Meta-science is not some special science or Über-science. It works just like other science, and in psychology it means that it is not working very well. The biggest problem is that theoretical or statistically oriented research means are subject to the same capitalistic pressure to produce output that can be measured and contributes to GDP by selling their work to publishers, who earn profits, which makes research workers work at least economically valuable. I mean, most of have tenure and could spend the time we are not doing our paid job (teaching) to go sailing, play tennis, but for some reason, some engage in meaningless pseud-scientific work and flood scientific journals with garbage and waste other people’s time to read their garbage instead of playing tennis. In sort, I am frustrated, and here is why.
I am looking for articles that discuss Vevea’s random effects selection model implemented in the r-package weightr. This summer I found that this is the best way to conduct effect -size meta-analyses in psychology because it models heterogeneity in effect sizes across conceptual replication studies and models selection bias that is pretty much always present in psychology.
This is how I found the article “Effect Size Estimation From t-Statistics in the Presence of
Publication Bias” by Ulrich, Miller, and Erdfelder. I once contacted Ulrich about z-curve, but he was not intersted. Erdfelder was behind G*Power and deserves credit for this free program that helped me to understand power back in 2013.
The article is a long and boring review of different methods to correct for publication bias in effect size estimation. The main point of this review is only to conclude that they all suck and that this is the reason why they developed their own model.
“In sum, all of these approaches are either highly complex or make strong and somewhat implausible assumptions about the weight functions, thus calling for an alternative approach that is based on weaker and more flexible assumptions but still relies on a simple selection model with clear-cut interpretations of the parameters. This motivated our own approach presented in the following section”
Then follows a long introduction of their model with lots of formulas and figures that make it look really, really scientific, and probably scared the shit out of the reviewers at “Zeitschrift für Psychologie,” where this nonsense was published after it was probably rejected from serious method journals.
The “new” model is a simple fixed effects model that assumes all studies have the same population effect size. This makes the model as useless as p-curve or p-uniform the analysis of most real datasets in psychology that typically have a high amount of heterogeneity. Any article with headings like “Maximum Likelihood Estimation of True Effect Size” is not worse reading because there is no True Effect Size in psychology. The only scenario that works well for a fixed effects model is a set of studies where all studies have no effect and significant results were obtained with p-hacking. When there are real effects, they are not all the same across studies. At a minimum, a test of heterogeneity should be conducted before a fixed-effects model is used.
To show how good their new method is, they apply it to a meta-analysis by Shanks et al. 2015) of priming studies. Priming studies are prime candidates for finding no effect and a lot of p-hacking. Their new, super-duper, so much better model estimated a TRUE EFFECT SIZE of d = .44, 95%CI = .31 to .57. Wow, priming works. We were all wrong and should apologize to Bargh. Maybe Einstein primes also make people really smarter. Where is the barf emoji in wordpress?
Of course, they do not compare the result to other methods, which is often recommended because “no method works well in all circumstances,” (Carter et al., 2018), but hey their review showed the other methods suck, so why bother. Fortunately, the Shanks data are openly available (really open data sharing is the best that has come out of the replication crisis), and I can present the results.
Let’s start with the default random-effects selection model implemented in weightr. This model is called the 3PSM model because it has 3 parameters to estimate selection bias at p < .05 (two-sided), the mean and standard deviation of the population effect sizes (i.e., without sampling error).
There is surprisingly little heterogeneity. The standard deviation of effect sizes is estimated to be .09. Thus, 95% of effect sizes are assumed to be either .2 standard deviations above or below the mean. The mean is estimated at d = .44. Thus, the 95%CI is d = .33 to .55. Maybe that is why Ulrich and co did not report model comparisons. Who needs a new model if the old model works just fine. No publication. Where is the crying face emoji?
But it gets better. Many of the non-significant effect sizes are marginally significant and were reported as evidence against the null-hypothesis. We can model this with the random effects selection model by adding a step at p = .05 (p = .10, two-sided is typically the upper value to get away with marginal significance). Indeed, 8 non-significant results are marginal and only 2 are not, because they are marginally-marginally significant. With a small dataset it is difficult to estimate multiple parameters. One way to deal with marginally significant results, would be to fit the model only to “significant” results. Another one is to lower the significance criterion to treat marginal results as significant. All p-values were below p = .14, two-sided. So, I set the significance criterion to .14. In this model, the mean was d = .27, 95% CI = .18 to .36. Using only the results with p-values below .025 (one-sided) produced an estimate of d = .33, 95%CI = .22 to .44.
In short, the article fails to show that the new model is needed or better than previous models. In fact, it is worse because it does not estimate heterogeneity in effect sizes. This is not a major problem for the application to Shank’s priming data, but it would be a problem for other meta-analyses. Using a fixed effect size model with heterogenous data is scientific malpractice and leads to the wrong conclusions.
But what do we do with priming? Should we really believe that priming works in these studies? How robust are these results? Could they be replicated. With most sample sizes below N = 100, effect sizes in a single study are inflated and correction models can do only so much to estimate the true values.
Another way to look at these data is to use z-curve. Being generous, we simply compute the ratio of effect sizes over sampling error and use the t-values as if they were z-values. This produces an upward bias in studies with small samples.
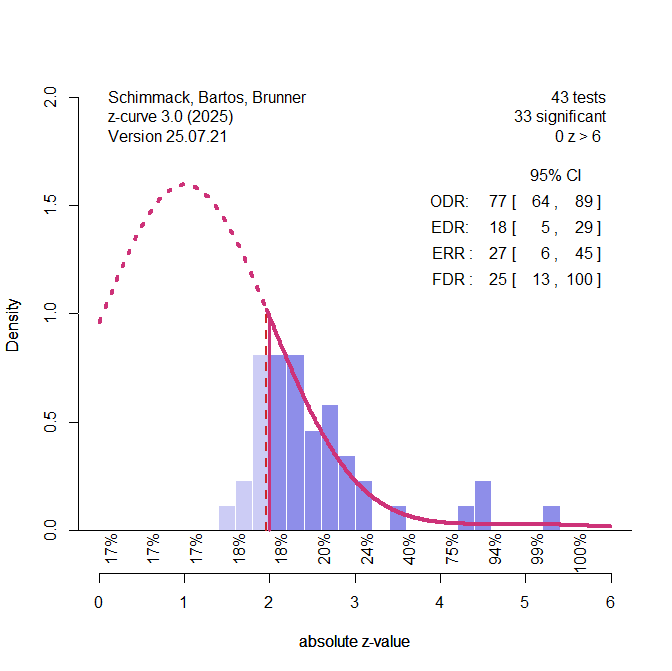
Z-curve makes it clear that non-significant results (left side of 1.96) are clustered just below the criterion for significance. Treating these observations as honestly reported non-significant results would be a mistake and create upward bias in effect size estimates. It also shows that most significant values are clustered close to the value for significance. This suggests p-hacking. Based on this distribution of effect sizes, the model assumes that many more priming studies were conducted, but not reported because they failed to show support for priming. The expected discovery rate of all studies would be only 18% significant results, but this estimate is uncertain and it could be as many as 29% or as little as 5%. Because 5% is expected by chance alone, the false positive risk is 100%. That is, we cannot rule out that all of these results were obtained without a real effect, which is not implausible when we look at priming studies.
The local power estimates below the x-axis also show that even studies with a z-value of 3 (observed power > 80%) have only 24% power to show a significant effect again. The only studies worthwhile to follow up on are 3 results with z > 4, but I would not bet money on these results to replicate successfully. After all, it is priming research.
Ok, now it is time to go and play tennis and have some fun. I am not getting paid enough to spend more time on this shit, but maybe somewhere I can save some people from wasting time on this article or other articles by authors with such a low degree of trustworthiness. If you care about effect–size meta-analysis, read some tutorials on weightr. It is the best program we have so far.