Everybody knows the saying “Lies, damn lies, and statistics” But it is not the statistics; it is the ab/users of statistics who are distorting the truth. The Association for Psychological Science (APS) is trying to hide the truth that experimental psychologists are not using scientific methods in the way they are supposed to be used. These abnormal practices are known as questionable research practices (QRPs). Surveys show that researchers are aware that these practices have negative consequences, but they also show that these practices are being used because they can advance researchers careers (John et al., 2012). Before 2011, it was also no secrete that these practices were used and psychologists might even brag about the use of QRPs to get results (it took me 20 attempts to find this significant result).
However, some scandals in social psychology (Stapel, Bem) changed the perception of these practices. Hiding studies, removing outliers selectively, or not disclosing dependent variables that failed to show the predicted result was no longer something anybody would admit doing in public (except a few people who paid dearly for it; e.g. Wansink).
Unfortunately for abnormal psychological scientists, some researchers, including myself, have developed statistical methods that can reveal the use of questionable research practices and applications of these methods show the use of QRPs in numerous articles (Greg Francis; Schimmack, 2012). Francis (2014) showed that 80% or more of articles in the flagship journal of APS used QRPs to report successful studies. He was actually invited by the editor of Psychological Science to audit the journal, but when he submitted the results of his audit for publication, the manuscript was rejected. Apparently, it was not significant enough to tell readers of Psychological Science that most of the published articles in Psychological Science are based on abnormal psychological science. Fortunately, the results were published in another peer-reviewed journal.
Another major embarrassment for APS was the result of a major replication project of studies published in Psychological Science, the main APS journal, as well as two APA (American Psychological Association) journals (Open Science Collaboration, 2015). The results showed that only 36% of significant results in original articles could be replicated. The “success rate” for social psychology was even lower with 25%. The main response to this stunning failure rate have been attempts to discredit the replication studies or to normalize replication failures as a normal outcome of science.
In several blog posts and manuscripts I have pointed out that the failure rate of social psychology is not the result of normal science. Instead, replication failures are the result of abnormal scientific practices where researchers use QRPs to produce significant results. My colleague Jerry Brunner developed a statistical method, z-curve, that reveals this fact. We have tried to publish our statistical method in an APA journal (Psychological Methods) and the APS journal, Perspectives on Psychological Science, where it was desk-rejected by Sternberg, who needed journal space to publish his own editorials [he resigned after a revolt form APS members, including former editor Bobbie Spellman].
Each time our manuscript was rejected without any criticism of our statistical method. The reason was that it was not interesting to estimate replicability of psychological science. This argument makes little sense because the OSC reproducibility article from 2015 has already been cited over 500 times in peer-reviewed journals (WebofScience).
The argument that our work is not interesting is further undermined by a recent article published in the new APS journal Advances in Methods and Practices in Psychological Science with the title “The Prior Odds of Testing a True Effect in Cognitive and Social Psychology” The article was accepted by the main editor Daniel J. Simons, who also rejected our article as irrelevant (see rejection letter). Ironically, the article presents very similar analyses of the OSC data and required a method that could estimate average power, but the authors used an ad-hoc approach to do so. The article even cites our pre-print, but the authors did not contact us or run the R-code that we shared to estimate average power. This behavior would be like eyeballing a scatter plot rather than using a formula to quantify the correlation between two variables. It is contradictory to claim that our method is not useful and then accept a paper that could have benefited from using our method.
Why would an editor reject a paper that provides an estimation method for a parameter that an accepted paper needs to estimate?
One possible explanation is that the accepted article normalizes replication failures, while we showed that these replication failures are at least partially explained by QRPs. First evidence for the normalization of abnormal science is that the article does not cite Francis (2014) or Schimmack (2012) or John et al.’s (2012) survey about questionable research practices. The article also does not mention Sterling’s work on abnormally high success rates in psychology journals (Sterling, 1959; Sterling et al., 1995). It does not mention Simmons, Nelson, and Simonsohn’s (2011) False-Positive Psychology article that discussed the harmful consequences of abnormal psychological science. The article simply never mentions the term questionable research practices. Nor does it mention the “replication crisis” although it mentions that the OSC project replicated only 25% of findings in social psychology. Apparently, this is neither abnormal nor symptomatic of a crisis, but just how good social psychological science works.
So, how does this article explain the low replicability of social psychology as normal science? The authors point out that replicability is a function of the percentage of true null-hypothesis that are being tested. As researchers conduct empirical studies to find out which predicts are true and which predicts are not, it is normal science to sometimes predict effects that do not exist (true null-hypotheses), and inferential statistics will sometimes lead to the wrong conclusion (type-I errors / false positives). It is therefore unavoidable that empirical scientists will sometimes make mistakes.
The question is how often they make these mistakes and how they correct them. How many false-positives end up in the literature depends on several other factors, including (a) the percentage of null-hypothesis that are being tested and (b) questionable research practices.
The key argument in the article is that social psychologists are risk-takers and test many false hypothesis. As a result, they end up finding many false positive results. Replication studies are needed to show which findings are true and which findings are false. So, doing risky exploratory studies followed by replication studies is good science. In contrast, cognitive psychologist are not risk-takers and test hypothesis that have a high probability of being true. Thus, they have fewer false positives, but that doesn’t mean they are better scientists or social psychologists are worse scientists. In the happy place of APS journals, all psychological scientists are good scientists.
Conceivably, social psychologists place higher value on surprising findings—that is, findings that reflect a departure from what is already known—than cognitive psychologists do.
There is only one problem with this happy story of psychological scientists working hard to find the truth using the best possible scientific methods. It is not true.
How Many Point-Nil-Hypothesis are True
How often is the null-hypothesis true? To answer this question it is important to define the null-hypothesis. A null-hypothesis can be any point or a range of effect sizes. However, psychologists often wrongly use the term null-hypothesis to refer to the point-nil-hypothesis (cf. Cohen, 1994) that there is absolutely no effect (e.g., the effect of studying for a test AFTER the test has already happened; Bem, 2011). We can then distinguish two sets of studies. Studies with an effect of any magnitude and studies without an effect.
The authors argue correctly that testing many null-effects will result in more false positives and lower replicability. This is easy to see, if all significant results are false positives (Bem, 2011). The probability that any single replication study produces a significant result is simply alpha (5%) and for a set of studies only 5% of studies are expected to produce a significant result. This is the worst case scenario (Rosenthal, 1979; Sterling et al., 1995).
Importantly, this does not only apply to replication studies. It also applies to original studies. If all studies have a true effect size of zero, only 5% of studies should produce a significant result. However, it is well known that the success rate in psychology journals is above 90% (Sterling, 1959; Sterling et al., 1995). Thus, it is not clear how social psychology can test many risky hypothesis that are often false and report over 90% successes in their journal or even within a single article (Schimmack, 2012). The only way to achieve this high success rate while most hypothesis are false is by reporting only successful studies (like a gambling addict who only counts wins and ignores losses; Rosenthal, 1979) or to make up hypothesis after randomly finding a significant result (Kerr, 1998).
To my knowledge, Sterling et al. (1995) were the first to relate the expected failure rate (without QRPs) to alpha, power, and the percentage of studies with and without an effect.

Sterling et al. point out that we should not have expected that 100% of published results in the Open Science Collaboration reported significant results, while the 25% success rate in the replication studies is shockingly low, but at least more believable than the 100% success rate. The article neither mentions Sterling’s statistical contribution, nor the implication for the expected success rate in original studies.
The main aim of the authors is to separate the effects of power and the proportion of studies without effects on the success rate; that is the percentage of studies with significant results.
For example, a 25% success rate for social psychology could be produced by 25 studies with 85% power and 75% of studies without an effect (and a 5% chance of producing a significant result) or it could be produced by 100 studies with an average of 25% power, or any other percentage of studies with an effect between 25% and 100%.
As pointed out by Brunner and Schimmack (2017), it is impossible to obtain a precise estimate of this percentage because different mixtures of studies can produce the same success rate. I was therefore surprised when the abstract claimed that “we found that R was lower for the social-psychology studies than for the cognitive-psychology studies” How were the authors able to quantify and compare the proportions of studies with an effect in social psychology versus cognitive psychology? The answer is provided in the following quote.
Using binary logic for the time being, we assume that the observed proportion of studies yielding effects in the same direction as originally observed, ω, is equal to the proportion of true effects, PPV, plus half of the remaining 1 – PPV noneffects, which would be expected to yield effects in the same direction as originally observed 50% of the time by chance.
To clarify, a null-result is equally likely to produce a positive or a negative effect size by chance. A sign reversal in a replication study is used to infer that the original result was a false positive. However, these sign reversals are only half of the false positives because random chance is equally likely to produce the same sign (head-tail is equally probable as head-head). Using this logic, the percentage of sign reversals times two is an estimate of the percentage of false positives in the original studies.
Based on the finding that 25.5% of social replication studies showed a sign reversal, the authors conclude that 51% of the original significant results were false positives. This would imply that every other significant result that is published in social psychology journals is a false positive.
One problem with this approach is that sign reversals can also occur for true positive studies with low power (Gelman & Carlin, 2014). Thus, the percentage of sign reversals is at best a rough estimate of false positive results.
However, low power can be the result of small effect sizes and many of these effect sizes might be so close to zero that they can be considered false positives if the null-hypothesis is defined as a range of effect sizes close to zero.
So, I will just use the authors estimate of 50% false positive results as a reasonable estimate of the percentage of false positive results that are reported in social psychology journals.
Are Social Psychologists Testing Riskier Hypotheses?
The authors claim that social psychologists have more false positive results than cognitive psychologists because they test more false hypotheses. That is, they are risk takers:
Maybe watching a Beyoncé video reduces implicit bias? Let’s try it (with n = 20 per cell in a between-subject design). It doesn’t and the study produced a non-significant result. Let’s try something else. After trying many other manipulations, finally a significant result is observed and published. Unfortunately, this manipulation also had no effect and the published result is a false positive. Another researcher replicates the study and obtains a significant result with a sign reversal. The original result gets corrected and the search for a true effect continues.
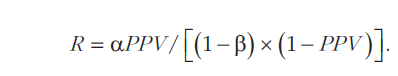
To make claims about the ratio of studies with effects and studies without effects (or negligible effects) that are being tested, the authors use the formula shown above. Here the ratio (R) of studies with an effect over studies without an effect is a function of alpha (the criterion for significance), beta (type-II error probabilty), and PPV; the positive predictive value, which is simply the percentage of true positive significant results in the published literature.
As note before, the PPV for social psychology was estimated to be 49%. This leaves two unknowns to make claims about R; alpha and beta. The authors approach to estimating alpha and beta is questionable and undermines their main conclusion.
Estimating Alpha
The authors use the nominal alpha level as the probability that a study without a real effect produces a false positive result.
Social and cognitive psychology generally follow the same convention for their alpha level (i.e., p < .05), so the difference in that variable likely does not explain the difference in PPV.
However, this is a highly questionable assumption when researcher use questionable research practices. As Simonsohn et al. (2011) demonstrated p-hacking can be used to bypass the significance filter and the risk of reporting a false positive result with a nominal alpha of 5% can be over 50%. That is, the actual risk of reporting a false positive result is not 5% as stated, but much higher. This has clear implications for the presence of false positive results in the literature. While it would require 20 risky hypotheses to observe a false positive result with a significance filter of 5%, p-hacking makes it possible to report every other false positive result as significant. Thus, massive p-hacking could explain a high percentage of false positive results in social psychology just as well as honest testing of risky hypotheses.
The authors simply ignore this possibility when they use the nominal alpha level as the factual probability of a false positive result and neither the reviewers nor the editor seemed to realize that p-hacking could explain replication failures.
Is there any evidence that p-hacking rather than risk-taking explains the results? Indeed, there is lots of evidence. As I pointed out in 2012, it is easy to see that social psychologists are using QRPs because they typically report multiple conceptual replication studies in a single article. Many of the studies in the replication project were selected from multiple study articles. A multiple study article essentially lowers alpha from .05 in a single study to .05 raised to the power of the number of studies. Even with just two studies, the risk of repeating a false positive result is just .05^2 = .0025. And none of these multiple study articles report replication failures, even if the tested hypothesis is ridiculous (Bem, 2011). There are only two explanation for the high success rate in social psychology. Either they are testing true hypothesis and the estimate of 50% false positive results is wrong or they are using p-hacking and the risk of a false positive results in a single study is greater than the nominal alpha. Either explanation invalidates the authors conclusions about R. Either their PPV estimates are wrong or their assumptions about the real alpha criterion are wrong.
Estimating Beta
Beta or the type-II error is the risk of obtaining a non-significant result when an effect exists. Power is the complementary probability of getting a significant result when an effect is present (a true positive result). The authors note that social psychologists might end up with more false positive results because they conduct studies with lower power.
To illustrate, imagine that social psychologists run 100 studies with an average power of 50% and 250 studies without an effect and due to QRPs 20% of these studies produce a significant result with a nominal alpha of p < .05. In this case, there are 50 true positive results (100 * .50 = 50) and 50 false positive results (250 * .20 = 50). In contrast, cognitive psychologists conduct studies with 80% power, while everything else is the same. In this case, there would be 80 true positive results (100 * .8 = 80) and also 50 false positive results. The percentage of false positives would be 50% for social, but only 50/(50+80) = 38% false positives for cognitive psychology. In this example, R and alpha are held constant, but the PPVs differ simply as a function of power. If we assume that cognitive psychologists use less severe p-hacking, there could be even fewer false positives (250 * .10 = 25) and the PPV for cognitive psychology would be only 24%. [actual estimate in the article is 19%]
Thus, to make claims about differences between social psychologists and cognitive psychologists, it is necessary to estimate beta or power (1 – beta) and because power varies across the diverse studies in the OSC project, they have to estimate average power. Moreover, because only significant studies are relevant, they need to estimate the average power after selection for significance. The problem is that there exists no published peer-reviewed method to do this. The reason why no published peer-reviewed method exists is that editors have rejected our manuscripts that have evaluated four different methods of estimating average power after selection for significance and shown that z-curve is the best method.
How do the authors estimate average power after selection for significance without z-curve? They use p-curve plots and use visual inspection of the plots against simulations of data with fixed power to obtain rough estimates of 50% average power for social psychology and 80% average power for cognitive psychology.
It is interesting that the authors used p-curve plots, but did not use the p-curve online app to estimate average power. The online p-curve app also provides power estimates. However, we pointed out in the rejected manuscript, this method can severely overestimate average power. In fact when the online p-curve app is used, it produces estimates of 96% average power for social psychology and 98% for cognitive psychology. These estimates are implausible and this is the reason why the authors created their own ad-hoc method of power estimation rather than using the estimates provided by the p-curve app.
We used the p-curve app and also got really high power estimates that seemed implausible, so we used ballpark estimates from the Simonsohn et al. (2014) paper instead (Brent Wilson, email communication, May 7, 2018).
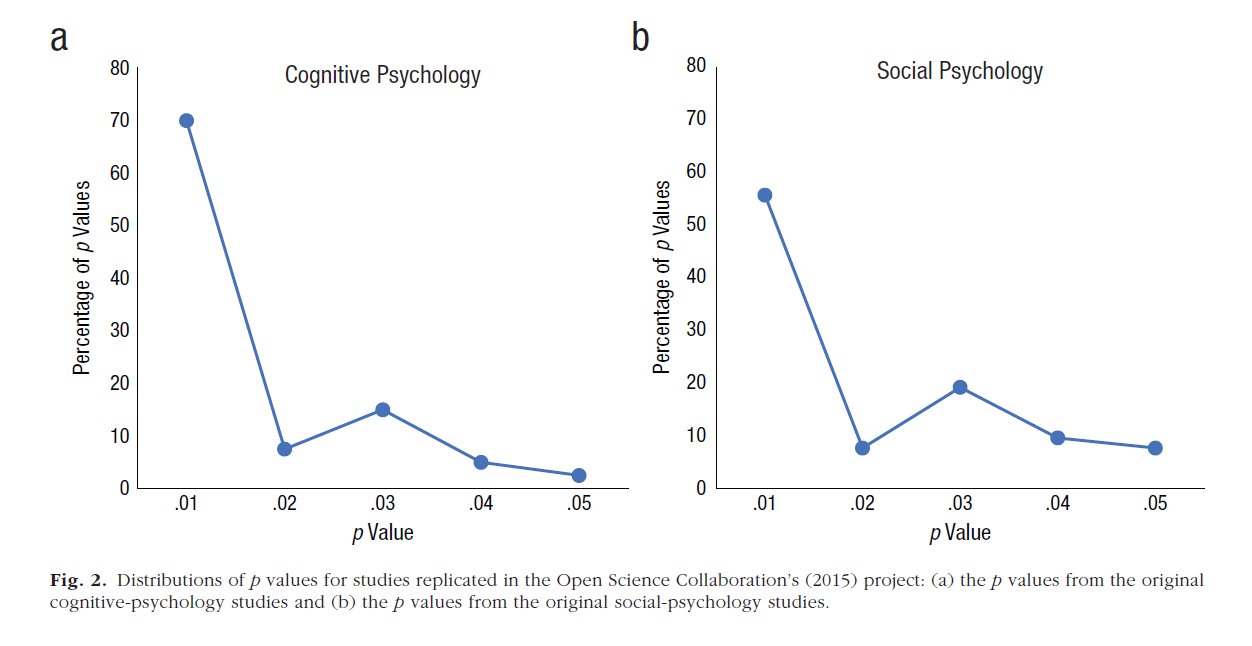 Based on their visual inspection of the graphs they conclude that the average power in social psychology is about 50% and the average power in cognitive psychology is about 80%.
Based on their visual inspection of the graphs they conclude that the average power in social psychology is about 50% and the average power in cognitive psychology is about 80%.
Putting it all together
After estimating PPV, alpha, and beta in the way described above, the authors used the formula to estimate R.
If we set PPV to .49, αlpha to .05, and 1 – β (i.e., power) to .50 for the social-psychology
studies and we set the corresponding values to .81, .05, and .80 for the cognitive-psychology studies, Equation 2 shows that R is .10 (odds = 1 to 10) for social psychology
and .27 (odds = 1 to ~4) for cognitive psychology.
Now the authors make another mistake. The power estimate obtained from p-curve applies to ALL p-values, including the false positive ones. Of course, the average estimate of power is lower for a set of studies that contains more false positive results.
To end up with 50% average power with 50% false positive results, the power of the studies that are not false positives can be computed with the following formula.
Avg.Power = FP*alpha + TP*power <=> power = (Avg.Power – FP*alpha)/TP
With 49% true positives (TP), 51% false positives (FP), alpha = .05, and average power = .50 for social psychology, the estimated average power of studies with an effect is 97%.
alpha = .05; avg.power = .50; TP = .49; FP = 1-TP; (avg.power – FP*alpha)/TP
With 81% true positives and 80% average power for cognitive psychology, the estimated average power of studies with an effect in cognitive psychology is 98%.
Thus, there is actually no difference in power between social and cognitive psychology because the percentage of false positive results alone explains the differences in the estimates of average power for all studies.

alpha = .05; PPV = .49; power = .96; alpha*PPV/(power * (1-PPV))
alpha = .05; PPV = .81; power = .97; alpha*PPV/(power * (1-PPV))
With these correct estimates of power for studies with true effects, the estimate for social psychology is .05 and the estimate for cognitive psychology is .22. This means the social psychologists test 20 false hypothesis for every true hypothesis, while cognitive psycholgists test 4.55 false hypothesis for every correct hypothesis, assuming the authors assumptions are correct.
Conclusion
The authors make some questionable assumptions and some errors to arrive at the conclusion that social psychologists are conducting many studies with no real effect. All of these studies are run with a high level of power. When a non-significant result is obtained, they discard the hypothesis and move on to testing another one. The significance filter keeps most of the false hypothesis out of the literature, but because there are so many false hypothesis, 50% of the published results end up being false positives. Unfortunately, social psychologists failed to conduct actual replication studies and a large pile of false positive results accumulated in the literature until social psychologists realized that they need to replicate findings in 2011.
Although this is not really a flattering description of social psychology, the truth is worse. Social psychologists have been replicating findings for a long time. However, they never reported studies that failed to replicate earlier findings and when possible they used statistical tricks to produce empirical findings that supported their conclusions with a nominal error rate of 5%, while the true error rate was much higher. Only scandals in 2011 led to honest reporting of replication failures. However, these replication studies were conducted by independent investigators, while researchers with influential theories tried to discredit these replication failures. Nobody is willing to admit that abnormal scientific practices may explain why many famous findings in social psychology textbooks were suddenly no longer replicable after 2011, especially when hypotheses and research protocols were preregistered and prevented the use of questionable research practices.
Ultimately, the truth will be published in peer-reviewed journals. APS does not control all journals. When the truth becomes apparent, APS will look bad because it did nothing to enforce normal scientific practices and it will look worse because it tried to cover up the truth. Thank god , former APS president Susan Fiske reminded her colleagues that real scientists should welcome humiliation when their mistakes come to light because the self-correcting forces of science are more important than researchers feelings. So far, APS leaders seem to prefer repressive coping over open acknowledgment of past mistakes. I wonder what the most famous psychologists of all times would have to say about this.
“We have tried to publish our statistical method in an APA journal and two APS journals. Each time our manuscript was rejected without any criticism of our statistical method. The reason was that it was not interesting to estimate replicability of psychological science. This argument makes little sense because the OSC reproducibility article from 2015 has already been cited over 500 times.”
I have come to the conclusion that in Psychological Science it matters a lot who you are, who your friends are, and all kinds of other stuff that has nothing to do with the science itself. It’s one of the main reasons i do not want to be part of academia anymore.
I would not be surprised if the OSC paper (of which i just happen to be a co-author) got published in Science (and hence probably got a lot of extra attention, and subsequent citations, it would otherwise not have gotten) because of some of these possible kinds of forces at work.
As a side note: the OSC paper has been cited about 2000 times according to google scholar, and about 1000 times according to Researchgate.
Thank you for your comments. I used Web of Science for citation counts which is more conservative. I’ll add that information to clarify.
Why does this article not include a Reference list of citation?
Some citations have links but many do not.
Good point. I should add a reference list. Any particular reference you were looking for.