
It was relatively quiet on academic twitter when most academics were enjoying the last weeks of summer before the start of a new, new-normal semester. This changed on August 17, when the datacolada crew published a new blog post that revealed fraud in a study of dishonesty (http://datacolada.org/98). Suddenly, the integrity of social psychology was once again discussed on twitter, in several newspaper articles, and an article in Science magazine (O’Grady, 2021). The discovery of fraud in one dataset raises questions about other studies in articles published by the same researcher as well as in social psychology in general (“some researchers are calling Ariely’s large body of work into question”; O’Grady, 2021).
The brouhaha about the discovery of fraud is understandable because fraud is widely considered an unethical behavior that violates standards of academic integrity that may end a career (e.g., Stapel). However, there are many other reasons to be suspect of the credibility of Dan Ariely’s published results and those by many other social psychologists. Over the past decade, strong scientific evidence has accumulated that social psychologists’ research practices were inadequate and often failed to produce solid empirical findings that can inform theories of human behavior, including dishonest ones.
Arguably, the most damaging finding for social psychology was the finding that only 25% of published results could be replicated in a direct attempt to reproduce original findings (Open Science Collaboration, 2015). With such a low base-rate of successful replications, all published results in social psychology journals are likely to fail to replicate. The rational response to this discovery is to not trust anything that is published in social psychology journals unless there is evidence that a finding is replicable. Based on this logic, the discovery of fraud in a study published in 2012 is of little significance. Even without fraud, many findings are questionable.
Questionable Research Practices
The idealistic model of a scientist assumes that scientists test predictions by collecting data and then let the data decide whether the prediction was true or false. Articles are written to follow this script with an introduction that makes predictions, a results section that tests these predictions, and a conclusion that takes the results into account. This format makes articles look like they follow the ideal model of science, but it only covers up the fact that actual science is produced in a very different way; at least in social psychology before 2012. Either predictions are made after the results are known (Kerr, 1998) or the results are selected to fit the predictions (Simmons, Nelson, & Simonsohn, 2011).
This explains why most articles in social psychology support authors’ predictions (Sterling, 1959; Sterling et al., 1995; Motyl et al., 2017). This high success rate is not the result of brilliant scientists and deep insights into human behaviors. Instead, it is explained by selection for (statistical) significance. That is, when a result produces a statistically significant result that can be used to claim support for a prediction, researchers write a manuscript and submit it for publication. However, when the result is not significant, they do not write a manuscript. In addition, researchers will analyze their data in multiple ways. If they find one way that supports their predictions, they will report this analysis, and not mention that other ways failed to show the effect. Selection for significance has many names such as publication bias, questionable research practices, or p-hacking. Excessive use of these practices makes it easy to provide evidence for false predictions (Simmons, Nelson, & Simonsohn, 2011). Thus, the end-result of using questionable practices and fraud can be the same; published results are falsely used to support claims as scientifically proven or validated, when they actually have not been subjected to a real empirical test.
Although questionable practices and fraud have the same effect, scientists make a hard distinction between fraud and QRPs. While fraud is generally considered to be dishonest and punished with retractions of articles or even job losses, QRPs are tolerated. This leads to the false impression that articles that have not been retracted provide credible evidence and can be used to make scientific arguments (studies show ….). However, QRPs are much more prevalent than outright fraud and account for the majority of replication failures, but do not result in retractions (John, Loewenstein, & Prelec, 2012; Schimmack, 2021).
The good news is that the use of QRPs is detectable even when original data are not available, whereas fraud typically requires access to the original data to reveal unusual patterns. Over the past decade, my collaborators and I have worked on developing statistical tools that can reveal selection for significance (Bartos & Schimmack, 2021; Brunner & Schimmack, 2020; Schimmack, 2012). I used the most advanced version of these methods, z-curve.2.0, to examine the credibility of results published in Dan Ariely’s articles.
Data
To examine the credibility of results published in Dan Ariely’s articles I followed the same approach that I used for other social psychologists (Replicability Audits). I selected articles based on authors’ H-Index in WebOfKnowledge. At the time of coding, Dan Ariely had an H-Index of 47; that is, he published 47 articles that were cited at least 47 times. I also included the 48th article that was cited 47 times. I focus on the highly cited articles because dishonest reporting of results is more harmful, if the work is highly cited. Just like a falling tree may not make a sound if nobody is around, untrustworthy results in an article that is not cited have no real effect.
For all empirical articles, I picked the most important statistical test per study. The coding of focal results is important because authors may publish non-significant results when they made no prediction. They may also publish a non-significant result when they predict no effect. However, most claims are based on demonstrating a statistically significant result. The focus on a single result is needed to ensure statistical independence which is an assumption made by the statistical model. When multiple focal tests are available, I pick the first one unless another one is theoretically more important (e.g., featured in the abstract). Although this coding is subjective, other researchers including Dan Ariely can do their own coding and verify my results.
Thirty-one of the 48 articles reported at least one empirical study. As some articles reported more than one study, the total number of studies was k = 97. Most of the results were reported with test-statistics like t, F, or chi-square values. These values were first converted into two-sided p-values and then into absolute z-scores. 92 of these z-scores were statistically significant and used for a z-curve analysis.
Z-Curve Results
The key results of the z-curve analysis are captured in Figure 1.
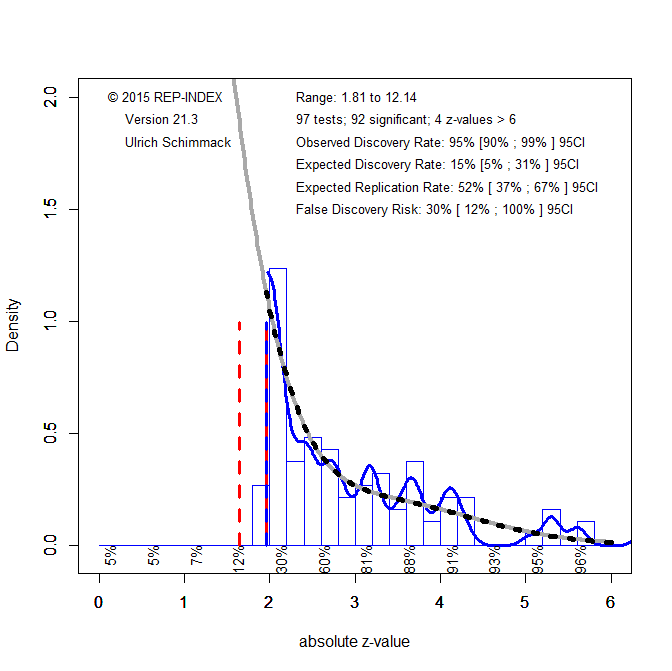
Visual inspection of the z-curve plot shows clear evidence of selection for significance. While a large number of z-scores are just statistically significant (z > 1.96 equals p < .05), there are very few z-scores that are just shy of significance (z < 1.96). Moreover, the few z-scores that do not meet the standard of significance were all interpreted as sufficient evidence for a prediction. Thus, Dan Ariely’s observed success rate is 100% or 95% if only p-values below .05 are counted. As pointed out in the introduction, this is not a unique feature of Dan Ariely’s articles, but a general finding in social psychology.
A formal test of selection for significance compares the observed discovery rate (95% z-scores greater than 1.96) to the expected discovery rate that is predicted by the statistical model. The prediction of the z-curve model is illustrated by the blue curve. Based on the distribution of significant z-scores, the model expected a lot more non-significant results. The estimated expected discovery rate is only 15%. Even though this is just an estimate, the 95% confidence interval around this estimate ranges from 5% to only 31%. Thus, the observed discovery rate is clearly much much higher than one could expect. In short, we have strong evidence that Dan Ariely and his co-authors used questionable practices to report more successes than their actual studies produced.
Although these results cast a shadow over Dan Ariely’s articles, there is a silver lining. It is unlikely that the large pile of just significant results was obtained by outright fraud; not impossible, but unlikely. The reason is that QRPs are bound to produce just significant results, but fraud can produce extremely high z-scores. The fraudulent study that was flagged by datacolada has a z-score of 11, which is virtually impossible to produce with QRPs (Simmons et al., 2001). Thus, while we can disregard many of the results in Ariely’s articles, he does not have to fear to lose his job (unless more fraud is uncovered by data detectives). Ariely is also in good company. The expected discovery rate for John A. Bargh is 15% (Bargh Audit) and the one for Roy F. Baumester is 11% (Baumeister Audit).
The z-curve plot also shows some z-scores greater than 3 or even greater than 4. These z-scores are more likely to reveal true findings (unless they were obtained with fraud) because (a) it gets harder to produce high z-scores with QRPs and replication studies show higher success rates for original studies with strong evidence (Schimmack, 2021). The problem is to find a reasonable criterion to distinguish between questionable results and credible results.
Z-curve make it possible to do so because the EDR estimates can be used to estimate the false discovery risk (Schimmack & Bartos, 2021). As shown in Figure 1, with an EDR of 15% and a significance criterion of alpha = .05, the false discovery risk is 30%. That is, up to 30% of results with p-values below .05 could be false positive results. The false discovery risk can be reduced by lowering alpha. Figure 2 shows the results for alpha = .01. The estimated false discovery risk is now below 5%. This large reduction in the FDR was achieved by treating the pile of just significant results as no longer significant (i.e., it is now on the left side of the vertical red line that reflects significance with alpha = .01, z = 2.58).

With the new significance criterion only 51 of the 97 tests are significant (53%). Thus, it is not necessary to throw away all of Ariely’s published results. About half of his published results might have produced some real evidence. Of course, this assumes that z-scores greater than 2.58 are based on real data. Any investigation should therefore focus on results with p-values below .01.
The final information that is provided by a z-curve analysis is the probability that a replication study with the same sample size produces a statistically significant result. This probability is called the expected replication rate (ERR). Figure 1 shows an ERR of 52% with alpha = 5%, but it includes all of the just significant results. Figure 2 excludes these studies, but uses alpha = 1%. Figure 3 estimates the ERR only for studies that had a p-value below .01 but using alpha = .05 to evaluate the outcome of a replication study.

In Figure 3 only z-scores greater than 2.58 (p = .01; on the right side of the dotted blue line) are used to fit the model using alpha = .05 (the red vertical line at 1.96) as criterion for significance. The estimated replication rate is 85%. Thus, we would predict mostly successful replication outcomes with alpha = .05, if these original studies were replicated and if the original studies were based on real data.
Conclusion
The discovery of a fraudulent dataset in a study on dishonesty has raised new questions about the credibility of social psychology. Meanwhile, the much bigger problem of selection for significance is neglected. Rather than treating studies as credible unless they are retracted, it is time to distrust studies unless there is evidence to trust them. Z-curve provides one way to assure readers that findings can be trusted by keeping the false discovery risk at a reasonably low level, say below 5%. Applying this methods to Ariely’s most cited articles showed that nearly half of Ariely’s published results can be discarded because they entail a high false positive risk. This is also true for many other findings in social psychology, but social psychologists try to pretend that the use of questionable practices was harmless and can be ignored. Instead, undergraduate students, readers of popular psychology books, and policy makers may be better off by ignoring social psychology until social psychologists report all of their results honestly and subject their theories to real empirical tests that may fail. That is, if social psychology wants to be a science, social psychologists have to act like scientists.