Abstract
Psychology lacks solid foundations. Even basic methodological issues are contentious. In this tutorial, I revisit Brunner et al.’s (2012) tutorial on hierarchical factor analysis. The main difference between the two tutorials is the focus on confirmation versus exploration. I show how researchers can use hierarchical factor analysis to explore data. I show that exploratory HFA produces a plausible better fitting model than Brunner et al.’s confirmatory HFA. I also show that it is not possible to use statistical fit to compare hierarchical models to bi-factor models. To do so, I show that my hierarchical model fits the data better than their bi-factor model. Instead, the choice between hierarchical models and bi-factor models is a theoretical question, not a statistical question. I hope that this tutorial will help researchers to realize the potential of exploratory structural equation modeling to uncover patterns in their data that are not predicted a priori.
Instruction
About a decade ago, Brunner, Nagy, and Wilhelm (2012) published an informative article about the use of Confirmatory Factor Analysis to analyze personality data, using a correlation table of performance scores on 14 cognitive ability tasks as an example.
The discussed four models, but my focus is on the modeling of these data with hierarchical CFA or hierarchical factor analysis. It is not necessary to include confirmatory in the name because only CFA can be used to model hierarchical factor structures. EFA by definition has only one layer of factors. Sometimes researchers conduct hierarchical analysis by using correlations among weighted sum scores (factors) as indicators of lower levels in a hierarchy. However, this is a suboptimal approach to test hierarchical structures. The term confirmatory has also been shown to be misleading because many researchers believe CFA can only be used to test a fully specified theoretical model and any post-hoc modifications are not allowed and akin to cheating. This has stifled the use of CFA because theories are often not sufficiently specified to predict the pattern of correlations well enough to achieve good fit. It is also not possible to use an EFA for exploration and CFA for confirmation because EFA cannot reveal hierarchical structures. So, if hierarchical structures are present, EFA will produce the wrong model and CFA will not fit. Maybe the best term would be hierarchical structural equation modeling, but hierarchical factor analysis is a reasonable term.
One of the advantages of CFA over EFA is that CFA makes it possible to create hierarchical models and to provide evidence for the fit of a model to data. CFA also makes it possible to modify models and to test alternative models, while EFA solutions are determined by some arbitrary mathematical rules. In short, any researcher interested in testing hierarchical structures in correlational data should use hierarchical factor analysis.
Hierarchical models are needed when a single layer of factors is unable to explain the pattern of correlations. It is easy to test the presence of hierarchies in a dataset by fitting a model with a single layer of independent factors to the data. Typically, these models do not fit the data. For example, Big Five researchers abandoned CFA because this model never fit actual personality data. Brunner et al. also show that a model with a single factor (i.e., Spearman’s general intelligence factor) did not fit the data, although all 14 variables show strong positive correlations with each other. This suggests that there is a general factor (suggests does not equal proofs) and it suggests that there are additional relationships among some variables that are not explained by the general factor. For example, vocabulary and similarities are much stronger correlated, r = .755, than vocabulary and digit span, r = .555. The aim of hierarchical factor analysis is to model the specific relationships among subsets of variables.

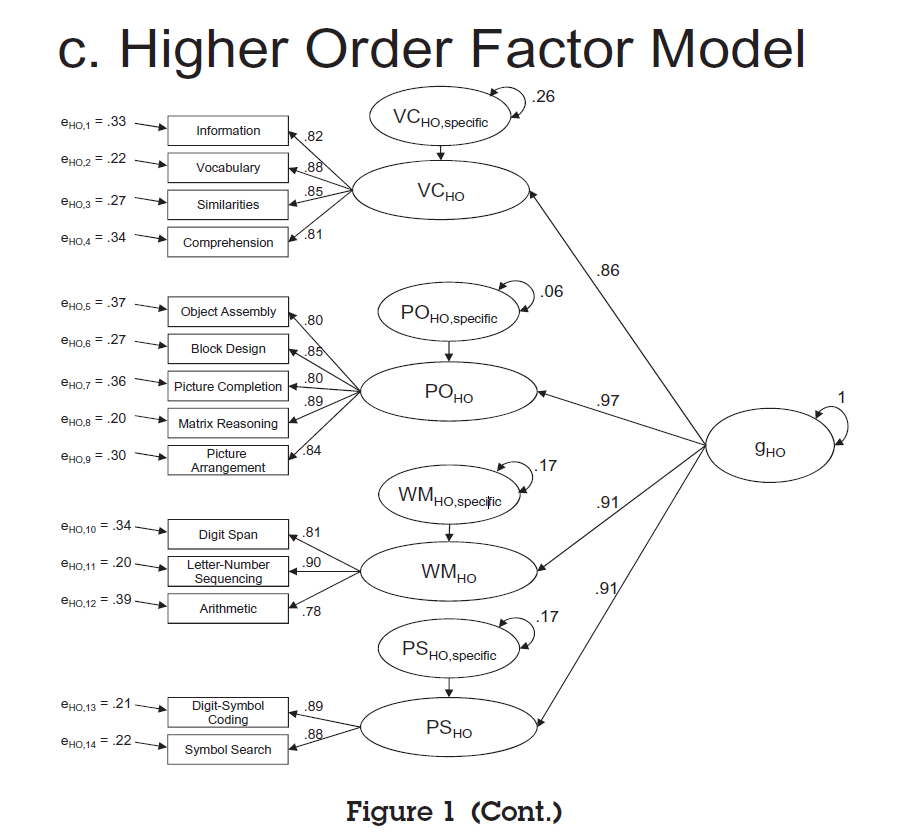
Brunner et al. present a single hierarchical model with one general factor and four specific factors.
Their Table 2 shows the fit of this model in comparison to three other, non-hierarchical models.

The results show that the hierarchical model fits the data better than a model with a single g-factor, RMSEA = .071 vs. 132 (lower values are better). The results also show that the model fits the data not as well as the first order factor model. The difference between these models is that the hierarchical model assumes that the correlations among the four specific (first-order) factors can be explained by a single higher-order factor, that is, the g-factor. The reduction in fit can be explained by the fact that a single factor is not sufficient to explain this pattern of correlations. The single factor model uses four parameters (the ‘causal effects’ of the g-factor on the specific factor) to predict the six correlations among the four specific factors. This model is simpler as one can see by the comparison of degrees of freedom (73 vs. 71). it would be wrong to conclude from this model comparison that there is no general factor and to reject the hierarchical model based on this statistical comparison. The reason is that it is possible to use the extra degrees of freedom to improve model fit. If two parameters are added to the hierarchical model, fit will be identical to the first-order factor model. There are many ways to improve fit and the choice should be driven by theoretical considerations. For example, one might not want to include negative relationships to fit a model of only positive correlations, although this is by no means a general rule. Modification indices suggested additional positive correlations between the PO and PS factor and the PO and WM factor. Adding these parameters reduced the degrees of freedom by two and produced the same model fit as the model first-order factor model. Thus, it does not seem to be possible to reduce the six correlations among the Big Five factors to a model with fewer than six parameters. Omitting these additional relationships for the sake of a simple hierarchical structure is problematic because the model no longer reflects the pattern in the data. In short, it is always possible to fit the data with a hierarchical model that fits the data as well as a first-order model. Only the assumption that a single-factor accounts for the pattern of correlations among the first-order factors is restrictive and can be falsified. Just like the single factor model, the single-higher-order model will often not fit the data.
A more important comparison is the comparison of the hierarchical model with the nested factor model which is more often called the bi-factor model. Bi-factor models have become very popular among users of CFA and Brunner et al.’s tutorial may have contributed to this trend. The bi-factor model is shown in the next figure.

Theoretically, there is not much of a difference between hierarchical models. Both models assume that variance in an observed variable can be separated into three components. One component reflects variance that is explained by the general factor and leads to correlations with all other variables. One component reflects variance that is explained by a specific factor that is only shared with a subset of variables. And the third component is unique variance that is not shared with any other variable often called uniqueness, disturbance, residual variance, or erroneously error variance. The term error variance can be misleading because unique variance may be meaningful variance that is just not shared with other variables. Brunner et al.’s tutorial nicely shows the unique variance that is only shared among some items in the hierarchical model. This variance is often omitted from figures because it is the residual variance in first-order factors that is not explained by the higher-order factor. For example, in the figure of the hierarchical model, we see that variance in the specific factor VD is separated into variance explained by the g-factor and residual variance that is not explained by the g-factor. This residual variance is itself a factor (an unobserved variable) and this factor conceptually corresponds to the specific factors in the bi-factor model. Thus, conceptually the two models are very similar and may be considered interchangeable representations Yet, the bi-factor model fits the data much better than the hierarchical model, RMSEA = .60 vs. .71. Moreover, the bi-factor model meets (barely) the standard criterion of acceptable model fit for the RMSEA criterion (.06). Thus, readers may be forgiven if they think the bi-factor model is a better model of the data.
Moreover, Brunner et al.’s tutorial suggests that the higher-order model should only be chosen if it fits the data as well as the bi-factor model, which is not the case in this example. Thus, their recommendation leads to the assumption that the better fit of a bi-factor model can be used to decide between these two models. Here I want to show that this recommendation is false and that it is always possible to create a hierarchical model that fits as well as a bi-factor model. The reason is that the poorer fit of the hierarchical model is a cost of its parsimony. That is, it has 73 degrees of freedom compared to 64 degrees of freedom for the bi-factor model. This means that it is possible to add 9 parameters to the hierarchical model to improve fit within a hierarchical structure. Inspection of modification indices suggested that a key problem of the hierarchical model was that it underestimated the relationship of the arithmetic variable on the g-factor. This relationship is mediated (goes through) working memory and is influenced by the relationship of working memory with the g-factor. We can relax this assumption by allowing for a direct relationship between the arithmetic variable and the g-factor. Just this single additional parameter improved model fit and made the hierarchical model fit the data better than the bi-factor model., chi2(70) = 403, CFI = .980, RMSEA = .059. Of course, in other datasets more modifications may be necessary, but the main point generalizes from this example to other datasets. It is not possible to use model fit to favor bi-factor models over hierarchical models. The choice of one or the other model needs to be based on other criteria.
Brunner et al. (2012) discuss another possible reason to favor bi-factor models. Namely, it is not possible in a hierarchical model to relate a criterion variable to the general factor and to all specific factors. The reason is that this model is not identified. That is, it is not possible to estimate the direct contribution of the general factor because the general factor is already related to the criterion by means of the indirect relationships through the specific factors. While Brunner et al. (2012) suggest that this is a problem, I argue that this is a feature of a hierarchical model and that the effect of the general factor is just mediated by the specific factors. Thus, we do not need an additional direct relationship from the general factor to a criterion. We can simply estimate the effect of the general factor by computing the total indirect effect that is implied by the (a) effect of the general factor on the specific factors and (b) the effect of the specific factors on the criterion. In contrast, the bi-factor model provides no explanation about the (implied) causal effect of the general factor on the criterion. For example, high school grades in English might be related to the g-factor because the g-factor influences verbal intelligence (VC) and verbal intelligence is the more immediate cause of better performance in a language class. Thus, a key advantage of a hierarchical model is that it proposes a causal theory in which the effects of broad personality traits on specific behaviors are mediated by specific traits (e.g. effect of extraversion on drug use is mediated by the sensation seeking facet of Extraversion and not the Assertiveness facet of extraversion).
In contrast, a bi-factor model assumes that the general and the specific factors are independent. One plausible reason to use a bi-factor model would be the modeling of method factors like acquiescence or social desirability (Anusic et al., 2009). A method factor would influence responses to all (or most) items, but it would be false to assume that this effect is mediated by the specific factors that represents actual personality constructs. Instead, the advantage of CFA is that it is possible to separate method and construct (trait) variance to get an unbiased estimate of the effect size for the actual traits. Thus, the choice of a hierarchical model or a bi-factor model should be based on substantive theories about the nature of factors and cannot be made based in a theoretical vacuum.
How to Build a Hierarchical Model
There are no tutorials about the building of SEM models because the terminology of confirmatory factor analysis has led to the belief that it is wrong to explore data with CFA. Most of the time, authors may explore the data and then present the final model as if it was created before looking at the data; a practice known as Hypothesizing after Results are known (HARKing, 1998). Other times, authors will use a cookie-cutter model that they can justify because everybody uses the same model, even when it makes no theoretical sense. The infamous cross-lagged panel model is one example. Here I show how authors can create a plausible model that fits the data. There is nothing wrong with doing so and all mature sciences have benefitted from developing models, testing them, testing competing models against each other, and making progress in the process. The lack of progress in psychology can be explained by avoiding this process and pretending that a single article can move from posing a question to providing the final answer. Here I am going to propose a model for the 14 cognitive performance tests. It might be the wrong model, but at least it fits the data well.
The pattern of correlations in Table 1 shows many strong positive correlations. There is also 100-years of research on the positive manifold (positive correlations) among cognitive performance tasks. Thus, a good starting point is the one-factor model that simply assumes that a general factor contributes to scores on all 14 variables. As we already saw, this model does not fit the data. Modern software makes it possible to look for ways to improve the model by inspecting so called Modification Indices. As a first step, we want to look for big (juicy) MI that are unlikely to be chance results. MI are chi-square distributed with 1 df and chi-square values with 1 df are just squared z-scores (scores on the standard normal). Thus, an MI of 25 corresponds to z = 5, which is the criterion used in particle physics to rule out false positives. Surely, this criterion is good enough for psychologists. It is therefore problematic to publish models with MI > 25 because this model ignores some reliable pattern in the data. Of course, MI are influenced by sample size and the effect size may be trivial. However, it is better to include these parameters in the model and to show that they are small and negligible rather than to present an ill-fitting model that may not fit because it omitted an important parameters. Thus, my first recommendation is to inspect modification indices and to use them. This is not cheating. This is good science.
We want to first look for items that show strong residual correlations. A residual correlation is a correlation between the residual variances of two variables after we remove the variance that is shared with the general factor. It is ok to start with the highest MI. In this case, the highest MI is 273, z = 16.5, which is very, very, unlikely to be a chance finding. The suggested effect size for this residual correlation is r = .48. So, this relationship is clearly substantial. To add this finding to a hierarchical model, we do not simply add a correlated residual. Instead, we model this residual correlation as a simple factor in a hierarchical model. Thus, we create the first simple factor in our hierarchical model. Because this simple factor is related to the g-factor (unlike the bi-factor model where it would be independent of the general factor), we can estimate the strength of the factor loadings freely and the model is just identified. Optionally, we could constrain the loadings of the two items, which can sometimes be helpful in the beginning to stabilize the model. The first specific factor in the model represents the shared variance between Letter-Number-Sequencing and and Digit Span. A comparison with Brunner et al.’s model shows that this factor is related to the Working Memory factor in their model. The only difference is that their factor has an additional indicator, Arithmetic. So, we didn’t really do anything wrong by starting totally data-driven in our model.
The first simple-factor in the model is basically a seed to explore whether other items may also be related to this simple factor. Now that we have a factor to represent the correlation between the Letter-Number-Sequencing and Digit Span variables, we could find MI that suggest loadings of other variables on this factor. If this is not the case, other items may still be highly correlated and can be used to add additional simple factors. We can run the revised model and examine the MI. This revealed a significant MI = 48 for Arithmetic. This is also consistent with Brunner’s model and I added it. However, Arithmetic still had a direct loading on the general factor, which is not consistent with their model. In addition, there was a
It is well known that MI can be misleading. For example, the MI for this model suggested a strong loading of Matrix Reasoning on the Working Memory factor. This doesn’t seem implausible. However, Brunner et al.’s model suggests that Matrix Reasoning is related to another specific factor that is not yet included in the model. Therefore, I first looked for other residual correlations that could be the seed for additional specific factors. Also, MI for additional residual correlations were larger. The largest MI was for the residual correlation between Matrix Reasoning and Information. This is inconsistent with Brunner et al.’s model that suggested these items belong to different specific factors. However, to follow the data-driven approach, I used this pair as a seed for a new specific factor. The next big correlated residual was found for Block Design and Comprehension. Once more, this did not correspond to a specific factor in Brunner et al.’s model, but I added it to the model. The next run showed a still sizeable MI (22) for Digital-Symbol-Coding on the Working-Memory factor. So, I also added this parameter, but the effect size was small, b = .19. Thus, Brunner et al.’s model is not wrong, but omitting this parameter lowers overall fit. As there we no other notable MI for the Working Memory factor, I looked for the correlated residual with the highest MI as a seed for another specific factor. This was the correlated residual for Digital-Symbol-Coding and Symbol Search. This correlated residual is represented by the PS factor in Brunner et al.’s model. The next high modification index suggested a factor for Vocabulary and Comprehension. This is reflected in the VC factor in Brunner’s model. The MIs of this model suggested a strong loading of Similarity on the VC factor (MI = 297), which is also consistent with Brunner et al.’s model. Another big MI (256) suggested that Information also loads on the VC factor, again consistent with Brunner et al.’s model. The next inspection of MIs, however, suggested an additional moderate loading of Arithmetic on the VC factor that is not present in Brunner et al.’s model. I added it to the model and model fit improved, CFI = .976 vs. 973). Although the loading was only b = .29, not including it in a model lowers fit. The next round suggested another weak loading of letter-number sequencing on the PS factor. Adding this parameter further increased model fit, CFI = .978 vs. 976, although the effect size was only b = .23. The next big MI was for the correlated residual between Object-Assembly and Block-Design (MI = 82). This relationship is represented by the PO factor in Brunner et al.’s model.
At this point, the model already had good overall fit, CFI = .982, RMSEA = .055, although three variables were still unrelated to the specific factors, namely Picture Completion, Picture Arrangement, and Matrix Reasoning. It is possible that these variables are directly related to the general factor, but it is also possible to model the relationship as being mediated by specific factors. Theory would be needed to distinguish between these models. To examine possible mediating specific factors, I removed the direct relationship and examined the MI of this model with bad fit to find mediators. Consistent with Brunner et al.’s model, Picture-Comprehension, Picture-Arrangement, and Matrix-Reasoning showed the highest MI for the PO factor, although the MI for the g-factor was equally high or higher. Thus, I added these three variables as indicators to the PO factor.
At this point, the biggest MI (76) suggested a correlated residual between Object-Assembly and Block-Design. However, these two variables are already indicators of the PO factor. The reason for the residual correlation is that the PO factor also has to explain relationships with the other variables that are related to the PO factor. Apparently, Object-Assembly and Block-Design are more strongly related than the loadings on the PO factor predict. To allow for this relationship within a hierarchical model it is possible to add another layer in the hierarchy and specify a sub-PO factor that accounts for the shared variance between Object-Assembly and Block-Design. This modification improved model fit, CFI = .977 vs. .981. The RMSEA was .045 and in the range of acceptable fit (.00 to .06).
At this point most MI are below 25, suggesting that further modifications are riskier, but also only minor modifications that will not have a substantial influence on the broader model. Some of the remaining MI suggested negative relationships. While it is possible that some abilities are also negatively related to other, I decided not to include them in the model. One MI (31) suggested a correlation between the VC and WM factors. A simple way to improve fit would be to add this correlation to the model. However, there are other ways to accommodate this suggestions. Rather than allowing for a correlation between factors, it is possible to add secondary loadings of VC variables on the WM factor and vice versa. The MI for the correlation is often bigger because it combines modifications of several specific modifications. Thus, it is a theoretical choice which approach should be taken. One simple rule would be to add the correlation if all of the secondary loadings show the same trend and to allow for secondary loadings if the pattern is inconsistent. In this case, all of the VC variables showed a significant loading on the WM factor and I used these secondary loadings to modify the model.
There were only a few MI greater than 25 left. Two were correlated residuals of Arithmetic with Information and with Matrix Reasoning. Arithmetic was already complex and related to several specific factors. I therefore considered the possibility that this variable reflects several specific forms of cognitive abilities. The finding of correlated residuals suggested that even some of the unique variance of other variables is related to the Arithmetic task. To model this, I treated Arithmetic as a lower order construct that could be influenced by several of the other 14 variables. Exploration identified four variables that seemed to contribute uniquely to variance in the Arithmetic variable. I therefore removed Arithmetic as an indicator of specific factors and added it as a variable that is predicted by these four variables, namely Matrix-Reasoning, b = .32, Information, b = .28, Letter-Number-Sequencing, b = .18, and Digit Span, b = .13.
There was only one remaining MI greater than 25. This was a correlation between the PO-factor and the Information variable. Although the loading of Information on the PO factor did not meet the threshold, it would also improve model fit and be more interpretable. Thus, I added this parameter. The loading was weak, b = .12 and the value was not significant at the .01 level. The MI for the correlation between Information and the PO-factor was now below the 25 threshold. As this parameter is not really relevant, I decided to remove it and use this model as the final model. The fit of this final model met standard criteria of model fit, CFI = .990, RMSEA = .042. This fit is better than the fit of Brunner et al.’s hierarchical model, CFI = .970, RMSEA = .071, and their favored bi-factor model, CFI = .981, RMSEA = .060. While model fit cannot show that a model is the right model, model comparison suggests that models with worse fit are not the right model. This does not mean that these models are entirely wrong. Well-fitting models are likely to share some common elements. Thus, model comparison should not be based on a comparison of fit indices, but also compare the actual differences between the models. To make this comparison easy, I show how my model is similar and different to their model.

The Figure shows that key aspects of the two models are similar. One differences are a couple of weak secondary loadings of two VC variables on the WM factor. Including these parameters merely shows where the simpler model produces some misfit to the data. The second difference is the additional relationship between Object Assembly and Block Design. The models would look even more similar if this relationship were modeled by simply adding a correlated residual between these two variables. The interpretation is the same. There is some factor that influences performances on these two tasks, but not on the other 12 tasks. The biggest difference is the modeling of Arithmetic. In my model, Arithmetic shares variance with digit span and letter-Number Spacing and this shared variance includes variance that is explained by the WM factor and variance that is unique to these variables. In Brunner et al.’s model, Arithmetic is only related to the variance that is shared by Digit-Span, Letter-Number, not the unique variance of these two variables. In addition, my model shows even stronger relationships of Arithmetic with Information and Matrix Reasoning. These differences may have implications for theories about this specific task, but have no practical implications for theories that try to explain the general pattern of correlations. In conclusion, an exploratory structural equation modeling approach produces a hierarchical model that is essentially the same as a published model. Thus, conventions that prevent researchers from exploring their data with SEM are hindering scientific progress. One could argue that Brunner et al.’s hierarchical model is equally atheoretical and similarity merely shows that both models are wrong. To make this a valid criticism, intelligence researchers would have to specify a theoretical model and then demonstrate that it fits the data at least as well as my model. Merely claiming expertise in a substantive area is not enough. The strength of SEM is that it can be used to test different theories against each other. Eventually, more data will be needed to pit alternative models against each other. My model serves as a benchmark for other models even if it was created by looking at the data first. Developing theories of data is not wrong. In fact, it is not clear how one would develop a theory without having any data . And the worst practice in psychology is when researchers have theories without data and then look for data that confirm their theory and suppress contradictory evidence. This practice has led to the replication crisis in experimental social psychology.
Reliability and Measurement Error
Hierarchical factor analysis can be used to examine structures of naturally occurring objects (e.g., the structure of emotions, Shaver et al. 1987) or to examine the structure of man-made objects. CFA is often used for the latter purpose, when researchers examine the psychometric properties of measures that they created. In the present example, the 14 variables are not a set of randomly selected tasks. Rather, they were developed to measure intelligence. To be included as a measure of intelligence, a measure had to demonstrate that it correlates with other measures under the assumption that intelligence is a general factor that influences performance on a ranger of tasks. It is therefore not surprising that the 14 variables are strongly correlated and load on a common factor. The reason is that they were designed to be measures of this general factor. Moreover, intelligence researchers are not only interested in correlations among measures and factors. They also want to use these measures to assign scores to individuals. The assignment of scores to individuals is called assessment. Ideally, we would just look up individuals’ standing on the general factor, but this is not possible. A factor reflects shared variance among items, but we only know individuals standing on the observed variables , not the variance that is shared. To solve this problem, researchers average individuals’ scores on individual variables and use these sum-scores as a measure of individuals’ standing on the factor. The use of sum-scores creates measurement error because some of the variance in sum-scores reflects the variance in specific factors and the unique variances of the variables. Averaging across several variables can reduce measurement error because averaging reduces the influence of specific factors and residual variances. Brunner et al. (2020) discuss several ways to quantify the amount of construct variance (the g-factor) in sum-scores of the 14 items.
A simple way to explore this question is to add sum-scores to the model with a formative measurement model, where a new variable is regressed on the observed variables and the residual variance is fixed to zero. This new variable represents the variance in actual sum-scores and it is not necessary to actually create them and add them to the variable set. To examine the influence of the general factor, it is possible to use mediation analysis because the effect of the g-factor on the sum score is fully mediated by the 14 variables. This model shows that the standardized effect of the g-factor on the sum-scores is r = .96, which implies 92% of the variance is explained by the g-factor. It is also possible to examine the sources of the remaining 8% of variance that does not reflect the g-factor by examining mediated paths from the unique variances in the specific factors. The unique variance in the WM, PS, and PO factor explained no more than 1% each, but the unique VC variance explained 3% of the variance in sum scores. The remaining 2% can be attributed to unique variances in the 14 variables. Overall, these results suggest that the sum score is a good measure of the g-factor. This finding does not tell us what the g-factor is, but it does suggest that sum-scores are a highly valid measure of the g-factor.
The indirect path coefficients can be used to shorten a scale by eliminating variables that make a small contribution to the total effect. Following this approach I removed four variables, Arithmetic, Information, Comprehension, and Letter-Number Sequencing. The effect of the g-factor on this sum-score was as high, b = .96, as for the total scale. It is of course possible that this result is unique to this dataset, but the main point is that HFA can be used to determine the contribution of factors to sum scores in order to create measures and to examine their construct validity under the assumption that a factor corresponds to a construct (Cronbach & Meehl, 1955). To support the interpretation of factors, it is necessary to examine factors in relationship to other constructs, which also can be done using SEM. Moreover, evidence of validity is by no means limited to correlational evidence. Experimental manipulations can be added to an SEM model to demonstrate that a manipulation changes the intended construct and not some other factors. This cannot be done with sum scores because sum-scores combine valid construct variance and measurement error. As a result, validation of measures requires specification of a measurement model in which constructs are represented as factors and to demonstrate that factors are related to other variables as predicted.
Conclusion
This tutorial on hierarchical factor analysis was written in response to Brunner et al’s (2012) tutorial on hierarchically structured constructs. There are some notable differences between the two tutorials. First, Brunner et al. (2012) presented a hierarchical model without detailed explanations of the model. The model assumes that the 14 measures are first of all related to four specific factors and that the four specific factors are related to one general factor. This simple model implicitly assumes no secondary loadings and no additional relationships among first-order factors. These restrictive assumptions are unlikely to be true and often lead to bad fit. While Brunner et al. (2012) claim that their model has adequate fit, the RMSEA value of .071 is high and higher than the fit of the bi-factor model. Thus, this model should not be accepted without exploration of alternative models. The key difference between Brunner et al.’s tutorial and my tutorial is that Brunner et al. (2012) imply that their hierarchical model is the only possible hierarchical model that needs to be compared to models that do not imply a hierarchy like the bi-factor model. This restrictive view is shared with authors who claim simple CFA models should not include correlated residuals or secondary loadings. I reject this confirmatory straight-jacked that is unrealistic and leads to low fit. I illustrate how hierarchical models can be created that actually fit data. While this approach is exploratory, it has the advantage that it can produce theoretical models that actually fit data. These models can then be tested in future studies. Another difference between the two tutorials is that I present a detailed description of the process of building a hierarchical model. This process is often not explicitly described because CFA is presented a tool that examines the fit between an a priori theory and empirical data. Looking at the data and making a model fit data is often considered cheating. However, it is only cheating when authors fail to disclose that retrofitting of a model. Honest exploratory work is not cheating and is an integral part of science. After all, it is not clear how scientists could develop good theories in the absence of data that constrain theoretical predictions.
Another common criticism of factor models in general is that factor models imply causality while the data are only correlational. First of all, experimental manipulations can be added to models to validate factors, but sometimes this is not possible. For example, it is not clear how researchers could manipulate intelligence to validate an intelligence measure. Even if such manipulations were possible , the construct of intelligence would be represented by a latent variable. Some psychologists are reluctant to accept that factors correspond to causes in the real world. Even these skeptics have to acknowledge that test scores are real and something caused some individuals to provide a correct answer whereas others did not. This variance is real and it was caused by something. A factor first of all shows that the causes that produce good performance on one task are not independent of the causes of performance on another task. Without using the loaded term intelligence, the g-factor merely shows that all of the 14 have some causes in common. The presence of a g-factor does not tell us what this cause it, nor does it mean that there is a single cause. It is well-known that factor analysis does not reveal what a factor is and that factors may not measure what they were designed to measure. However, factors show which observed measures are influenced by shared causes when we can rule out the possibility of a direct relationship. That is, doing well on one one task does not cause participants to do well on another task. In a hierarchical model, higher-order factors represent causes that are shared among a large number of observed measures. Lower-order factors represent causes that are shared by a smaller number of factors. Observed measures that are related to the same specific factor are more likely to have a stronger relationship because they share more causes.
In conclusion, I hope that this tutorial encourages more researchers to explore their data using hierarchical factor analysis and to look at their data with open eyes. Careful exploration of the data may reveal unexpected results that can stimulate thoughts and propose new theories. The development of new theories that actually fit data may help to overcome the theory crisis in psychology that is based on an unwillingness and inability to falsify old and false theories. The progress of civilizations is evident in the ruins of old ones. The lack of progress in psychology is evident in the absence of textbook examples of ancient theories that have been replaced by better ones.