’s father, who has two uncertain links to us, and hence we feel least close to him.
The puzzle that motivated our previous work lies in the difference between our mother’s father and father’s mother; although both have one uncertain link, most studies show that people feel closer to their mother’s father than their father’s mother. The explanation we had offered for this effect was based on the idea that our father’s mother often has daughters who often have children, providing her with a more certain outlet for her efforts and affections. According to this possibility, we should only feel closer to our mother’s father than our father’s mother when the latter has grandchildren via daughters, and that is what our prior paper had documented (in the form of a marginally significant interaction and predicted simple effects).
Our clear failure to replicate that finding suggests an alternative explanation for the data in Figure A:
- People are closer to their maternal grandparents than their paternal grandparents (possibly for the reasons of genetic certainty outlined above).
- People are closer to their grandmothers than their grandfathers (possibly because women tend to be more nurturant than men and more involved in childcare).
- As a result of these two main effects, people tend to be closer to their mothers’ father than their father’s mother, and this particular difference emerges in the presence or absence of other more certain kin.
Does our failure to replicate mean that the presence or absence of more certain kin has no impact on grandparenting? Clearly not in the manner I expected, but that doesn’t mean it has no effect. Consider the following (purely exploratory, non-preregistered) analyses of these same data: After failing to find the predicted interaction above, I ran a series of regression analyses, in which closeness to maternal and paternal grandparents were the dependent variables and number of cousins via fathers’ and mothers’ brothers and sisters were the predictor variables. The results are the same whether we’re looking at grandmothers or grandfathers, so for the sake of simplicity, I’ve collapsed the data into closeness to paternal grandparents and closeness to maternal grandparents. Here are the regression tables:
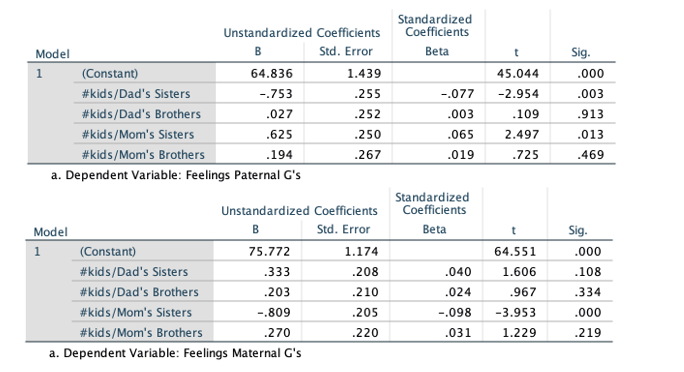
We see three very small but significant findings here (all of which require replication before we have any confidence in them). First, people feel closer to their paternal grandparents to the degree that those grandparents are not also maternal grandparents to someone else (i.e., more cousins through fathers’ sisters are associated with less closeness to paternal grandparents). Second, people feel closer to their paternal grandparents to the degree that their maternal grandparents have more grandchildren through daughters other than their mother (i.e., more cousins through mothers’ sisters are associated with more closeness to paternal grandparents). Third, people feel closer to their maternal grandparents to the degree that those grandparents are not also maternal grandparents to someone else (i.e., more cousins through mothers’ sisters are associated with less closeness to maternal grandparents). Note that none of these effects emerged via cousins through father’s or mother’s brothers. These findings strike me as worthy of follow-up, as they suggest that the presence or absence of equally or more certain kin does indeed have a (very small) influence on grandparents in a manner that evolutionary theory would predict (even if I didn’t predict it myself).
Uli: Wow, I am impressed how quickly research with large samples can be done these days. That is good news for the future of social psychology, at least the studies that are relatively easy to do.
Bill: Agreed! But benefits rarely come without cost and studies on the web are no exception. In this case, the ease of working on the web also distorts our field by pushing us to do the kind of work that is ‘web-able’ (e.g., self-report) or by getting us to wangle the methods to make them work on the web. Be that as it may, this study was a no brainer, as it was my lowest R-Index and pure self-report. Unfortunately, my other papers with really low R-Indices aren’t as easy to go back and retest (although I’m now highly motivated to try).
Uli: Of course, I am happy that R-Index made the correct prediction, but N = 1 is not that informative.
Bill: Consider this N+1, as it adds to your prior record.
Uli: Fortunately, R-Index also does make good, although by no means, perfect predictions in general; https://replicationindex.com/2021/05/16/pmvsrindex/.
Bill: Very interesting.
Uli: Maybe you set yourself up for failure by picking a marginally significant result.
Bill: That was exactly my goal. I still believed in the finding, so it was a great chance to pit your method against my priors. Not much point in starting with one of my results that we both agree is likely to replicate.
Uli: The R-Index analysis implied that we should only trust your results with p < .001.
Bill: That seems overly conservative to me, but of course I’m a biased judge of my own work. Out of curiosity, is that p value better when you analyze all my critical stats rather than just one per experiment? This strikes me as potentially important, because almost none of my papers would have been accepted based on just a single statistic; rather, they typically depend on a pattern of findings (an issue I mentioned briefly in our blog).
Uli: The rankings are based on automatic extraction of test statistics. Selecting focal tests would only lead to an even more conservative alpha criterion. To evaluate the alpha = .001 criterion, it is not fair to use a single p = .07 result. Looking at the original article about grandparent relationships, I see p < .001 for mother’s mother vs. mother’s father relationships. The other contrasts are just significant and do not look credible according to R-Index (predicting failure for same N). However, they are clearly significant in the replication study. So, R-Index made two correct predictions (one failure and one success), and two wrong predictions. Let’s call it a tie. 🙂
Bill: Kind of you, but still a big win for the R-Index. It’s important to keep in mind that many prior papers had found the other contrasts, whereas we were the first to propose and find the specific moderation highlighted in our paper. So a reasonable prior would set the probability much higher to replicate the other effects, even if we accept that many prior findings were produced in an era of looser research standards. And that, in turn, raises the question of whether it’s possible to integrate your R-Index with some sort of Bayesian prior to see if it improves predictive ability.
Your prediction markets v. R-Index blog makes the very good point that simple is better and the R-Index works awfully well without the work involved in human predictions. But when I reflect on how I make such predictions (I happened to be a participant in one of the early prediction market studies and did very well), I’m essentially asking whether the result in question is a major departure from prior findings or an incremental advance that follows from theory. When the former, I say it won’t replicate without very strong statistical evidence. When the latter, I say it will replicate. Would it be possible to capture that sort of Bayesian processing via machine learning and then use it to supplement the R-Index?
Uli: There is an article that tried to do this. Performance was similar to prediction markets. However, I think it is more interesting to examine the actual predictors that may contribute to the prediction of replication outcomes. For example, we know cognitive psychology and within-subject designs are more replicable than social psychology and between-subject designs. I don’t think, however, we will get very far based on single questionable studies. Bias-corrected meat-analysis may be the only way to salvage robust findings from the era of p-hacking.
To broaden the perspective from this single article to your other articles, one problem with the personalized p-values is that they are aggregated across time. This may lead to overly conservative alpha levels (p < .001) for new research that was conducted in accordance with new rules about transparency, while the rules may be too liberal for older studies that were conducted in a time when awareness about the problems of selection for significance was lacking (say before 2013). Inspired by the “loss of confidence project” (Rohrer et al., 2021), I want to give authors the opportunity to exclude articles from their R-Index analysis that they no longer consider credible themselves. To keep track of these loss-of-confidence declaration, I am proposing to use PubPeer (https://pubpeer.com/). Once an author posts a note on PubPeer that declares loss of confidence in the empirical results of an article, the article will be excluded from the R-Index analysis. Thus, authors can improve their standing in the rankings and, more importantly, change the alpha level to a more liberal level (e.g., from .005 to .01) by (a) publicly declaring loss of confidence in a finding and (b) publishing new research with studies that have more power and honestly report non-significant results.
I hope that the incentive to move up in the rankings will increase the low rate of loss of confidence declarations and help us to clean up the published record faster. Declarations could also be partial. For example, for the 2005 article, you could post a note on PubPeer that the ordering of the grandparent relationships was successfully replicated and the results for cousins were not with a link to the data and hopefully eventually a publication. I would then remove this article from the R-Index analysis. What do you think about this idea?
Bill: I think this is a very promising initiative! The problem, as I see it, is that authors are typically the last ones to lose confidence in their own work. When I read through the recent ‘loss of confidence’ reports, I was pretty underwhelmed by the collection. Not that there was anything wrong with the papers in there, but rather that only a few of them surprised me.
Take my own case as an example. I obviously knew it was possible my result wouldn’t replicate, but I was very willing to believe what turned out to be a chance fluctuation in the data because it was consistent with my hypothesis. Because I found that hypothesis-consistent chance fluctuation on my first try, I would never have stated I have low confidence in it if you hadn’t highlighted it as highly improbable. In other words, there’s no chance I’d have put that paper on a ‘loss of confidence’ list without your R-Index telling me it was crap and even then it took a failure to replicate for me to realize you were right.
Thus, I would guess that uptake into the ‘loss of confidence’ list would be low if it emphasizes work that people feel was sloppy in the first place, not because people are liars, but because people are motivated reasoners.
With that said, if the collection also emphasizes work that people have subsequently failed to replicate, and hence have lost confidence in it, I think it would be used much more frequently and could become a really valuable corrective. When I look at the Darwinian Grandparenting paper, I see that it’s been cited over 150 times on google scholar. I don’t know how many of those papers are citing it for the key moderation effect that we now know doesn’t replicate, but I hope that no one else will cite it for that reason after we publish this blog. No one wants other investigators to waste time following up their work once they realize the results aren’t reliable.
Uli: (feeling a bit blue today). I am not very optimistic that authors will take note of replication failures. Most studies are not conducted after a careful review of the existing literature or a meta-analysis that takes publication bias into account. As a result, citations in articles are often picked because they help to support a finding in an article. While p-hacking of data may have decreased over the past decade in some areas, cherry-picking of references is still common and widespread. I am not really sure how we can speed up self-correction of science. My main hope is that meta-analyses are going to improve and take publication bias more seriously. Fortunately, new methods show promising results in debiasing effect sizes estimates (Bartoš, Maier, Wagenmakers, Doucouliagos, & Stanley, 2021). Z-curve is also being used by meta-analysists and we are hopeful that z-curve 2.0 will soon be accepted for publication in Meta-Psychology (Bartos & Schimmack, 2021). Unfortunately, it will take another decade for these methods to become mainstream and meanwhile many resources will be wasted on half-baked ideas that are grounded in a p-hacked literature. I am not optimistic that psychology will become a rigorous science during my lifetime. So, I am trying to make the best of it. Fortunately, I can just do something else when things are too depressing, like sitting in my backyard and watch Germany win at the Euro cup. Life is good, psychological science not so much.
Bill: I don’t blame you for your pessimism, but I completely disagree. You see a science that remains flawed when we ought to know better, but I see a science that has improved dramatically in the 35 years since I began working in this field. Humans are wildly imperfect actors who did not evolve to be dispassionate interpreters of data. We hope that training people to become scientists will debias them – although the data suggest that it doesn’t – and then we double down by incentivizing scientists to publish results that are as exciting as possible as rapidly as possible.
Thankfully bias is the both the problem and the solution, as other scientists are biased in favor of their theories rather than ours, and out of this messy process the truth eventually emerges. The social sciences are a dicier proposition in this regard, as our ideologies intersect with our findings in ways that are less common in the physical and life sciences. But so long as at least some social scientists feel free to go wherever the data lead them, I think our science will continue to self-correct, even if the process often seems painfully slow.
Uli: Your response to my post is a sign that progress is possible, but 1 out of 400 may just be the exception to the rule to never question your own results. Even researchers who know better become promoters of their own theories, especially when they become popular. I think the only way to curb false enthusiasm is to leave the evaluation of theories (review articles, meta-analysis) to independent scientists. The idea that one scientist can develop and evaluate a theory objectively is simply naive. Leaders of a paradigm are like strikers in soccer. They need to have blinders on to risk failure. We need meta-psychologists to distinguish real contributions from false ones. In this way meta-psychologists are like referees. Referees are not glorious heroes, but they are needed for a good soccer game, and they have the power to call of a goal because a player was offside or used their hands. The problem for science is the illusion that scientists can control themselves.