Introductory Rant
The ideal model of science is that scientists are well-paid with job security to work collaboratively towards progress in understanding the world. In reality, scientists operate like monarchs in the old days or company CEO’s in the modern world. They try to expand their influence as much as possible. This capitalistic model of science could work if there was a market that rewards CEO’s of good companies for producing better products at a cheaper price. However, even in the real world, markets are never perfect. In science, there is no market and success is much more driven by many factors that have nothing to do with the quality of the product.
The products of empirical scientists often contain a valuable novel contribution, even if the overall product is of low quality. The reason is that empirical psychologists often collect new data. Even this contribution can be useless when the data are not trustworthy, as the replication crisis in social psychology has shown. However, often data are interesting and when shared can benefit other researchers. Scientists who work in non-empirical fields (e.g., mathematicians, philosophers, statisticians) do not have that advantage. Their products are entirely based on their cognitive abilities. Evidently, it is much easier to find some new data, then to come up with a novel idea. This creates a problem for non-empirical scientists because it is a lot harder to come up with an empire-expanding novel idea. This can be seen by the fact that the most famous philosophers are still Plato and Aristoteles and not some modern philosopher. It can also be seen by the fact that it is hard for psychometricians to compete with empirical researchers for attention and jobs. Many psychology departments have stopped hiring psychometricians because empirical researchers often add more to the university rankings. Case in point, my own university, including all three campuses, is one of the largest departments in the world and does not have a formally trained psychometrician. Thus, my criticism of psychometricians should not be seen as a personal attack. Their unhelpful behaviors can be attributed to a reward structure that rewards unhelpful behaviors, just like Skinner would have predicted on the basis of their reward schedule.
Measurement Models without Substance
A key problem for psychometricians is that they are not rewarded for helping empirical psychologists who work on substantive questions. Rather, they have to make contributions to the field of psychometrics. To have a big impact, it is therefore advantages to develop methods that can be used by many researchers who work on different research questions. This is like ready-to-wear clothing. The empirical researcher just needs to pick a model and plug the data into the model and the truth comes out at the other end. Many readers will realize that ready-to-wear clothing has its problems. Mainly, it may not fit your body. Similarly, a ready-to-use statistical model may not fit a research question, but users of statistical models who are not trained in statistics may not realize this and psychometricians have no interest in telling them that their model is not appropriate. As a result, we see many articles that uncritically use statistical models that are applied to the wrong data. To avoid this problem, psychometricians would have to work with empirical researchers like tailors who create custom -fitted clothing. This would produce high-quality work, but not the market influence and rewards that read-to-wear companies can make.
Don’t take my word for it. The most successful contemporary psychometrician said so himself.
“The founding fathers of the Psychometric Society—scholars such as Thurstone, Thorndike, Guilford, and Kelley—were substantive psychologists as much as they were psychometricians. Contemporary psychometricians do not always display a comparable interest with respect to the substantive field that lends them their credibility. It is perhaps worthwhile to emphasize that, even though psychometrics has benefited greatly from the input of mathematicians, psychometrics is not a pure mathematical discipline but an applied one. If one strips the application from an applied science one is not left with very much that is interesting; and psychometrics without the “psycho” is not, in my view, an overly exciting discipline. It is therefore essential that a psychometrician keeps up to date with the developments in one or more subdisciplines of psychology.“ (Borsboom, 2006)
Borsboom has carefully avoided his own advice and became a rock-star for his claims that the founding people of psychometrics were all delusional because they actually believed in substances that could be measured (traits) and developed methods to measure intelligence, personality, or attitudes. Borsboom declared that personality does not exist and the tools that are used to claim they exist like factor analysis are false, and the way researchers present evidence for the existence of psychological substances outlined by two more founding psychometricians (Cronbach & Meehl, 1955) was false. Few psychometricians who gave him an award realized that his Attack of the Psychometricians (Borsboom, 2006) was really an attack of one ego-maniac psychometrician on the entire field. Despite Borsboom’s fame as measured by citations, his attack is largely ignored by substantive researchers who couldn’t care less about somebody who claims their topic of study is just a figment of imagination without any understanding of the substantive area that is being attacked.
A greater problem are psycho-metricians who market statistical tools that applied researchers actually use without understanding them. And that is what this blog-post is really about. So, end of ranting and on to showing how psychometrics without substance can lead to horribly wrong results.
Michael Eid’s Truth Factor
Psychometrics is about measurement and psychological measurement is not different from measurement in other disciplines. First, researchers assume that the world we live in (reality) can be described and understood with models of the world. For example, we assume that there is something real that makes us sometimes sweat, sometimes wear just a t-shirt, and sometimes wear a thick coat. We call this something temperature. Then we set out to develop instruments to measure variation in this construct. We call these instruments thermometers. The challenging step in the development of thermometers is to demonstrate that they measure temperature and that they are good measures of temperature. This step is called validation of a measure. A valid measure measures what it is supposed to measure and nothing else. The natural sciences have made great progress by developing better and better measures of constructs we all take for granted in everyday life like temperature, length, weight, time, etc. (Cronbach & Meehl, 1955). To make progress, psychology would also need to develop better and better measures of psychological constructs such as cognitive abilities, emotions, personality traits, attitudes, and so on.
The basic statistical tool that psychometricians developed to examine validity of psychological measures is factor analysis. Although factor analysis has developed and has become increasingly easy and cheap with the advent of powerful personal computers, the basic idea of factor analysis has remained the same. Factor analysis relates observed measures to unobserved variables that are called factors and estimates the strength of the relationship between the observed variable and the unobserved variable to provide information about the variance in a measure that is explained by a factor. Variance explained by the factor is valid variance if the factor represents the construct that a researcher wanted to measure. Variance that is not explained by a factor represents measurement error. The key problem for substantive researchers is that a factor may not correspond to the construct that they were trying to measure. As a result, even if a factor explains a lot of the variance in a measure, the measure could be a poor measure of a construct. As a result, the key problem for validation research is to justify the claim that a factor measures what it is assumed to measure.
Welcome to Michael Eid’s genius short-cut to the most fundamental challenge in psychometrics. Rather than conducting substantive research to justify the interpretation of a factor, researchers simply declare one measure as a valid measure of a construct. You may thin, surely, I am pulling wool over your eyes and nobody could argue that we can validate measures by declaring them to be valid. So, let me provide evidence for my claim. I start with Eid, Geiser, Koch, and Heene’s (2017) article that is built on the empire-expanding claim that all previous applications of another empire-expanding model called the bi-factor model, are false and that researchers need to use the authors model. This article is flagged as highly-cited in WebofScience showing that this claim has struck fear in applied researchers who were using the bi-factor model.
One problem for applied researchers is that psychometricians are trained in mathematics and use mathematical language in their articles which makes it impossible for applied researchers to understand what they are saying. For example, it would take me a long time to understand what this formula in Eid et al.’s article tries to say.
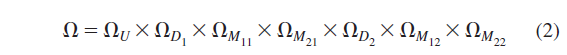
Fortunately, psychometricians have also developed a simpler language to communicate about their models that uses figures with just four elements that are easy to understand. Boxes represent measured variables where we have actual scores of people in a sample. Circles are unobserved variables where we do not have scores of individuals. Straight and directed arrows imply a causal effect. The key goal of a measurement model is to estimate parameters that show how strong these causal effects are. Finally, there are also curved and undirected paths that reflect a correlation between two variables without assuming causality. This simple language makes it possible for applied researchers to think about the statistical model that they are using to examine validity of their measures. Eid et al.’s Figure 1 shows the bi-factor models they criticize with an example of several cognitive tasks that were developed to measure general intelligence. In this model, general intelligence is an unobserved variable (g). Nothing in the bi-factor model tells us whether this factor really measures intelligence. So, we can ignore this hot-button issue and focus on the question that the bi-factor model actually can answer. Are the tasks that were developed to measure the g-factor good measures of the g-factor. To be a good measure, a measure has to be strongly related to the g-factor. Thus, the key information that applied researchers care about are the parameter estimates for the directed paths from the g-factor to the 9 observed variables. Annoyingly, psychometricians use Greek letters to refer to these parameters. An English term is factor loadings and we could just use L for loading to refer to these parameters, but psychometricians feel more like scientists when they use the Greek letter lambda.

But how can we estimate the strength of an unobserved variable on an observed variable? This sounds like magic or witch craft and some people have argued that factor analysis is fundamentally flawed and produces illusory causal effects of imaginary substances. In reality, factor analysis is based on the simple fact that causal process produce correlations. If there are really people who are better at cognitive tasks, they will do better one different tasks, just like athletic people are likely to do better on several different sports. Thus, a common cause will produce correlations between two effects. You may remember this from PSY100 where this is introduced as the third-variable problem. The correlation between height and hair-length (churches and murder rates, etc.) does not reveal a causal effect of height on hair-length or vice versa. Rather, it is produced by a common cause. In this case, gender explains most of the correlation between height and hair-length because men tend to be taller and tend to have shorter hair, producing a negative correlation. Measurement models use the relationship between correlation and causation to infer the strength of common causes on the basis of the strength of correlations among the observed variables. To do so, they assume that there are no direct causal effects of one measure on another. That is, just because we measured your temperature under your arm pits before we measured it in your ear and moth, does not produce correlations among the three measures of temperature. This assumption is represented in the Figure by the fact that there are no direct relationships among the observed variables. The correlations merely reflect common causes and when three measures of temperature are strongly correlated, it suggests that they are all measuring the same common cause.
A simple model of g might assume that performance on a cognitive measure is influenced by only two causes. One is the general ability (g) that is represented by the directed arrow from g to the variable that represents variation in a specific task and another due to factors that are unique to this measure (e.g., some people are better at verbal tasks than others). This variance that is unique to a variable is often omitted from figures, but is part of the model in Figure 1.
The problem with this model is that it often does not fit the data. Cognitive performance does not have a simple structure. This means that some measures are more strongly correlated than a model with a single g-factor predicts. Bi-factor models model these additional relationships among measures with additional factors. They are called S1, S2, and S3 (thank god, they didn’t call them sigma or some other Greek name) and S stands for specific. So, the model implies that participants’ scores on a specific measure are caused by three factors: the general factor (g), one of the three specific factors (S1, S2, or S3), and a factor that is unique to a specific measure. The model in Figure 1 is simplistic and may still not fit the data. For example, it is possible that some measures that are mainly influenced by S2 are also influenced a bit by S1 and S3. However, these modifications are not relevant for our discussion, and we can simply assume that the model in Figure 1 fits the data reasonably well.
From a substantive perspective, it seems plausible that two cognitive measures could be influenced by a general factor (e.g., some students do better in all classes than others) and some specific factors (e.g., some students do better in science subjects). So, while the bi-factor model is not automatically the correct model, it would seem strange to reject it a priori as a plausible model. Yet, this is exactly what Eid et al.’s (2017) are doing based on some statistical discussion that I honestly cannot follow. All I can say is that it from a substantive point of view, a bi-factor model is a reasonable specification of the assumption that cognitive performance can be influenced by general and specific factors and that this model predicts stronger correlations among measures that tap the same specific abilities than measures that share only the general factor as a common cause.
After Eid et al. convinced themselves, reviewers, and an editor at a prestigious journal that their statistical reasoning was sound, they proposed a new way of modeling correlations among cognitive performance measures. They call it, the Bifactor-(S-1) model. The key difference between this model and the bi-factor model is that the authors remove one of the specific factors from the model; hence, S – 1.
You might say, but what if there is specific variance that contributes to performance on these task? If these specific factors exist, they would produce stronger correlations between measures that are influenced by these specific factors and a model without this factor would not fit the data (as well as the model that includes a specific factor that actually exists). Evidently, we cannot simply remove factors willy-nilly without misrepresenting the data. To solve this problem, the bi-factor (S-1) model introduces new parameters that help the model to fit the data as well or better than the bi-factor model.
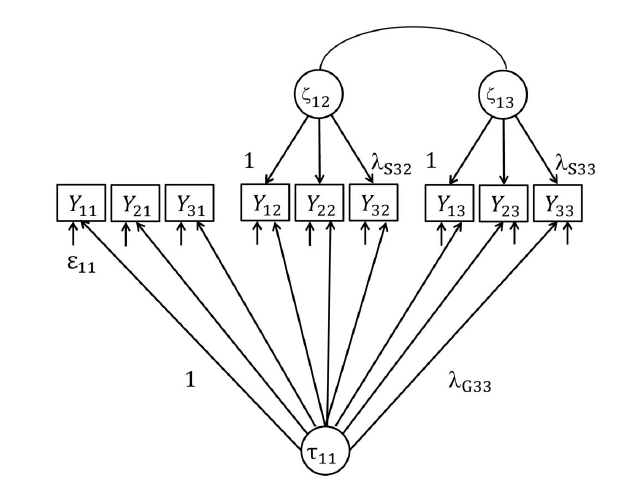
Figure 4 in Eid et al.’s article makes it possible for readers who are not statisticians to see the difference between the models. First, we see that the S1 factor has been removed. Second, we see that the meaningful factor names (g = general and s = specific) have been replaced by obscure Greek letters where it is not clear what these factors are supposed to represent. The Greek letter tau (I had to look this up) stands for T = true score. Now true score is not a substantive entity. It is just a misleading name for a statistical construct that was created for a measurement theory that is called classic, meaning outdated. So, the bi-factor (S-1) model no longer claims to measure anything in the real world. There is no g-factor that is based on the assumption that some people will perform better on all cognitive tasks that were developed to measure this common factor. There are also no longer specific factors because specific factors are only defined when we first attribute performance to a general factor and see that other factors also have a common effect on subsets of measures. In short, the model is not a substantive model that aims to measure. It is like creating thermometers without assuming that temperature exists. When I discussed this with Michael Eid years ago, he defended this approach to measurement without constructs with a social-constructionistic philosophy. The basic idea is that there is no reality and that constructs and measures are social creations that do not require validation. Accordingly, the true score factor measures what a researcher wants to measure. We can simply pick two or three correlated measures and the construct becomes whatever produces variation in these three measures. Other researchers can pick other measures and the factors that produce variation in these measures are the construct. This approach to measurement is called operationalism. Accordingly, constructs are defined by measures and intelligence is whatever some researchers shows to measure and call intelligence. Operationalism was rejected by Cronbach and Meehl (1955) and led to the development of measurement models that can be used to examine whether a measure actually measures what it is intended to measure. The bifactor (S-1) model avoids this problem by letting researchers chose measures that define a construct without examining what produces variation in these measures.
“One way to define a G factor in a single-level random experiment is to take one domain as a reference domain. Without loss of generality, we may choose the first domain (k = 1) as reference domain and take the first indicator of this domain (i = 1) as a
reference indicator. This choice of the reference domain and indicator indicator
depends on a researcher’s theory and goals” (Eid et al., 2017, p. 550).
While the authors are transparent about the arbitrary nature of true scores – what is true variance depends on researchers’ choice of which specific factors to remove – they fail to point out that this model cannot be used to test the validity of measures because there is no longer a claim that factors correspond to real-world objects. Now both the measures and the constructs are constructed and we are just playing around with numbers and models without testing any theoretical claims.
Assuming the bi-factor model fits the data, it is easy to explain what the factors in the bi-factor (S-1) model are and why it fits the data. Because the model removed S-1, the true-score factor now represents the g-factor and the S1 factor. The G+S1 factor still predicts variance in the S2 and S3 measures because of the g-variance in the G+S1 factor. However, because the S1-variance in the G+S1 factor is not related to the S2 and S3 measures, the G+S1 factor explains less variance in the S2 and S3 measures than the g-factor in the bi-factor model. The specific factors in the bi-factor (S-1) model with the Greek symbol zeta (ζ) now predict more variance in the S2 and S3 measures because they not only represent the specific variance, but also some of the general factor variance that is not removed by using the contaminated g+S1 factor to account for shared variance among all measures. Finally, because the zeta factors now contain some g-variance that is shared between S2 and S3 measures, the two zeta factors are correlated. Thus, g-variance is split into g-variance in the g+S1 factor and g-variance that is common to the zeta factors.
Eid et al. might object that I assume the g-factor is real and that this may not be the case. However, this is a substantive question and the choice between the bi-factor model and the bi-factor (S-1) model has to be based on broader theoretical consideration and eventually empirical tests of the competing models. To do so, Eid et al. would have to explain why the two zeta-factors are correlated, which implies an additional common cause for S2 and S3 measures. Thus, the empirical question is whether it is plausible to assume that in addition to a general factor that is common to all measures, S2 and S3 have another common cause that is not shared by S1 measures. The key problem is that Eid et al. are not even proposing a substantive alternative theory. Instead, they argue that there are no substantive questions and that researchers can pick any model they want if it serves their goals. “This choice of the reference domain and indicator indicator depends on a researcher’s theory and goals” (p. 550).
If researchers can just pick and chose models, it is not clear why they could not just pick the standard bi-factor model. After all, the bi-factor (S-1) model is just an arbitrary choice to define the general factor in terms of items without a specific factor. What is wrong with choosing to all for all measures to be influenced by specific factors as in the standard bi-factor model. Eid et al. (2014) claim that this model has several problems. The first claim is that the bi-factor model often produced anomalous results that are often not consistent with the a priori theory. However, this is a feature of modeling, not a bug. What are the chances that a priori theories always fit the data? They whole point of science is to discover new things and new things often contradict our a prior notions. However, psychologists seem to be averse to discovery and have created the illusion that they are clairvoyant and never make mistakes. This narcissistic delusion has impeded progress in psychology. Rather than recognizing that anomalies reveal problems with the a priori theory, they blame the method for these results. This is a stupid criticism of models because it is always possible to modify a model and find a model that fits the data. The real challenge in modeling is that often several models fit the data. Bad fit is never a problem of the method. It is a problem of model misspecification. As I showed, proper exploration of data can produce well-fitting and meaningful models with a g-factor (Schimmack, 2022). This does not mean that the g-factor corresponds to anything real, nor does it mean that it should be called intelligence. However, it is silly to argue that we should prefer models with a general factor and simply pick some measures to create constructs that do not even aim to measure anything real.
Anther criticism of standard bi-factor models is that the loadings (i.e., the effect sizes of the general factor on measures) are unstable. “That means, for example, that the G-factor of intelligence should stay the same (i.e., “general”) when one takes out four of 10 domains of intelligence” (p. 546). Eid et al. point out that this is not always the case.
“Reise (2012), however, found that the G factor loadings can change when domains are removed. This causes some conceptual problems, as it means that G factors as measured in the bifactor and related models are not generally invariant across different sets of domains used to measure them. This can cause problems, for example, in literature reviews or meta-analyses that summarize data from different studies or in so-called conceptual replications in which different domains were used to measure a given G factor, because the G factors may not be comparable across studies.” (p. 546).
This is nonsense. First of all, the problem that results are not comparable across studies is much greater when researchers just start arbitrarily selecting sets of measures as indicators of the general+S factor because the g+S1, g+S2, g+S3 factors are conceptually different. All reall sciences have benefited from unification and standardization of measurement by selecting the best measures. In contrast, only psychologists think we are making progress by developing more and more measures. The use of bi-factor (S-1) models makes it impossible to compare measures because they are all valid measures of researchers’ pet constructs. Thus, use of this model will further impede progress in psychological measurement.
Eid et al. (2014) also exaggerate the extent to which results depend on the choice of measures in the bi-factor model. The more measures are highly correlated and reflect the full range of measures, the more results will be stable and comparable. Moreover, the only reason for notable changes in loadings would be mismeasurement of the general factor because some specific factors were not properly modeled. To support my claim, I used the data from Brunner et al. (2012) who fitted a bi-factor model to 14 measures of g. I randomly split the 14 measures into two sets of 7 and fitted a model with two g-factors and let the two factors correlate. The magnitude of this correlation shows how much inferences about g would depend on the arbitrary selection of measures. The correlation was r = .96 with a 95%CI ranging from .94 to .98. While number-nerds might get a hard-on because they can now claim that results are unstable, p < .05, applied researchers might shrug and think that this correlation is good enough to think they measured the same thing and it is ok to combine results in a meta-analysis.
In sum, the criticism of bi-factor models is all smoke and mirrors to advertise another way of modeling data and to grab market share from the popular bi-factor model that took away market share from hierarchical models. All of this is just a competition among psychometricians to get attention that doesn’t advance actual psychological research. The real psychometric advances are made by psychometricians who created statistical tools for applied researchers like Jorekog, Bentler, and Muthen and Muthen. These tools and substantive theory are all that applied researchers need. The idea that statistical considerations can constrain the choice of models is misleading and often leads to suboptimal and wrong models.
Readers might be a bit skeptical that somebody who doen’t know the Greek alphabet and doesn’t understand some of the statistical arguments is able to criticize trained psychometricians. After all, they are experts and surely must know better what they are doing. This argument ignores the systemic factors that make them do things that are not in the best interest of science. Making a truly novel and useful contribution to psychometrics is hard and many well-meaning attempts will fail. To make my point, I present Eid et al.’s illustration of their model with a study of emotions. Now, I may not be a master psychometrician, but nobody can say that I lack expertise in the substantive area of emotion research and in attempts to measure emotions. My dissertation in 1997 was about this topic. So, what did Eid et al. (2017) find when they created a bi-factor (S-1) measurement model of emotions?
Eid et al. (2017) examined the correlations among self-reports of 9 specific negative emotions. To fit their model to the data, they used the Anger domain as the reference domain. Not surprisingly, anger, fury and rage had high loadings on the true score factor (falsely called the g-factor) and the other negative emotions had low loadings on this factor. This result makes no sense and is inconsistent with all established models of negative affect. All we really learn from this model is that a factor that is mostly defined by anger also explains a small amount of variance in sadness and self-conscious negative emotions. Moreover, this result is arbitrary and any one of the other emotions could have been used to model the misnamed g-factor. As a result, there is nothing general about the g-factor. It is a specific factor by definition. “The
G factor in this model represents anger intensity” (p. 553). But why would we call a specific emotion factor a general factor. This makes no theoretical sense. As a result, this model does not specify any meaningful theory of emotions.

A proper bi-factor or hierarchical model would test the substantive theory that some emotions covary because they share a common feature. The most basic feature of emotions is assumed to be valence. Based on this theory, emotions with the same valence are more likely to co-occur , which results in positive correlations among emotions of the same valence. Hundreds of studies have confirmed this prediction. In addition, emotions also share specific features such as appraisals and action tendencies. Emotions who also share these components are more likely to co-occur than emotions with different or even opposing appraisals. For example, pride and gratitude are based on opposing appraisals of attribution to self or others. A measurement model of emotions might represent these assumptions in a model with one or two general factors for valence (the dimensionality of valence is still debated) and several specific factors. In this model, the general factor has a clear meaning and represents the valence of an emotion. Fitting such a model to the data is useful to test the theory. Maybe the results confirm the model, may be they don’t. Either way, we learn something about human emotions. But if we fit a model that does not include a factor that represents valence and misleadingly label an anger-factor a general factor, we learn nothing, except that we should not trust psychometricians who build models without substantive expertise. Sadly, Eid has actually made good contributions to emotion research in the 1990s that has identified broad general factors of affect that he appears to have forgotten. Accordingly, he would have modeled affect along three general dimensions (Steyer, Schwenkmezger, Notz, & Eid, 1997).
Concluding Rant
In conclusion, the main point of this blog post is that psychometricians benefit from developing ready-to-use, plug-and-play models that applied researchers can use without thinking about the model. The problem is that measurement requires understanding of the object that is being measured. Thermometers do not measure time and clocks are not good measures of weight. As a result, good measurement requires substantive knowledge and custom models that are fitted to the measurement problem at hand. Moreover, measurement models have to be embedded in a broader model that specifies theoretical assumptions that can be empirically tested (i.e., Cronbach & Meehl’s, 1955, nomological network). The bi-factor (S-1) model is unhelpful because it avoids falsification by letting researchers define constructs in terms of an arbitrary set of items. This may be useful for scientists who want to publish in a culture that values confirmation (bias), it is not useful for scientist who want to explore the human mind and need valid measures to do so. For these researchers, I recommend to learn structural equation modeling from some of the greatest psychometricians who helped researchers like me to test substantive theories such as Joreskog, Bentler, and now Muthen and Muthen. They provide the tools, you need to provide the theory and the data and be willing to listen to the data when your model does not fit. I learned a lot.
The bifactor S-1 model is indeed bizarre and I don’t understand why it features in so many critiques of the bifactor model.
However, often the hope when fitting bifactor (rather than hierarchical factor models) seem to be to find ways of separating the general factor from the specific factors; this was certainly part of what attracted me to the bifactor model in the first place, and you seem to regularly be doing this in order to control for social desirability bias.
However, my experience is that this doesn’t work well in practice, because the way the bifactor model allows separating the general factor variance from specific factor variance is through subtle deviations in the correlations, but those subtle deviations will tend to be heavily sensitive to other measurement problems and sometimes do not even exist (such as when the ‘true process’ follows the hierarchical factor model).
As such I don’t think the bifactor model can do what you or I would like it to do, even though much critique of it is bad.
Glad we agree about the bifactor-(s-1) model. Regarding bifactor models in general, I am not a fan of any predefined models with fixed statistical assumptions that are not guided by theory. The problem with EFA is that it is rigid and not based on substantive theory. The key innovation with CFA was that it is possible to specify substantive theories and test them against data. In this blog post, I show that a hierarchical model can fit the data as well as a bifactor model.
https://replicationindex.com/2022/10/01/a-tutorial-on-hierarchical-factor-analysis/
The choice of a model should be driven by substantive knowledge about the construct and measures. Like, it makes sense to model acquiescence with a general factor with coding of the item direction. You can even have a general factor and a hierarchical structure for specific factors. SEM doesn’t impose any restrictions. Unhelpful psychometricians do.
I agree that it makes perfect sense to think of acquiescence via a bifactor model, and that is also how I would think of it myself. The point where you lose me is when you try to fit this bifactor model to single-informant data in order to control for acquiescence, because I think this is very sensitive to model misspecification and other sources of noise, to the point where I think the results obtained from the bifactor element of the model will mostly be noise.
Also agree with the value in thinking about substantive theory for selecting SEM models, and with the fact that there are many options for models beyond cookiecutter ones.
It is really not difficult to fit an acquiescence factor because the pattern of loadings is random and not related to any other structure in the data. Maybe one point of confusion is that I constrain loadings on method factors to 1. If you let all loadings be free, you run into problems like you describe and maybe also what happened in some of the papers with anomalous results.
Hm, if you have both positive and negatively coded items, then I think I agree with the specific case of acquiescence.
In general, I don’t think constraining loadings to 1 solves the bifactor issues unless that actually matches the true loading pattern of the general factor; it would probably just introduce its own biases. But for acquiescence, having loadings of 1 doesn’t seem like too bad of a guess for what the true loading pattern is, and even if it isn’t, as long as you have lots of both positive and negatively coded items, the errors should cancel out.
So maybe the place where you really lose me is when controlling for social desirability bias. Here, I suspect the true loadings have all sorts of complex correlations with the semantics of the items.
One possibility I’ve been considering is that one could just ask people to rate items for social desirability, and then use those ratings to constrain the loadings. I don’t know if it would work, but it might be worth trying.
Getting weights by asking for desirability is the best option to validate a pattern of loadings on the halo/SD factor. However, if you do not have that, starting with equality constraints is a reasonable option. A lot more reasonable than to fix all loadings at zero based on the implicit assumption that there is no bias.
I think a smarter solution than fixing all loadings at zero or one is to try to think about when a social desirability factor would interfere with the results and consider the data to be of no evidentiary value in those cases. You don’t always get to have results if your data is not geared to it.
Are you saying you are smarter than me? 🙂
Dichotomous thinking is the problem. Just because data have some bias or the bias is only somewhat removed, doesn’t mean the data have no evidential value. It is all about quantities. Acquiescence bias is very small and can be ignored except for sensitive fit indices. SD bias is bigger but still lower than real trait variance.
I meant consider the data of no evidentiary value for disentangling SD vs trait variance, not for questions in general. 😅
Thanks for clarifying. I agree that self-report data alone are not able to disentangle the two. The interpretation of the g-factor as a mostly SD/bias factor is based on multi-rater studies that make it possible to sperate the two. So, adding a g-factor to a model is based on (reasonable, validated) assumptions, not a test of this assumption. This is of course true for all models. They need assumptions to be identified.
I agree that this is a reasonable approach for how to handle covariance between the Big Five in self-report studies that don’t have informant-report data; that’s how science proceeds, by figuring out the answer to a question and then using that answer in the future.
However, the trouble comes when you don’t just place this as a factor that explains the self-report Big Five covariance structure, but also extend this factor outside of the self-report. So for instance, if you try to test whether personality disorders are real or just halo, you might try to let that factor cross-load onto the personality disorder measure; but I don’t think that approach works.
Because the way SEM identifies the cross-loadings in such a scenario is (roughly) to see if the personality disorder measure correlates with each of the Big Five trait measures, but that could happen even if the halo factor isn’t the thing that generates the correlations, e.g. it could happen if each of the Big Five traits contribute to likelihood of personality disorders.
… I’m not very satisfied with my explanation above, so here’s some DAGs to illustrate it: https://imgur.com/a/0Vkx5np
My guess for the true answer to this conundrum would be the following: There are some traits that are socially approved of/disapproved of, for whatever reasons. This induces a Halo factor of measure error, but it also means that personality traits that are considered “disordered”/”mentally ill” will specifically tend to be the same sorts of traits as those covered by the Halo factor. So basically, I would expect a mixture of possibility 1 and possibility 2.
Not sure if my explanation here makes sense. I need to go to sleep.
As you know SEM can often not decide between alternative plausible models. However, often researchers present only one model that they favor and do not show the alternative models. I show an alternative model that is plausible and challenges the status quo. Next of course, we need better data that can distinguish the models and that is why I asked researchers to share their multi-method data and showed that the general factor is more halo than some substantive disorder factor. So, I don’t know what your main point in all of these comments is? It all works out as expected and your concerns seem to be based on some broader concerns that ignore the specific theory that is being tested.
https://replicationindex.com/2022/09/06/personality-disorder-research-a-pathological-paradigm/
Oh wait, so you did get multi-informant data to test? My bad, I had not been keeping up/paying proper attention. This is very enlightening.
The usage of Greek letters, as annoying as it may be to you, is a helpful but often unexplained notational practice in statistics; it’s there for a reason. Here’s the idea:
Observed quantities get lowercase letters (x-bar, for example). Random quantities get capital letters (big X-bar); unobservable quantities get Greek letters (μ).
I understand the natural scorn at these “arcane” symbols, but they serve to correct the very, very common mistake of confusing observed quantities for the unobserved ones they (are trying to) measure. This is something more modern and there’s obviously a lot of statistical quantities that don’t follow this rule (alpha for significance, spearman’s ρ), but when it’s there it (in my opinion) actually *increases* clarity (the correlation coefficient ρ vs Pearson’s r, S^2 vs σ^2, the observed residuals e vs the theoretical residuals ε…). How many times have you seen people confuse IQ for g? The whole point of the greek letters is to make the confusion impossible; you don’t know Greek, so how the hell could you possibly observe a ξ?
Hope this helps.
Thank you for taking the time to comment. I agree that it is very important to distinguish between unknown population parameters and estimates of these parameters in samples and between observed variables and unobserved variables. I just think we don’t need Greek symbols to do so. For example, we could use Cohen’s d for effect size ESTIMATES and D for the mean difference between two populations. Learning the Greek alphabet is just an unnecessary hurdle to get this distinction across.
Thanks for the reply. Certainly, you are correct that you don’t need the greek letters for the parameters, but your example actually helps point out where the notation is useful: suppose we wish to speak of the cumulative density of Cohen’s d. As statisticians, we would usually intuitively write, for example, P(D (the random variable) < d (a number)); now (unless you are a Bayesian) this expresion is nonsense.
One of the most common mistakes for 1st and 2nd year students of statistics is to confuse a random variable with its argument in the CDF. This is the mistake which that part of the notation is trying to avoid, which is, admittedly, not one of much relevance to applied workers.
To be clear: I agree with pretty much everything else in the article, but the greek (when well-done) is a force for good, not evil. In sum: when describing statistical quantities, we usually need to talk about three wholly different types of object (random variable, observed variable, unobserved parameter); and I don't really know of a better alphabet for the third type.
maybe another good of Covid-19 is that people are more familiar with parts of the Greek alphabet. 🙂
I’m a bit late to the party, but I’m wondering where this claim came from: “Borsboom has carefully avoided his own advice and became a rock-star for his claims that the founding people of psychometrics were all delusional because they actually believed in substances that could be measured (traits) and developed methods to measure intelligence, personality, or attitudes.”
I recently finished Borsboom’s Measuring the Mind and it seems to me that his perspective is quite the opposite. For example, the proposition that measures are valid if the purpotedly measured construct exists (and its variance causes variance of the measure’s scores) implies that he believes in 1) the possibility of the existence of psychological traits 2) that these traits can be measured validly.
I didn’t read the popular book, but I heard good things about it. However, his actual research is actually not about measurement of anything. He developed pictorial representations of correlation matrices that are called network models, but there is no construct and no model of a construct. It just shows which items are more correlated with other items. Does the book talk about network models?