In this series of blog posts, I am reexamining Carter et al.’s (2019) simulation studies that tested various statistical tools to conduct a meta-analysis. The reexamination has three purposes. First, it examines the performance of methods that can detect biases to do so. Second, I examine the ability of methods that estimate heterogeneity to provide good estimates of heterogeneity. Third, I examine the ability of different methods to estimate the average effect size for three different sets of effect sizes, namely (a) the effect size of all studies, including effects in the opposite direction than expected, (b) all positive effect sizes, and (c) all positive and significant effect sizes.
The reason to estimate effect sizes for different sets of studies is that meta-analyses can have different purposes. If all studies are direct replications of each other, we would not want to exclude studies that show negative effects. For example, we want to know that a drug has negative effects in a specific population. However, many meta-analyses in psychology rely on conceptual replications with different interventions and dependent variables. Moreover, many studies are selected to show significant results. In these meta-analyses, the purpose is to find subsets of studies that show the predicted effect with notable effect sizes. In this context, it is not relevant whether researchers tried many other manipulations that did not work. The aim is to find the one’s that did work and studies with significant results are the most likely ones to have real effects. Selection of significance, however, can lead to overestimation of effect sizes and underestimation of heterogeneity. Thus, methods that correct for bias are likely to outperform methods that do not in this setting.
I focus on the selection model implemented in the weightr package in R because it is the only tool that tests for the presence of bias and estimates heterogeneity. I examine the ability of these tests to detect bias when it is present and to provide good estimates of heterogeneity when heterogeneity is present. I also use the model result to compute estimates of the average effect size for all three sets of studies (all, only positive, only positive & significant).
The second method is PET-PEESE because it is widely used. PET-PEESE does not provide conclusive evidence of bias, but a positive relationship between effect sizes and sampling error suggests that bias is present. It does not provide an estimate of heterogeneity. It is also not clear which set of studies are the target of this method. Presumably, it is the average effect size of all studies, but if very few negative results are available, the estimate overestimates this average. I examine whether it produces a more reasonable estimate of the average of the positive results.
P-uniform is included because it is similar to the widely used p-curve method,but has an r-package and produces slightly superior estimates. I am using the LN1MINP method that is less prone to inflated estimates when heterogeneity is present. P-uniform assumes selection bias and provides a test of bias. It does not test heterogeneity. Importantly, p-uniform uses only positive and significant results. It’s performance has to be evaluated against the true average effect size for this subset of studies rather than all studies that are available. It does not provide estimates for the set of only positive results (including non-significant ones) or the set of all studies, including negative results.
Finally, I am using these simulations to examine the performance of z-curve.2.0 (Bartos & Schimmack, 2022). Using exactly the simulations that Carter et al. (2019) used prevents me from simulation hacking; that is, testing situations that show favorable results for my own method. I am testing the performance of z-curve to estimate average power of studies with positive and significant results and the average power of all positive studies. I then use these power estimates to estimate the average effect size for these two sets of studies. I also examine the presence of publication bias and p-hacking with z-curve.
This blog post examines a rather simple, but important scenario. It assumes that all studies tested a true null hypothesis (i.e., there is no real effect), but high selection bias produces a lot of significant results. Carter et al. (2019) found that this scenario produced problems for the default selection model (3PSM) and that it often falsely rejected the null hypothesis; that is, the selection model had a high type-I error rate. On the other hand, this scenario should be easy for p-uniform and z-curve because they rely only on the significant results and the distribution of p-values or z-scores generated by true null-hypothesis is easy to detect.
Simulation
I focus on a sample size of k = 100 studies to examine the properties of confidence intervals with a large, but not unreasonable set of studies. Smaller sets of studies may benefit the selection model because wider confidence intervals are less likely to produce false positive results. In this scenario, the true population effect size is zero for any set of studies because it is zero in every study.
Figure 1 shows the distribution of the effect size estimates (extreme values below d = 1.2 and above d = 2 are excluded). Selection bias leaves mostly positive results. The presence of some negative results can be explained by the fact that the selection simulation kept negative and statistically significant results.
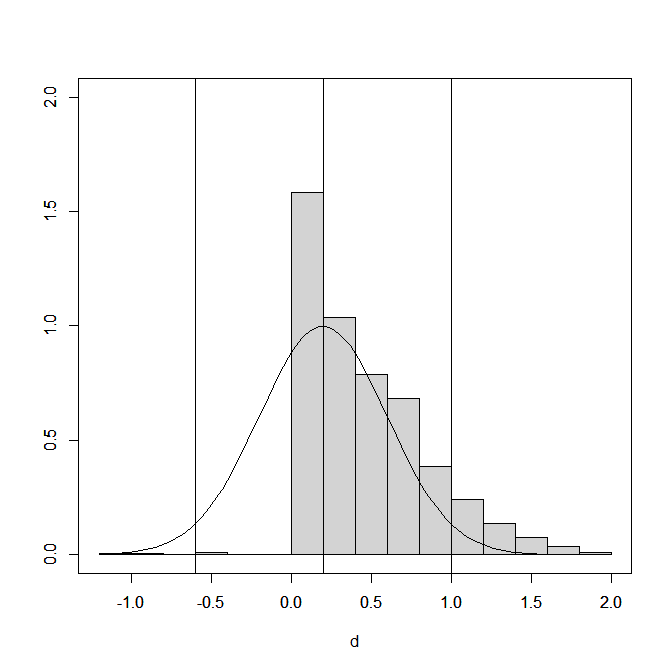
Histograms of effect sizes do not show the proportion of significant and non-significant results. This can be examined by computing the ratio of effect sizes over sampling error and treat these as approximate z-scores. Alternatively, the sample sizes can be used to compute t-values, and use the corresponding p-values to convert t-values into z-values.
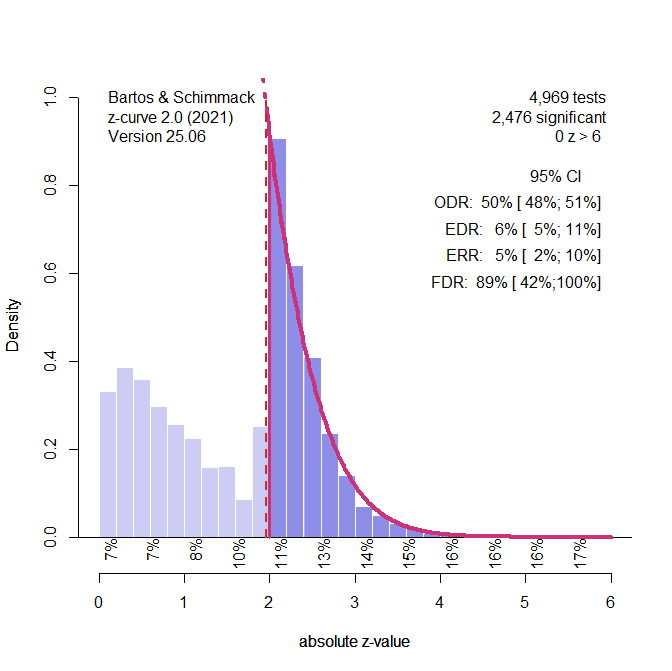
Figure 2 shows the plot of the z-values and the analysis of the z-values with z-curve, using the standard selection model that fits the model to all statistically significant z-values. The plot shows clear evidence of selection bias. Z-curve’s estimate of average power for the significant results is 5% (compared to the true value of 2.5% because the ERR takes the sign of replication results into account). The confidence interval includes the true value of 2.5%. Thus, the model does not reject the null hypothesis that all significant results are false positive results. The estimated average power for all positive results (i.e., the expected discovery rate, EDR) is estimated at 6%, while the true value is 5%. The 95%CI includes the true value. Incidentally, z–curve uses this result to estimate that 89% of the significant results are false positives, but the confidence interval includes the true value of 100%.
The simulation study shows the performance of z-curve with just 100 studies and a much smaller set of significant results that are used for model fitting. This will only widen the CI and is unlikely to change the result that z-curve performs well in this scenario.
Model Specifications
The specification of the z-curve model was explained and justified above.
Carter et al. (2019) observe conversion issues with the default (3PSM) selection model in some conditions. This is one of these conditions. However, the problem is that the 3PSM model assumes heterogeneity and has problems when all population effect sizes are the same. This does not mean that selection models cannot be used with those data. A solution is to test the random model and when it fails to run the fixed effects model. I used this approach and obtained usable results in all simulations.
The specification of the selection model remains the same as in the previous simulations and differed from Carter et al.’s default 3PSM model. First, I added steps to model different selection for positive and negative results. Second, I added a step to allow for different selection of non-significant and significant negative results. Third, I added a step to identify p-hacking that produces too many just significant results. The range of just significant results was defined as p-values between .05 and .01, two-sided. The one-sided p-value steps are c(.005,.025,.050,.500,.975).
P-uniform and PET-PEESE do not require thinking and were used as usual.
Selection Model (weightr)
The random-effects model failed to converge in 42% of the simulations. Actually, this is the better result because it implies zero heterogeneity, which is actually the true heterogeneity. In the other 58% of the cases, the random effects model estimated non-zero heterogeneity.
Selection bias should produce fewer non-significant than significant positive results. The average selection weight for non-significant positive results was .17, average 95%CI = .12 to .22, and 99% of confidence intervals did not include a value of 1. Thus, the model was able to detect selection bias in a set of 100 studies.
The average selection weight for p-values between .005 and .025 (one-sided) was 2.02, average 95%CI = 1.08, to 2.93, and 44% of CI did not include a value of 1. This means that the model falsely detected p-hacking in 44% of the simulations. Thus, the p-hacking test is not reliable in this condition. The reason will become clear in the next analysis of the effect size estimates.
The average estimate of the mean population effect size was d = .07, average 95%CI = .04 to .10, and only 11% of confidence intervals included the true value of 0. This finding replicates Carter et al.’s (2019) finding that the selection model has a high false positive risk in this scenario. At the same time, the bias in the effect size estimates is small and the model correctly estimates that the true effect size is less than small (d < .20). Only 4% of confidence intervals included a value of .2.
When the random-effect model converged, it produced an average estimate of heterogeneity close to zero, tau = .01, 95%CI = .00 to .07, and 100% of confidence intervals included a value of 0. Based on this result, the model could be respecified as a fixed-effects model, but the small amount of heterogeneity did not affect estimates for subsets of studies with positive or positive and significant results. That is, when there is no heterogeneity, all subsets of population effect sizes have the same value. The problem for the selection model was that it overestimated this value slightly with overconfidence and therefore rejected the true null hypothesis in many simulations. This small bias gives other models an opportunity to outperform the selection model.
PET-PEESE
PET regresses effect sizes on the corresponding sampling errors. The average estimate was d = .00, average 95%CI = .-.06 to .06, and 91% of the confidence intervals included the true value of zero. PEESE regresses the effect sizes on the sampling variance (i.e., the squared sampling error). PEESE overestimates the true average effect size even more, average estimated d = .13, average 95%CI = .08 to .17, and none of the confidence intervals included the true value. The overestimation of PEESE is not a problem when PET produces a non-significant result because the PET-PEESE rules state that the PET estimate should be used when PET is not significant. However, PET produced 9% false positives and in this case, the PEESE result would be used and lead to an overestimation. This is still better performance than the selection model, but other models might avoid the false positive problem of PET-PEESE.
P-Uniform
P-uniform also has a bias test, but it detected bias in only 73% of the simulations. Thus, the selection model has a better bias test. The average effect size estimate was d = .03, average 95%CI = -.30 to .21, and 96% of the confidence intervals included the true value of 0. Thus, p-uniform beats the selection model and PET-PEESE in this scenario. .
Z-Curve
One way to test selection bias with z-curve is to fit the model to all positive results, non-significant and significant results, and to test for the presence of excessive just significant results (z = 2 to 2.6 ~ p = .05 to .01). This test was significant in 99% of all simulations. This is as good as the bias test with the selection model and better than the bias test of p-uniform.
The p-hacking test fits the model to the “really” significant results (z > 2.6) and compares the frequency of just significant results to the predicted frequency. In this scenario, the test could not be used because there were too few “really” significant results (see Figure 2).
The average estimate of the average power of the positive and significant results was 7%, average 95%CI = 2.5% to 17%, and all confidence intervals included the true value of 2.5%. The estimate for the average power of all positive results was 6%, average 95%CI = 5% to 17%, and all confidence intervals included the true value of 5%. Thus, z-curve correctly showed that the simulated studies lacked evidential value, a term to state that we cannot reject the null hypothesis that the null hypothesis was true in all studies.
Converting the power estimates into effect size estimates, z-curve estimated an average effect size for positive and significant results of d = .10, average 95%CI = .00 to .27, and all confidence intervals included the true value of zero. The same result was obtained for the set of studies with positive results.
Conclusion
The main conclusion from this specific simulation study is that the selection model had an unacceptably high false positive rate. This finding replicates Carter et al.’s (2019) results. I also replicated the convergence problem when the model was specified as a random-effects model. However, I was able to fix this problem by using a fixed effects model. Moreover, the effect size estimate of the selection model had only a small positive bias. The model also correctly detected selection bias, but overestimated p-hacking. Thus, the selection model did not perform badly, but it showed some problems in this scenario.
All other methods did better in correcting for selection bias and showing that the 100 studies in a simulation were produced without a real effect. The best performance was obtained with z-curve, which also showed clear evidence of selection bias.
These results do confirm Carter et al.’s (2019) conclusion that no single method performs best in all situations. However, this does not mean that methods can produce wildly different results. The selection model only showed a small positive bias, and other methods showed that the data lacked evidential value.
This is very different from Carter et al.’s (2019) meta-analysis of the ego-depletion literature, where only PET-PEESE suggested lack of evidential value, but the selection model and p-curve suggested that at least some studies had moderate positive effect sizes. Given the present simulation results, it would be questionable to accept the PET-PEESE results and dismiss the results of the other methods, especially the selection model. The selection model performs well when studies have evidential value and shows only a small bias in this simulation. Thus, an average effect size estimate of d = .3 is unlikely to be a bias and it is more likely that the PET result is an underestimation of the true average effect.
Although I have carefully avoided promoting z-curve so far, I do believe that this simulation shows the value of complementing effect size meta-analysis with the selection model with a z-curve analysis of power. Taken both methods together, researchers would correctly infer that the data do not have evidential value and that all studies could have been obtained without a true effect in any one of the studies. As I am one of the parents of z-curve, this advice should be taken with a grain of salt, but there is little harm in adding one more method to a multiverse meta-analysis and to show that all methods produce robust evidence that the data under investigation are far from robust.