John P. A. Ioannidis is a rock star in the world of science (wikipedia).

By traditional standards of science, he is one of the most prolific and influential scientists alive. He has published over 1,000 articles that have been cited over 100,000 times.

He is best known for the title of his article “Why most published research findings are false” that has been cited nearly 5,000 times. The irony of this title is that it may also apply to Ioannidis, especially because there is a trade-off between quality and quantity in publishing.
Fact Checking Ioannidis
The title of Ioannidis’s article implies a factual statement: “Most published results ARE false.” However, the actual article does not contain empirical data to support this claim. Rather, Ioannidis presents some hypothetical scenarios that show under what conditions published results MAY BE false.
To produce mostly false findings, a literature has to meet two conditions.
First, it has to test mostly false hypotheses.
Second, it has to test hypotheses in studies with low statistical power, that is a low probability of producing true positive results.
To give a simple example, imagine a field that tests only 10% true hypothesis with just 20% power. As power predicts the percentage of true discoveries, only 2 out of the 10 true hypothesis will be significant. Meanwhile, the alpha criterion of 5% implies that 5% of the false hypotheses will also produce a significant result. Thus, 5 of the 90 false hypotheses will also produce a significant result. As a result, there will be two times more false positives (4.5 over 100) than true positives (2 over 100).

These relatively simple calculations were well known by 2005 (Soric, 1989). Thus, why did Ioannidis article have such a big impact? The answer is that Ioannidis convinced many people that his hypothetical examples are realistic and describe most areas in science.
2020 has shown that Ioannidis’s claim does not apply to all areas of science. In amazing speed, bio-tech companies were able to make not just one but several successful vaccine’s with high effectiveness. Clearly some sciences are making real progress. On the other hand, other areas of science suggest that Ioannidis’s claims were accurate. For example, the whole literature on single-gene variations as predictors of human behavior has produced mostly false claims. Social psychology has a replication crisis where only 25% of published results could be replicated (OSC, 2015).
Aside from this sporadic and anecdotal evidence, it remains unclear how many false results are published in science as a whole. The reason is that it is impossible to quantify the number of false positive results in science. Fortunately, it is not necessary to know the actual rate of false positives to test Ioannidis’s prediction that most published results are false positives. All we need to know is the discovery rate of a field (Soric, 1989). The discovery rate makes it possible to quantify the maximum percentage of false positive discoveries. If the maximum false discovery rate is well below 50%, we can reject Ioannidis’s hypothesis that most published results are false.
The empirical problem is that the observed discovery rate in a field may be inflated by publication bias. It is therefore necessary to estimate the amount of publication bias and if necessary correct the discovery rate, if publication bias is present.
In 2005, Ioannidis and Trikalinos (2005) developed their own test for publication bias, but this test had a number of shortcomings. First, it could be biased in heterogeneous literatures. Second, it required effect sizes to compute power. Third, it only provided information about the presence of publication bias and did not quantify it. Fourth, it did not provide bias-corrected estimates of the true discovery rate.
When the replication crisis became apparent in psychology, I started to develop new bias tests that address these limitations (Bartos & Schimmack, 2020; Brunner & Schimmack, 2020; Schimmack, 2012). The newest tool, called z-curve.2.0 (and yes, there is a app for that), overcomes all of the limitations of Ioannidis’s approach. Most important, it makes it possible to compute a bias-corrected discovery rate that is called the expected discovery rate. The expected discovery rate can be used to examine and quantify publication bias by comparing it to the observed discovery rate. Moreover, the expected discovery rate can be used to compute the maximum false discovery rate.
The Data
The data were compiled by Simon Schwab from the Cochrane database (https://www.cochrane.org/) that covers results from thousands of clinical trials. The data are publicly available (https://osf.io/xjv9g/) under a CC-By Attribution 4.0 International license (“Re-estimating 400,000 treatment effects from intervention studies in the Cochrane Database of Systematic Reviews”; (see also van Zwet, Schwab, & Senn, 2020).
Studies often report results for several outcomes. I selected only results for the primary outcome. It is often suggested that researchers switch outcomes to produce significant results. Thus, primary outcomes are the most likely to show evidence of publication bias, while secondary outcomes might even be biased to show more negative results for the same reason. The choice of primary outcomes also ensures that the test statistics are statistically independent because they are based on independent samples.
Results
I first fitted the default model to the data. The default model assumes that publication bias is present and only uses statistically significant results to fit the model. Z-curve.2.0 uses a finite mixture model to approximate the observed distribution of z-scores with a limited number of non-centrality parameters. After finding optimal weights for the components, power can be computed as the weighted average of the implied power of the components (Bartos & Schimmack, 2020). Bootstrapping is used to compute 95% confidence intervals that have shown to have good coverage in simulation studies (Bartos & Schimmack, 2020).

The main finding with the default model is that the model (grey curve) fits the observed distribution of z-scores very well in the range of significant results. However, z-curve has problems extrapolating from significant results to the distribution of non-significant results. In this case, the model (grey curve) underestimates the amount of non-significant results. Thus, there is no evidence of publication bias. This is seen in a comparison of the observed and expected discovery rates. The observed discovery rate of 26% is lower than the expected discovery rate of 38%.
When there is no evidence of publication bias, there is no reason to fit the model only to the significant results. Rather, the model can be fitted to the full distribution of all test statistics. The results are shown in Figure 2.

The key finding for this blog post is that the estimated discovery rate of 27% closely matches the observed discovery rate of 26%. Thus, there is no evidence of publication bias. In this case, simply counting the percentage of significant results provides a valid estimate of the discovery rate in clinical trials. Roughly one-quarter of trials end up with a positive result. The new question is how many of these results might be false positives.
To maximize the rate of false positives, we have to assume that true positives were obtained with maximum power (Soric, 1989). In this scenario, we could get as many as 14% (4 over 27) false positive results.

Even if we use the upper limit of the 95% confidence interval, we only get 19% false positives. Moreover, it is clear that Soric’s (1989) scenario overestimate the false discovery rate because it is unlikely that all tests of true hypotheses have 100% power.
In short, an empirical test of Ioannidis’s hypothesis that most published results in science are false shows that this claim is at best a wild overgeneralization. It is not true for clinical trials in medicine. In fact, the real problem is that many clinical trials may be underpowered to detect clinically relevant effects. This can be seen in the estimated replication rate of 61%, which is the mean power of studies with significant results. This estimate of power includes false positives with 5% power. If we assume that 14% of the significant results are false positives, the conditional power based on a true discovery is estimated to be 70% (14 * .05 + 86 * . 70 = .61).
With information about power, we can modify Soric’s worst case scenario and change power from 100% to 70%. This has only a small influence on the false positive discovery rate that decreases to 11% (3 over 27). However, the rate of false negatives increases from 0 to 14% (10 over 74). This also means that there are now three-times more false negatives than false positives (10 over 3).
Even this scenario overestimates power of studies that produced false negative results because power of studies with significant results is higher than power of studies that produced non-significant results when power is heterogenous (Brunner & Schimmack, 2020). In the worst case scenario, the null-hypothesis may rarely be true and power of studies with non-significant results could be as low as 14.5%. To explain, if we redo all of the studies, we expected that 61% of the significant studies produce a significant result again, producing 16.5% significant results. We also expect that the discovery rate will be 27% again. Thus, the remaining 73% of studies have to make up the difference between 27% and 16.5%, which is 10.5%. For 73 studies to produce 10.5 significant results, the studies have to have 14.5% power. 27 = 27 * .61 + 73 * .145.
In short, while Ioannidis predicted that most published results are false positives, it is much more likely that most published results are false negatives. This problem is of course not new. To make conclusions about effectiveness of treatments, medical researchers usually do not rely on a single clinical trial. Rather results of several studies are combined in a meta-analysis. As long as there is no publication bias, meta-analyses of original studies can boost power and reduce the risk of false negative results. It is therefore encouraging that the present results suggest that there is relatively little publication bias in these studies. Additional analyses for subgroups of studies can be conducted, but are beyond the main point of this blog post.
Conclusion
Ioannidis wrote an influential article that used hypothetical scenarios to make the prediction that most published results are false positives. Although this article is often cited as if it contained evidence to support this claim, the article contained no empirical evidence. Surprisingly, there also have been few attempts to test Ioannidis’s claim empirically. Probably the main reason is that nobody knew how to test it. Here I showed a way to test Ioannidis’s claim and I presented clear empirical evidence that contradicts this claim in Ioannidis’s own field of science, namely medicine.
The main feature that distinguishes science and fiction is not that science is always right. Rather, science is superior because proper use of the scientific method allows for science to correct itself, when better data become available. In 2005, Ioannidis had no data and no statistical method to prove his claim. Fifteen years later, we have good data and a scientific method to test his claim. It is time for science to correct itself and to stop making unfounded claims that science is more often wrong than right.
The danger of not trusting science has been on display this year, where millions of Americans ignored good scientific evidence, leading to the unnecessary death of many US Americans. So far, 330, 000 US Americans are estimated to have died of Covid-19. In a similar country like Canada, 14,000 Canadians have died so far. To adjust for population, we can compare the number of deaths per million, which is 1000 in the USA and 400 in Canada. The unscientific approach to the pandemic in the US may explain some of this discrepancy. Along with the development of vaccines, it is clear that science is not always wrong and can save lives. Iannaidis (2005) made unfounded claims that success stories are the exception rather than the norm. At least in medicine, intervention studies show real successes more often than false ones.
The Covid-19 pandemic also provides another example where Ioannidis used off-the-cuff calculations to make big claims without any evidence. In a popular article titled “A fiasco in the making” he speculated that the Covid-19 virus might be less deadly than the flu and suggested that policies to curb the spread of the virus were irrational.

As the evidence accumulated, it became clear that the Covid-19 virus is claiming many more lives than the flu, despite policies that Ioannidis considered to be irrational. Scientific estimates suggest that Covid-19 is 5 to 10 times more deadly than the flu (BNN), not less deadly as Ioannidis implied. Once more, Ioannidis quick, unempirical claims were contradicted by hard evidence. It is not clear how many of his other 1,000 plus articles are equally questionable.
To conclude, Ioannidis should be the last one to be surprised that several of his claims are wrong. Why should he be better than other scientists? The question is only how he deals with this information. However, for science it is not important whether scientists correct themselves. Science corrects itself by replacing old, false information with better information. One question is what science does with false and misleading information that is highly cited.
If YouTube can remove a video with Ioannidis’s false claims about Covid-19 (WP), maybe PLOS Medicine can retract an article with the false claim that “most published results in science are false”.

The attention-grabbing title is simply misleading because nothing in the article supports the claim. Moreover, actual empirical data contradict the claim at least in some domains. Most claims in science are not false and in a world with growing science skepticism spreading false claims about science may be just as deadly as spreading false claims about Covid-19.
If we learned anything from 2020, it is that science and democracy are not perfect, but a lot better than superstition and demagogy.
I wish you all a happier 2021.
You lost me at “there is no publication bias” …
In these data, there is no publication bias. Of course, there is publication bias in other datasets. But rather than making dogmatic prior assumptions about it, I look at the data to see whether publication bias is present.
lectori salutem,
“2020 has shown that Ioannidis’s claim does not apply to all areas of science. In amazing speed, bio-tech companies were able to make not just one but several successful vaccine’s with high effectiveness. Clearly some sciences are making real progress.”
Is this a fact?
Succesful, high effectiveness
Is what a fact?
very interesting. what i think would be really useful actually, is an article on what are the signs that significantly increase the likelihood of a paper published that displays results that are potentially unreplicable. one of the top of my head is very, very complex methodology.
This isn’t anything to do with Ioannidis or COVID-19. I strongly believe we shouldn’t take anything anyone says for granted, and equipping ordinary people(like me) to detect potentially unreplicable results in research published.
The noise of the few will always be louder than the silence of the many. Maybe science would could benefit from more conscientious teamwork than from the continued competition for attention.Thank you for doing the work to provide empirical data for these lurid theses.
While the data used above certainly refutes the strong claim from Ioannidis’ article. However, they are probably not very representative compared to other reviews that suggest strong biases in favor of significant results (e.g. Francis, 2014; Sterling, Rosenbaum, & Weinkam, 1995).
Publish this important work!
We are trying. 🙂
“To maximize the rate of false positives, we have to assume that true positives were obtained with maximum power”
How is this even possible? To maximise the rate of false discoveries, I would want to have minimum power (least true positives) and fish for significance (maximise false positives). This way my ratio of significant results are tutored with more false positives than true positives. You lost me at that part, can you clarify?
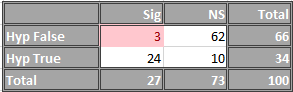
Maybe easiest with an example using a 2 x 2 with 100 studies and 25 significant results.
One scenario assumes 100% power
ns sig
H1 0 23 23
Ho 73 4 77
FPR = 4/23
The other scenario assumes 25 power.
ns sig
H1 60 20 80
Ho 19 1 20
FPR = 1/20
4/23 > 1/20