
I published my first article in the Journal of Cross-Cultural Psychology (JCCP) and I continued to be interested in cross-cultural psychology. My most highly cited article, is based on a cross-cultural study with junior psychologists collecting data from the US, Mexico, Japan, Ghana, and Germany. I still remember how hard it was to collect cross-cultural data. Although this has become easier with the invention of the Internet, cross-cultural research is still challenging. For example, demonstrating that an experimental effect is moderated by culture requires large samples to have adequate power.
Over the past decades, questions have been raised about research practices in psychology and the replicability of published results. The focus has been mostly on social and cognitive psychological research in the United States or Western countries. A major replication project found that only 25% of results in social psychology could be replicated (Open Science Collaboration, 2015). Given the additional challenges in cross-cultural research, it is possible that the replication rate of results published in JCCP is even lower. (Milfont & Klein, 2018) discuss the implications of the replication crisis in social psychology for cross-cultural psychology, but their article focuses on challenges in conducting replication studies in cross-cultural psychology. The aim of this blog post is to examine the replicability of original results published in JCCP. A replicability analysis of original results is useful and necessary because it is impossible to replicate most original studies. Thus, cross-cultural psychology benefits more from ensuring that original results are trustworthy and replicable rather than mistrusting all original results until they have been replicated.
To examine the credibility of original results, my colleagues and I have developed a statistical tool, z-curve, that makes it possible to estimate the replication rate and the discovery rate in a set of original studies on the basis of the published test-statistics (t-values, F-values) (Brunner & Schimmack, 2019; Bartos & Schimmack, 2020).
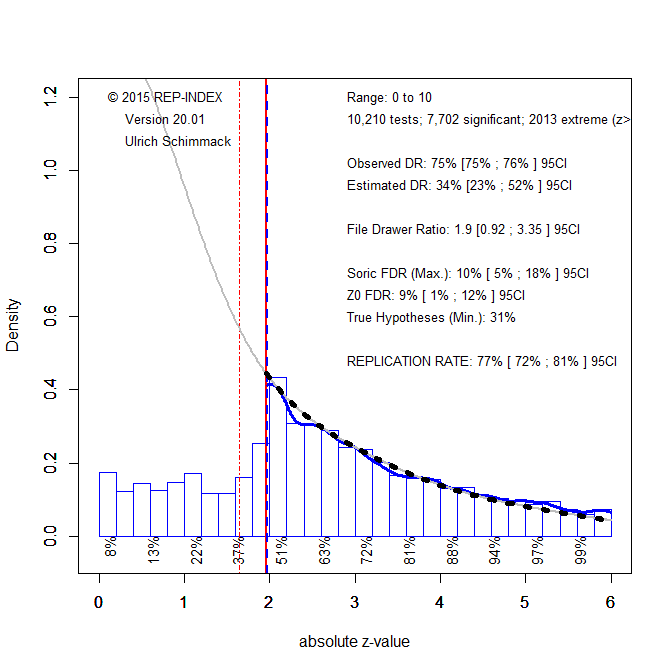
To apply z-curve to results published in JCCP, I downloaded all articles from 2000 to 2019 and automatically extracted all test-statistics (t-values, F-values) that were reported in the articles. Figure 1 shows the results for 10,210 test-statistics.
Figure 1 shows a histogram of the test-statistics that are converted into two-sided p-values and then converted into absolute z-scores. Higher z-scores show stronger evidence against the null-hypothesis that there is no effect. Visual inspection shows a steep increase in reported test-statistics around a z -score of 1.96 that corresponds to a p-value of .05, two-sided. This finding reflects the pervasive tendency in psychology to omit non-significant results from publications (Sterling, 1959; Sterling et al., 1995).
Quantitative evidence of selection for significance is provided by a comparison of the observed discovery rate (how many reported results are significant) and the expected discovery rate (how many significant results are expected based on the z-curve analysis; grey curve). The observed discovery rate of 75%, 95%CI 75% to 76%, is significantly higher than the expected discovery rate of 34%, 95%CI = 23%-52% (significance = confidence intervals do not overlap).
Z-curve also produces an estimate of the expected replication rate. That is, if studies were replicated exactly with the same sample sizes, 77% of the significant results are expected to be significant again in the replication attempt. This estimate is reassuring, but there is a caveat. The estimate assumes that studies can be replicated exactly. This is more likely to be the case for simple studies (e.g., a Stroop task with American undergraduates) than for cross-cultural research. When studies are conceptual replications with uncertainty about the essential features that influence effect sizes (e.g., recruiting participants from different areas in a country), the discovery rate is a better predictor of actual replication outcomes (Bartos & Schimmack, 2020). The estimate of 34% is not very assuring and closer to the actual replication rate of actual social psychology studies.
This does not mean that cross-cultural psychologists need to distrust all published results and replicate all previous studies. It is possible to use z-curve to identify results that are more likely to replicate and provide a solid foundation for future research. The reason is that replicability increases with the strength of evidence; larger z-scores are more replicable. Figure 2 excludes just significant results that may have been obtained with questionable research practices from the z-curve analysis. Although the criterion value is arbitrary, a value of 2.8 corresponds to a p-value of .005, that has been advocated as a better criterion for significance. I believe this is sensible when questionable research practices were used.
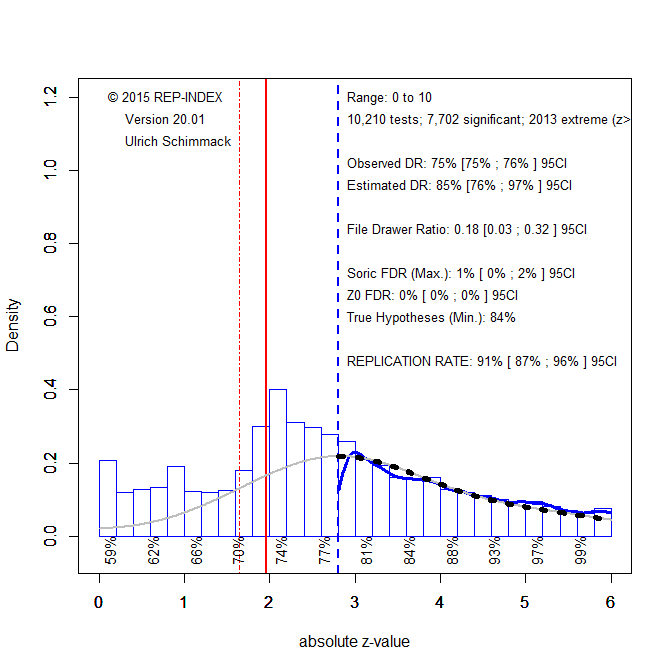
The z-curve model now predicts fewer just-significant results than are actually reported. This suggests that questionable practices were used to report significant results. Based on the model, about a third of these just-significant results is questionable, and the percentage for results with p-values of .04 and .03 (z = 2 to 2.2) is 50%. Given the evidence that questionable practices were used, readers should ignore these results unless other studies show stronger evidence for an effect. Replicability for results with z-scores greater than 2.8 is 91%. Thus, these results are likely to replicate. Thus, a simple way to address concerns about a replication crisis i n cross-cultural psychology is to adjust the significance criterion retroactively and to focus on p-values less than .005.
It is also important to examine how often articles in cross-cultural psychology report false positive results. The maximum number of false positive results can be estimated from the discovery rate (Soric, 1989). In Figure 2, this estimate is close to zero. Even in Figure 1, where questionable results lower the discovery rate, the estimate is only 20%. Thus, there is no evidence that JCCP published an abundance of false positive results. Rather, the problem is that most hypotheses in cross-cultural research appear to be true hypotheses and that non-significant results are false negatives. This makes sense as it is unlikely that culture has absolutely no effect, which makes the nil-hypothesis a priori implausible. Thus, cross-cultural researchers need to make riskier predictions about effect sizes and they need to conduct studies with higher power to avoid false negative results.
Figure 3 examines time-trends in cross-cultural research by computing the expected discovery rate (ERR, solid) and the expected discovery rate (EDR, dotted) using all significant results (grey) and excluding z-scores below 2.8 (grey). Time trends would reveal changes in the research culture of cross-cultural psychologists.

Simple linear regressions showed no significant time-trends for any of the four measures. ERR estimates are high, while EDR estimates for all significant results are low. There is no indication that research practices changed in response to concerns about a replication crisis. Thus, readers should continue to be concerns about just-significant results. Editors and reviewers could improve the trustworthiness of results published in JCCP by asking for pre-registration and by allowing publication of non-significant results if studies have sufficient power to test a meaningful hypothesis. Results should always be reported with effect sizes and sampling error so that it is possible to examine the range of plausible effect sizes. Significance should not always be evaluated against the nil-hypothesis but also against criteria for a meaningful effect size.
In conclusion, there is no evidence that most published results in JCCP are false positives or that most results published in the journal cannot be replicated. There is, however, evidence that questionable practices are used to publish too many significant results and that non-significant results are often obtained because studies had insufficient power. Concerns about low power are decades old (Cohen, 1962) and haven’t changed research practices in psychology. A trend analysis showed that even the replication crisis in social psychology has not changed research practices in cross-cultural psychology. It is time for cross-cultural psychologists to increase the power of their studies and to report all of the results honestly even if they do not confirm theoretical predictions. Publishing only results that confirm predictions renders empirical data meaningless.