
Over the past decade, questions have been raised about research practices in psychology and the replicability of published results. The focus has been mostly on research practices in social psychology. A major replication project found that only 25% of results in social psychology could be replicated (Open Science Collaboration, 2015). This finding has produced a lot of conflicting responses that blame the replication project for the low success rate to claims that most results in social psychology are false positives.
Social psychology journals have responded to concerns about the replicability of social psychology with promises to improve the reporting of results. The European Journal of Social Psychology (EJSP) is no exception. In 2015, the incoming editors Radmila Prislin and Vivian L. Vignoles wrote
“we believe that scientific progress requires careful adherence to the highest standards of integrity and methodological rigour. In this regard, we welcome recent initiatives to improve the trustworthiness of research in social and personality psychology”
In 2018, the new editorial team, Roland Imhoff, Joanne Smith, Martijn van Zomeren, addressed concerns about questionable research practices more directly.
“opening up also implies being considerate of empirical imperfections that would otherwise remain hidden from view. This means that we require authors to provide a transparent description of the research process in their articles (e.g., report all measures,manipulations,
and exclusions from samples, if any; e.g., Simmons, Nelson, & Simonsohn, 2011). We thus encourage authors to accurately report about the inclusion of failed studies and imperfect patterns (e.g., p-values not meeting the .05 threshold), but this also has to mean that disclosing such imperfections, all else being equal, should not affect the likelihood of acceptance.”
This blog post uses the test-statistics published in EJSP to examine whether research practices of authors who publish in EJSP have changed in response to the low replicability of results in social psychology. To do so, I downloaded articles from 2000 to 2019 and automatically extracted test-statistics (t-values, F-values). I then converted these test-statistics into two-sided p-values and then into absolute z-scores. Higher z-scores provide stronger evidence against the null-hypothesis. These z-scores are then analyzed using z-curve (Brunner & Schimmack, 2019; Bartos & Schimmack, 2019). Figure 1 shows the results for the z-curve plot for all 27,223 test statistics.

Visual inspection shows a cliff at z = 1.96, which corresponds to a p-value of .05, two-sided. The grey curve shows the expected distribution based on the published significant results. The z-curve predicts many more non-significant results than are actually reported, especially below a value of 1.65 that represents the implicit criterion for marginal significance, p = .05, one-sided.
A formal test of selective reporting of significant results compares the observed discovery rate and the expected discovery rate. The observed discovery rate (ODR) is the percentage of reported results that are significant. The expected discovery rate (EDR) is the percentage of significant results that is expected given the z-curve model. The ODR of 72%, 95%CI = 72%-73%. This is much higher than the EDR of 26%, 95%CI = 19% to 40%. Thus, there is clear evidence of selective reporting of significant results.
Z-curve also provides an estimate of the expected replication rate. That is, if the studies were replicated exactly, how many of the significant results in the original studies would be significant again in the exact replication studies. The estimate is 70%, 95%CI = 65% to 73%. This is not a bad replication rate, but the problem is that it requires exact replications that are difficult if not impossible to do in social psychology. Bartos and Schimmack (2020) found that the EDR is a better predictor of results for conceptual replication studies. The estimate of 26% is consistent with the low replication rate in the replication project (Open Science Collaboration, 2015).
Fortunately, it is not necessary to dismiss all published results in EJSP. Questionable practices are more likely to produce just-significant results. It is therefore possible to focus on more credible results with a p-value less than .005, which corresponds to a z-score of 2.8. Figure 2 shows the results.

Based on the distribution of z-scores greater than 2.8, the model predicts much fewer just-significant results than are reported. This also suggests that questionable practices were used to produce significant results. Excluding these articles boosts the EDR to a satisfactory level of 77%. Thus, even if replication studies are not exact, the model predicts that most replication studies would produce a significant result with alpha = .05 (that is, the significance criterion was not adjusted to a more stringent level of .005).
The following analysis examines whether EJSP editors were successful in increasing the credibility of results published in their journal. For this purpose, I computed the ERR (solid) and the EDR (dotted) using all significant results (black) and excluding questionable results (grey) for each year and plotted the results as a function of year.
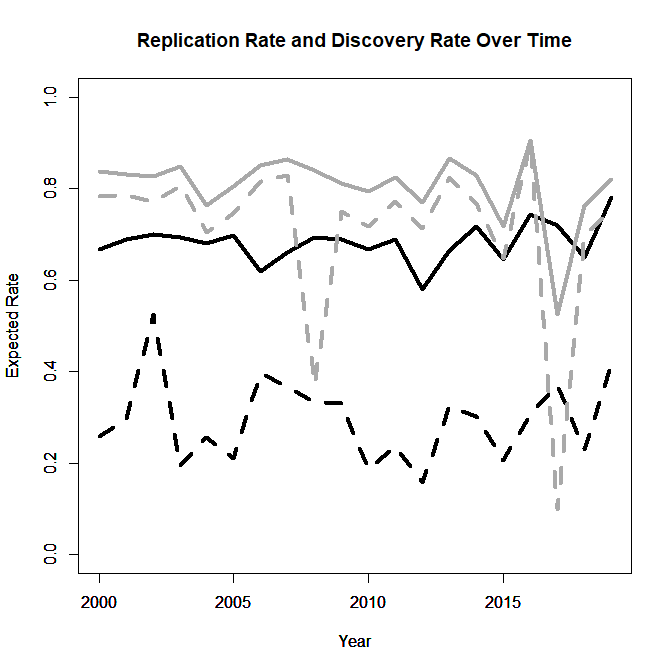
The results show no statistically significant trend for any of the four indicators over time. The most important indicator that reflects the use of questionable practices is the EDR for all significant results (black dotted line). The low rates in the last three years show that there have been now major improvements in the publishing culture of EJSP. It is surely easier to write lofty editorials than to actually improve scientific practices. Readers who care about social psychology are advised to ignore p-values greater than .005 because these results may have been produced with questionable practices and unlikely to replicate. The current editorial team may take these results as a baseline for initiatives to improve the credibility of EJSP in the following years.