Draft: 25/04/17
Abstract
Subjective indicators of well-being have gained prominence as alternatives to purely economic or objective measures of quality of life. Among these, life satisfaction, positive affect (PA), and negative affect (NA) are commonly used and frequently combined under the label of subjective well-being (SWB). However, this article argues that these indicators reflect distinct philosophical traditions and should not be conflated. Life satisfaction is a subjective indicator in the normative sense—it allows individuals to evaluate their lives based on their own criteria. In contrast, PA and NA are rooted in hedonistic theories, where well-being is defined by affective experience. Although PA, NA, and life satisfaction are positively correlated, their conceptual differences raise important theoretical and methodological concerns about combining them into a single SWB index. The article reviews competing models, including the affective component model and the Underlying Sense of Well-Being (USWB) model, and evaluates empirical evidence linking personality, affect, and life satisfaction. It concludes that life satisfaction judgments provide unique information about individuals’ personal conceptions of the good life and should be treated as a distinct subjective social indicator, not merely as a proxy for hedonic experience or a component of SWB.
Subjective Indicators of Well-Being: Life Satisfaction, Positive Affect, Negative Affect
Social indicators emerged in the 1960s as an alternative to purely economic measures like Gross Domestic Product (GDP), which focus on monetary output, consumer choice, and desire fulfillment. These economic indicators often overlook key social factors—such as health, education, and community cohesion—that contribute to individual and collective well-being but fall outside the scope of the market economy.
To address this shortcoming, social scientists developed subjective indicators, also known as subjective social indicators. Michalos (2014) defined subjective indicators as “measures of the quality of life from the point of view of some particular subject” (p. 6427). In contrast, objective indicators are based on the assessment of an independent observer. Common examples of objective indicators include unemployment rates and life expectancy, whereas life satisfaction and perceived health are considered subjective indicators.
One challenge in social science is that terms like subjective are often used loosely and with varying meanings. This article addresses that issue by offering a theoretical discussion of the term subjective in the context of social indicators research. Specifically, I examine the meaning of subjective in Diener’s (1984) influential definition of subjective well-being (SWB), which includes three components: Positive Affect, Negative Affect, and Life Satisfaction. The aim of this discussion is not to propose a new theory of well-being or introduce a new subjective indicator. Rather, it is to argue that SWB is not a singular theoretical construct that can be measured and used as a unified social indicator. Instead, SWB indicators are rooted in different philosophical traditions that cannot easily be reconciled and require distinct measures.
Many social indicator researchers prioritize life satisfaction as a key subjective indicator of well-being. In the journal Social Indicators Research, more articles include life satisfaction as a keyword (k = 1,232) than Positive Affect and Negative Affect combined (k = 122). The dominance of life satisfaction over PA and NA is also evident in major research projects. For example, the German Socio-Economic Panel has included measures of life satisfaction and domain satisfaction since its inception in 1984, whereas affect measures were only added in 2007. Similarly, the World Happiness Report includes LS, PA, and NA, but prioritizes LS as the primary social indicator for international comparisons.
Not everyone agrees that life satisfaction is the superior subjective indicator. For instance, Nobel Laureate Daniel Kahneman (1999) argued that life satisfaction judgments are unreliable and biased. He proposed focusing on Positive and Negative Affect as more valid indicators. While Diener maintained that all three components—life satisfaction, positive affect, and negative affect—are important, he never clearly explained how these indicators should be used to assess well-being from a subjective standpoint (Busseri & Sadava, 2010).
Diener’s (1984) inclusion of PA, NA, and LS likely reflects the difficulty of defining happiness or well-being using a single concept or prioritizing one over another. That is the perspective I adopt in this review. Rather than advocating for a unified construct of SWB, I argue that hedonic (PA, NA) and evaluative (LS) indicators reflect different conceptions of well-being and should be treated as distinct subjective indicators. To support this position, I draw on philosophical contributions to the study of happiness—particularly Sumner’s (1996) excellent summary of diverse perspectives that influenced my thinking and helped shape the definition of well-being in my collaboration with Ed Diener (Diener, Lucas, Schimmack, & Helliwell, 2009). In that book, life satisfaction was treated as the ultimate measure of well-being. Here, I take a different stance: that there is no single, definitive concept of happiness or well-being. It is more fruitful to study well-being using multiple subjective indicators rooted in distinct philosophical traditions.
Here’s the follow-up, continuing from “Philosophical Traditions and Subjective Well-Being” through the end of that section. I’ll continue delivering the rest in clean, manageable sections for accuracy and readability:
Philosophical Traditions and Subjective Well-Being
Philosophers typically distinguish between three major approaches to defining well-being or happiness (Sumner, 1996). Interestingly, Diener’s (1984) seminal article already acknowledged these three traditions (p. 543). The first is the eudaimonic approach, rooted in Aristotle’s philosophy. Diener (1984) rejected this approach on the grounds that it is tied to a specific value framework, which may not be applicable across individuals or cultures. This does not mean that eudaimonic aspects of life are unimportant or should be excluded from social indicators. Rather, it means they are not subjective indicators, because they do not assess people’s lives from their own perspective. Instead, they represent objective indicators (Michalos, 2014; Sumner, 1996).
The second approach is rooted in hedonism and defines a good life solely in terms of the balance between Positive Affect (PA) and Negative Affect (NA) (Sumner, 1996). Although Diener does not explicitly refer to hedonism, he attributes this approach to Bradburn (1969), who developed one of the earliest post-war measures of affect balance. The classification of PA and NA as subjective or objective indicators is ambiguous. While Kahneman (1999) describes them as objective, Diener (1984) includes them as components of subjective well-being. Resolving this inconsistency—and its implications for how we measure subjective well-being—is one of the central aims of this article.
The third approach emerged with the rise of the social indicators movement and public opinion research, which asked individuals to evaluate their lives using global life satisfaction (LS) items. There is broad consensus that LS judgments are subjective indicators, as they require people to evaluate their lives based on their own internal standards. These standards are not imposed by the researcher or derived from an external theory of well-being. For some, these standards may be moral or value-based; for others, they may rest on the amount of pleasure or pain experienced.
If PA, NA, and LS are all treated as subjective indicators of well-being and measured separately, it becomes necessary to specify a measurement model that explains how this information should be combined or interpreted in social indicators research. If they are aggregated into a single SWB indicator, one must decide how to weight each component. If they are analyzed separately, it remains unclear how to interpret conflicting information—either for individual decision-making or policy development.
I argue that PA and NA should be combined into a single measure of hedonic balance, consistent with Bentham’s maxim that a good life maximizes pleasure and minimizes pain. Even here, questions remain about whether PA and NA should be weighted equally—an issue that lies beyond the scope of this article. The central point, however, is that hedonic balance and life satisfaction reflect different philosophical traditions. While both are important subjective indicators, they are conceptually distinct and should not be conflated in research or policy applications (Connolly & Gärling, 2024).
Subjective versus Objective Indicators
First, we can distinguish between different measurement approaches. Some indicators can be assessed objectively. For example, health can be measured through physiological tests or clinical evaluations. Other indicators rely on self-reports—for instance, participants might complete a checklist of physical symptoms to assess their health. Life satisfaction (LS), positive affect (PA), and negative affect (NA) are typically measured with self-ratings, but this method alone is not a meaningful criterion for distinguishing subjective from objective indicators of well-being. Objective indicators such as income or employment status are also often assessed through self-reports, simply because it is more cost-effective. Similarly, many eudaimonic measures of well-being rely on self-reports, but this does not make them subjective in the philosophical sense (Keyes, Shmotkin, & Ryff, 2002). Furthermore, LS, PA, and NA are sometimes measured using informant reports to demonstrate the convergent validity of self-ratings (Schneider & Schimmack, 2009; Zou, Schimmack, & Gere, 2013). In conclusion, the use of self-reports is not a valid basis for distinguishing subjective from objective social indicators.
A second meaning of the term subjective is that LS, PA, and NA depend on individual characteristics—such as personality traits, values, and goals—that differ between people. While the fulfillment of universal human needs contributes to well-being, it is not sufficient to determine it. Consequently, subjective well-being (SWB) requires that lives be evaluated from the perspective of the individuals who are living them. The same life (e.g., being married with children) may lead to happiness for one person and unhappiness for another. This is the essential meaning of subjective in Diener’s concept of SWB: “The term subjective well-being emphasizes an individual’s own assessment of his or her own life—not the judgment of ‘experts’” (Diener, Scollon, & Lucas, 2009, p. 68). All three components of SWB—LS, PA, and NA—are subjective in this sense, as affective experiences are shaped by the individual dispositions of those living their lives.
However, a third meaning of subjective is central to distinguishing between hedonistic and subjectivist theories of well-being (Sumner, 1996). Sumner classifies hedonism as an objective theory of well-being because it imposes a fixed criterion: that affective experience—specifically, the amount of PA and NA—is the sole standard for evaluating a good life. While hedonism acknowledges that affective experiences vary across individuals, it still insists that these experiences are the only relevant data for judging well-being. In this sense, hedonism is not subjective, because it does not allow people to determine for themselves how their lives should be evaluated.
The difference between hedonistic and subjectivist theories of well-being lies in timing. PA and NA are subjective experiences that vary across individuals while they live their lives. But once these experiences are used to evaluate lives as a whole, they are no longer subjective in the sense of reflecting an individual’s chosen criteria. Hedonism turns affect into a standard imposed on people’s lives. As Bentham famously claimed, “Nature has placed mankind under the governance of two sovereign masters, pain and pleasure.” Yet it is ultimately Bentham who defined well-being in this way—individuals living these lives may disagree, evaluating their well-being using other standards. Therefore, hedonism is not a subjective theory of well-being because it denies people the authority to define their own standards of evaluation.
Diener et al. (2009) recognize this distinction when they write, “Affect reflects a person’s ongoing evaluations of the conditions in his or her life” (p. 76). However, affective experiences are inherently situational and momentary; they are not evaluations of life as a whole. To use them as indicators of life quality, they must be aggregated over a meaningful period. The key claim of hedonism is that the average level of PA and NA reflects a person’s quality of life (Kahneman, 1999).
There is nothing inherently problematic about using PA and NA to define happiness in terms of hedonic balance. However, it is important to acknowledge that this definition may diverge from the life evaluations of the individuals themselves. People may report high life satisfaction despite moderate levels of PA or high levels of NA if their evaluations are based on other personally meaningful criteria.
Consider two hypothetical participants. Participant A reports a 5 on PA, 5 on NA, and 9 on LS. Participant B reports an 8 on PA, 2 on NA, and 6 on LS. From a hedonistic perspective, B has higher well-being. From a subjectivist perspective, A has higher well-being. Diener’s concept of SWB, which includes all three components but does not specify how they should be combined, leaves this ambiguity unresolved.
This ambiguity arises because LS and hedonic balance (PA–NA) reflect different conceptions of well-being. One reflects retrospective life evaluation, the other captures momentary affective experiences. Just as objective indicators (e.g., wealth, health, education) can diverge from subjective ones, LS and PA/NA can yield inconsistent results. This is only a problem when researchers attempt to collapse them into a single composite score that aims to represent an undefined construct of SWB (Busseri & Sadava, 2010).
A more productive approach is to distinguish between hedonistic and subjectivist theories of happiness and to create separate indicators that reflect each tradition. Doing so respects the philosophical diversity of well-being concepts and avoids the conceptual confusion that results from trying to unify fundamentally different constructs. It is also in line with some of Diener’s later writing on this topic. Diener, Lucas, and Oishi (2018) note, “One important distinction in the conceptualization of SWB focuses on the contrast between more cognitive, judgment-focused evaluations like life satisfaction and more affective evaluations that are obtained when asking about a person’s typical emotional experience” (p. 4). This does not preclude the creation of a SWB indicator, but it does encourage the study of the components separately.
Life Satisfaction is Not a Hedonic Indicator of Well-Being
While the theoretical distinction between PA and NA as hedonic indicators and LS as a subjective indicator can be traced back to the early days of social indicators research (Diener, 1984), it is often overlooked—especially in the psychological literature. For example, an influential article examining the relationship of SWB with Ryff’s measure of Psychological Well-Being treated PA, NA, and LS as indicators of a latent SWB factor and ignored the unique variances of these indicators (Keyes et al., 2002). This model precludes the possibility that some people may rely on PWB dimensions such as meaning or autonomy to evaluate their lives.
Further confusion was introduced when Diener’s SWB concept was equated with hedonistic theories of well-being (Ryan & Deci, 2001). A few years later, Deci and Ryan (2008) acknowledged that LS is “not strictly a hedonic concept” (p. 2), but this caveat has been largely ignored. The preceding review clarifies that LS is not a hedonic indicator of well-being at all. It is a subjective indicator that allows individuals to evaluate their lives based on their own criteria. If these evaluations correlate strongly with PA and NA, it shows that people often assess their lives using criteria that also increase PA and reduce NA. However, these evaluations also correlate strongly with dimensions from eudaimonic theories of well-being (Keyes et al., 2002). Thus, it is unclear which sources of information individuals actually use, and it is incorrect to classify life satisfaction judgments as hedonic indicators or to ignore the unique variance in LS that is not shared with PA or NA.
The appeal of life satisfaction judgments as subjective indicators lies in the fact that they allow individuals to evaluate their lives based on their own standards. This makes life satisfaction fundamentally different from both hedonic and eudaimonic measures, which evaluate lives based on fixed criteria applied equally to all individuals. When life satisfaction is combined with hedonic indicators, this unique subjective perspective is lost, and it becomes impossible to empirically examine how hedonic and eudaimonic aspects of a good life contribute to people’s own evaluations.
The key conclusion is that variance in life satisfaction judgments that is not shared with hedonic indicators should not be dismissed as measurement error. Instead, it may contain valid information about how people personally assess their lives. No other social indicator provides this type of insight. This may explain why life satisfaction is the most widely used subjective social indicator.
Correlations between Hedonic Balance and Life Satisfaction
Although hedonic and subjective indicators of well-being are conceptually distinct, they are typically positively correlated. That is, individuals who experience more positive affect (PA) and less negative affect (NA) tend to report higher levels of life satisfaction (LS) (Busseri & Erb, 2024; Zou, Schimmack, & Gere, 2013). A common explanation for this correlation is that people draw on their past affective experiences when evaluating their lives through life satisfaction judgments (e.g., Andrews & McKennell, 1980; Connolly & Gärling, 2024; Kainulainen, Saari, & Veenhoven, 2018; Kööts-Ausmees, Realo, & Allik, 2013; Kuppens, Realo, & Diener, 2008; Rojas & Veenhoven, 2013; Schimmack & Kim, 2020; Schimmack, Diener, & Oishi, 2002; Schimmack, Radhakrishnan, Dzokoto, & Ahadi, 2002; Suh, Diener, Oishi, & Triandis, 1998; Veenhoven, 2009; Zou, Schimmack, & Oishi, 2013). This explanation is often referred to as the affective component model (Andrews & McKennell, 1980). It assumes that people are at least partial hedonists who use the balance of past PA and NA to evaluate their lives. However, because PA and NA do not fully explain the variance in LS, it suggests that people also rely on other sources of information when forming life satisfaction judgments.
While the affective component model is widely accepted, alternative models have been proposed. Busseri and Erb (2024), building on Keyes et al.’s (2002) framework, argue that PA, NA, and LS are correlated because they are all influenced by an unobserved third variable. This is referred to as a hierarchical model, a common structure in measurement models in which a latent factor accounts for shared variance among observed variables. Following Keyes et al. (2002), the shared variance among PA, NA, and LS is often labeled as subjective well-being (SWB). However, Keyes and colleagues treated LS as a fallible indicator of SWB, assuming that its unique variance is merely measurement error. Busseri and Erb (2024) challenge this view, suggesting that LS includes meaningful variance not captured by PA or NA—but their model requires a theoretical account of the unobserved variable that gives rise to the shared variance among the three SWB components.
Busseri and Erb propose that this latent factor reflects an underlying sense of well-being. Because PA and NA are, by definition, aggregates of momentary affective experiences, this model implies that people’s overall sense of well-being shapes both their affective experiences and their life satisfaction judgments—independently of those experiences themselves. In other words, people’s feelings in the moment do not directly influence how they evaluate their lives retrospectively. Busseri and Erb call this a hierarchical model, but this term does not clearly distinguish their causal model from Keyes et al.’s (2002) measurement model and may lead to confusion. To avoid this ambiguity, I will refer to their model as the Underlying Sense of Well-Being (USWB) model.
The affective component model and the USWB model make competing predictions that can be tested empirically. One prediction of the USWB model is that situational factors—which are known to influence momentary affect—do not influence life satisfaction judgments. Research has consistently shown that affective experiences are highly variable across time due to situational influences (Eid, Notz, Steyer, & Schwenkmezger, 1994; Epstein, 1979). However, these momentary experiences are also shaped by stable individual differences. When affect is aggregated over time, the influence of stable dispositions becomes more apparent (Epstein, 1979).
Thus, the most plausible interpretation of the USWB model is that it reflects personality dispositions—for example, emotional stability or extraversion—that consistently influence both affective experience and retrospective life evaluations. According to the model, these stable traits lead people to evaluate their lives more positively, independent of their actual momentary affective experiences. In contrast, the affective component model predicts that life satisfaction judgments are influenced by past affective experiences and that the effects of stable traits are mediated through those experiences.
Are Life Satisfaction Judgments Related to Aggregated Affective Experience?
The first question is whether life satisfaction judgments are even related to aggregated momentary affective experiences. While there are hundreds of cross-sectional studies showing correlations between memory-based ratings of positive affect (PA) and negative affect (NA) with life satisfaction (LS), surprisingly few studies have examined the relationship between aggregated momentary ratings of PA and NA and LS. Even fewer have attempted to control for response styles—systematic biases in self-reports that can produce spurious correlations (Schimmack, Schupp, & Wagner, 2008). Nonetheless, circumstantial evidence suggests that aggregated momentary affect is meaningfully related to life satisfaction, and that these correlations are not merely methodological artifacts.
First, several studies have shown that retrospective ratings of affect are at least partially grounded in actual past affective experiences (Barrett, 1997; Diener, Smith, & Fujita, 1995; Mill, Realo, & Allik, 2016; Röcke, Hoppmann, & Klumb, 2011; Schimmack, 1997; Thomas & Diener, 1990). Second, both daily and retrospective self-ratings of affect show substantial convergence with informant ratings (Diener et al., 1995; Gere & Schimmack, 2011), suggesting that shared method variance and response styles are not sufficient to explain the observed associations. Furthermore, research has shown that aggregated momentary affect predicts life satisfaction judgments (Schimmack, 2003), supporting the idea that people use their affective experiences as inputs when evaluating their lives.
These results are consistent with the affective component model, but they do not rule out the alternative explanation that the correlation between affect and life satisfaction is driven by underlying dispositional tendencies—that is, that life satisfaction is linked to the tendency to experience more PA and less NA, rather than to the actual affective experiences themselves.
Fortunately, a larger body of research has examined how personality traits relate to life satisfaction (Anglim et al., 2020). When personality is measured at the level of broad dispositions, Neuroticism consistently emerges as the strongest predictor of life satisfaction judgments. Neuroticism can be conceptualized as a general disposition to experience low well-being. The low end of Neuroticism, often referred to as Emotional Stability, may therefore be one of the core dispositional components of the USWB factor. One prediction of this interpretation is that life satisfaction should be more strongly predicted by Neuroticism than by actual affective experiences.
Contrary to this prediction, however, PA and NA are stronger predictors of life satisfaction than Neuroticism (Schimmack, Diener, et al., 2002; Schimmack & Kim, 2020; Schimmack, Schupp et al., 2008). This also holds true for Busseri and Erb’s data, which were used to support the hierarchical model. PA remains a strong predictor of LS even after controlling for Neuroticism. Including Extraversion and other personality traits as additional predictors does not change this finding. While this result does not falsify the USWB model—it is still possible that other unobserved variables are responsible for the PA–LS link—it is consistent with the affective component model, which posits a direct influence of affective experience on life satisfaction.
Here is the next revised section, titled “Domain Satisfaction as a Third Variable”:
Domain Satisfaction as a Third Variable
Another way to test the competing models is to examine how known predictors of life satisfaction judgments relate to PA and NA. One well-established source of information in life satisfaction judgments is individuals’ evaluations of important life domains, such as work and family (Schneider & Schimmack, 2010). Domain satisfaction explains self–informant agreement in life satisfaction judgments, even after controlling for personality effects on both life satisfaction and domain satisfaction judgments (Payne & Schimmack, 2020). These findings suggest that domain satisfaction provides a plausible third variable—or a set of third variables—that can account for the observed correlation between hedonic balance and life satisfaction judgments.
According to this interpretation, life satisfaction judgments may be based primarily on cognitive evaluations of life domains, while PA and NA are higher (or lower) when domain satisfaction is high (or low). In this case, there is no need to invoke a shared unobserved cause. Instead, the logic is straightforward: lives that are evaluated more positively also tend to produce more positive and fewer negative affective experiences on a momentary basis.
One of the few studies to test this hypothesis examined hedonic balance and domain satisfaction as mediators of personality effects on life satisfaction. It found that hedonic balance contributed to the prediction of life satisfaction and was the main mediator of personality effects (Schimmack et al., 2002). Unfortunately, this study has not been replicated, and further research is needed to determine the relative importance of hedonic balance versus domain satisfaction as mediators.
Here is the next revised section, titled “Domain Satisfaction as a Third Variable”:
Domain Satisfaction as a Third Variable
Another way to test the competing models is to examine how known predictors of life satisfaction judgments relate to PA and NA. One well-established source of information in life satisfaction judgments is individuals’ evaluations of important life domains, such as work and family (Schneider & Schimmack, 2010). Domain satisfaction explains self–informant agreement in life satisfaction judgments, even after controlling for personality effects on both life satisfaction and domain satisfaction judgments (Payne & Schimmack, 2020). These findings suggest that domain satisfaction provides a plausible third variable—or a set of third variables—that can account for the observed correlation between hedonic balance and life satisfaction judgments.
According to this interpretation, life satisfaction judgments may be based primarily on cognitive evaluations of life domains, while PA and NA are higher (or lower) when domain satisfaction is high (or low). In this case, there is no need to invoke a shared unobserved cause. Instead, the logic is straightforward: lives that are evaluated more positively also tend to produce more positive and fewer negative affective experiences on a momentary basis.
One of the few studies to test this hypothesis examined hedonic balance and domain satisfaction as mediators of personality effects on life satisfaction. It found that hedonic balance contributed to the prediction of life satisfaction and was the main mediator of personality effects (Schimmack et al., 2002). Unfortunately, this study has not been replicated, and further research is needed to determine the relative importance of hedonic balance versus domain satisfaction as mediators.
A Psychometric Examination of the USWB Model
A major problem with the USWB model is that the loadings of the three components—PA, NA, and LS—on the latent variable are not theoretically specified. Instead, they are estimated freely based on the pattern of correlations among the observed variables. However, these correlations can vary substantially across studies. The most problematic issue is that the loading of LS on the USWB factor depends on the correlation between PA and NA. This is conceptually problematic because the influence of an underlying sense of well-being on life satisfaction judgments should not depend on how PA and NA are correlated.
This issue arises from the assumption that PA and NA are both influenced by a single common cause and that the strength of this effect is reflected in the correlation between PA and NA. The problem becomes particularly severe when PA and NA are measured as independent dimensions of affect, as in Bradburn’s original measure or the widely used PANAS (Watson et al., 1988), which has been used in many SWB studies. In these cases, the correlation between PA and NA is often small, or even positive. Positive or near-zero correlations cannot be modeled with a single latent factor. Even small negative correlations can be modeled but result in near-unity loadings for LS, which is implausible.
This problem is often masked in studies that use PA and NA measures that are moderately to strongly negatively correlated. However, the theoretical issue remains: why should the effect of a latent sense of well-being on life satisfaction depend on the correlation between PA and NA—a correlation that itself is influenced by many other factors, including measurement design and response format?
One simple solution to this problem is to compute a hedonic balance score (e.g., PA minus NA) and propose that an underlying sense of well-being influences both hedonic balance and life satisfaction, but not affective experiences directly. However, this model is not identified—that is, it cannot be estimated from the data alone. An alternative solution is to allow for a correlated residual between PA and NA. For example, PANAS PA and NA scores may be positively correlated because they both capture high arousal or activation. While this model also remains unidentified in isolation, it can be identified when other predictors are added to the model.
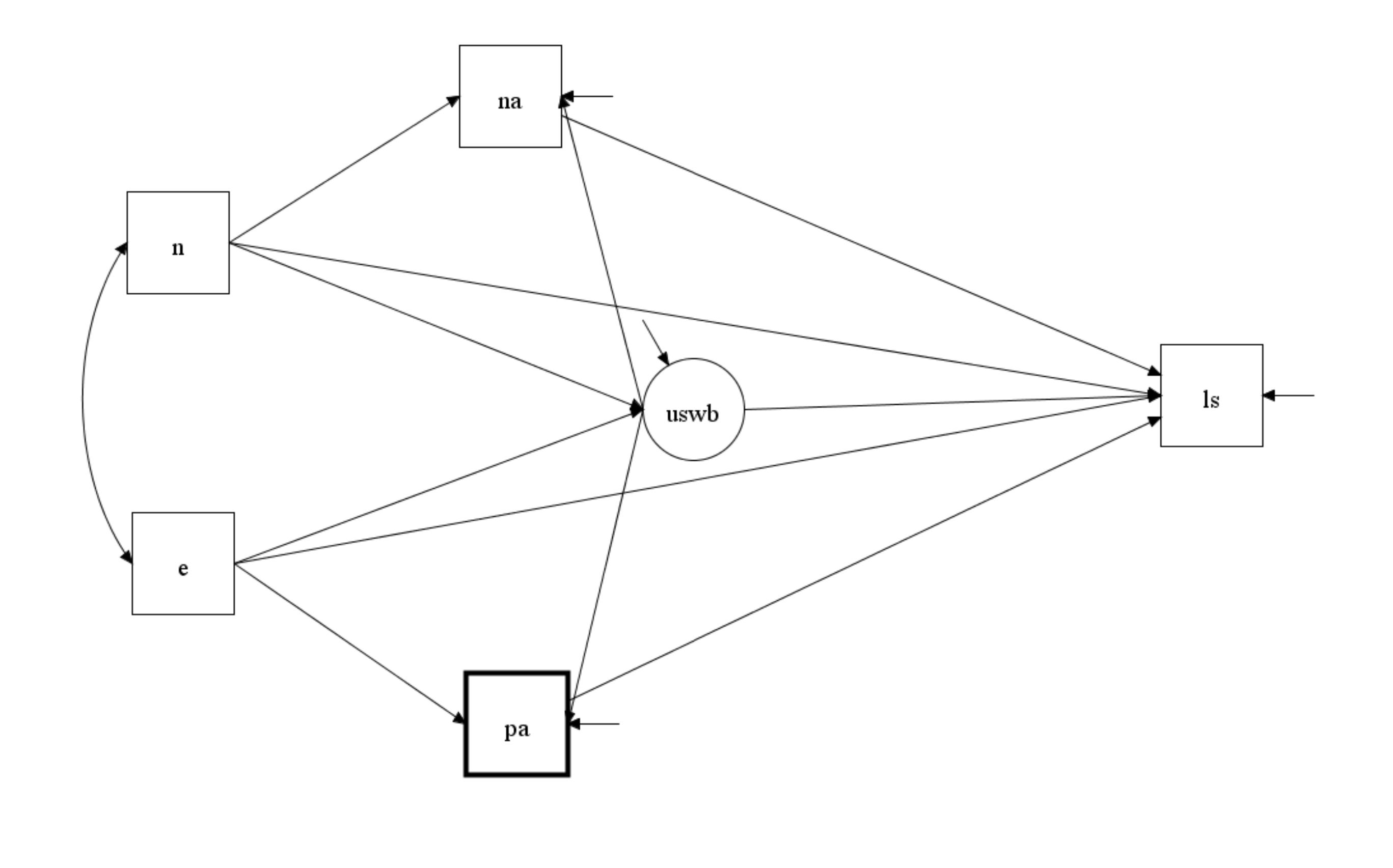
Figure 1 illustrates that differences between the affective component model and the USWB model. The affective component model does not assume that that the shared variance between PA and NA is not the product of an unobserved variable (uswb) that directly influences ls. Thus, the path from uswb to LS is assumed to be zero. In contrast, the USWB model assumes that this is the only causal path that relates PA and NA to LS. Thus, the paths from na to ls and from pa to ls are fixed to zero. The problem with testing these two models against each other is that models that allow for all three parameters to be free are not identified.
In conclusion, the affective component model and the USWB model are more similar than often portrayed—especially in literature reviews that present the USWB model as a measurement model of SWB. In doing so, these reviews often conflate theoretical constructs with empirical models and obscure deeper issues. Simply labeling a latent variable “SWB” does not explain the nature of its components or justify collapsing them into a single factor. As Bollon (2002) notes, unobserved does not mean unobservable. Any model that includes a latent variable must eventually specify what it represents and identify measurable indicators to test its claims. Without this, the latent variable remains a hypothetical placeholder with no direct empirical support (Borsboom, 2003).
Extraversion and Neuroticism as Common Causes
Costa and McCrae (1980) proposed one of the first theoretical models linking personality traits to subjective well-being (SWB). In their model, Extraversion is a disposition to experience more positive affect (PA), but not necessarily less negative affect (NA), while Neuroticism is a disposition to experience more negative affect, but not necessarily less positive affect. In turn, PA and NA were conceptualized as independent predictors of both hedonic and evaluative components of well-being.
Within this framework, the influence of Extraversion on life satisfaction (LS) is mediated by PA, and the influence of Neuroticism on LS is mediated by NA. This model does not require a latent USWB factor, because personality traits are assumed to be related only to the unique variances of PA and NA. However, this approach was developed under the assumption that PA and NA are independent constructs.
With PA and NA scales that are empirically correlated—as is often the case in recent studies—Neuroticism tends to predict PA (negatively), and Extraversion tends to predict NA (negatively). This opens up the possibility that the effects of these two personality traits may be fully mediated by a USWB factor, rather than by the unique variances of PA and NA. Busseri and Erb (2024) suggest this possibility, but they did not directly compare models that allow both pathways.
Using their meta-analytic correlation matrix, based on data from N = 30,000 participants, I conducted a model comparison. The affective component model makes a simple prediction: personality traits influence PA and NA directly, and their effects on LS are fully mediated by affect. In this model, direct effects of Neuroticism and Extraversion on LS are fixed to zero, yielding two degrees of freedom. The model fit was acceptable for CFI (CFI = .991) but not for RMSEA (RMSEA = .094). This suggests that personality traits still explain unique variance in LS beyond their effects on affect.
When direct paths from Neuroticism and Extraversion to LS were added, the model became saturated (zero degrees of freedom) and, naturally, fit the data perfectly. Importantly, the indirect effects were stronger than the direct effects: for Neuroticism, indirect b = –.24 and direct b = –.09; for Extraversion, indirect b = .21 and direct b = .08. These results do not prove that the affective component model is the correct model, but they show that Busseri and Erb’s data are consistent with it.
The USWB model introduces a latent variable and assumes full mediation of personality effects through this factor. The initial version of the model also assumed that the effects of Extraversion and Neuroticism on affect were themselves fully mediated by USWB. This model showed poor fit (CFI = .852; RMSEA = .267). As Busseri and Erb noted, freeing the path from Neuroticism to NA improved model fit (CFI = .985; RMSEA = .094). Adding a path from Extraversion to PA improved fit further (CFI = .989; RMSEA = .103), and allowing Neuroticism to predict PA directly yielded still better fit (CFI = .997; RMSEA = .072). Finally, adding direct effects from Extraversion and Neuroticism to LS yielded a saturated model with perfect fit.
In this model, personality effects on LS were mostly mediated by USWB: for Neuroticism, indirect b = –.25 and direct b = –.08; for Extraversion, indirect b = .11 and direct b = .18.
The key conclusion from this model comparison is that the data are consistent with both the affective component model and the USWB model. The main reason is that the SPANE PA and NA scales used in these analyses are not independent and are not uniquely related to Extraversion and Neuroticism. Thus, these data do not allow us to empirically distinguish the two models. Additional data, preferably using orthogonal measures of affect and independent personality predictors, are needed to provide a definitive test.
At a broader level, this highlights the enduring third-variable problem in correlational research. For example, if PA and LS are correlated, we know that LS cannot cause PA (because affect precedes evaluation), but we cannot determine whether PA influences LS or whether both are caused by an unobserved third variable.
Here is the revised section “Distinguishing Causal Models and Conceptual Models”:
Distinguishing Causal Models and Conceptual Models
A recurring problem in the literature on subjective well-being is the confusion between causal models and conceptual models. The question “What is SWB?” is a conceptual one. The question “What causes SWB?” is a causal one. The first must be answered before the second can be meaningfully addressed. Unfortunately, this distinction is often overlooked—particularly in studies that use structural equation modeling (SEM) without a clearly defined theoretical foundation for the constructs being modeled.
SEM is a powerful tool for testing causal hypotheses, but it relies on the assumption that the latent variables it models represent valid theoretical constructs. For instance, researchers may assume that people do, in fact, have affective experiences that can be measured with some error. If multiple observed indicators are available (e.g., several items measuring PA), SEM can separate valid variance from measurement error by modeling a latent PA factor.
However, problems arise when researchers go beyond measurement error correction and start creating new latent constructs simply because observed variables are correlated. For example, Keyes et al. (2002) created a latent PWB factor because scores on Ryff’s six psychological well-being scales were correlated. But the decision to treat the shared variance as a new construct cannot be justified purely on psychometric grounds. It requires a theoretical justification—an argument that a previously unmeasured construct exists and is responsible for the observed correlations.
This same issue plagues latent SWB models. Simply labeling the shared variance between PA, NA, and LS as “subjective well-being” does not answer the conceptual question of what SWB actually is. Nor does it clarify what the unique variances in PA, NA, and LS represent. As Busseri and Sadava (2010) rightly asked: What is SWB?
One answer is that SWB reflects hedonic well-being, and life satisfaction judgments are merely expressions of this hedonic state. In this view, LS is a valid indicator of SWB only to the extent that it correlates with PA and NA; any unique variance in LS is treated as measurement error. This is the position associated with Ryan and Deci (2001), though they later acknowledged that LS is “not strictly a hedonic concept” (Deci & Ryan, 2008). In fact, even Busseri and Erb (2024) explicitly reject the idea that LS is simply a proxy for hedonic balance.
Thus, the SWB factor model, when treated as a conceptual model, fails to address the very question it is meant to answer. At the conceptual level, SWB is not a unitary construct. It includes at least two distinct components:
- The amount of momentary affective experience (PA and NA), and
- Retrospective evaluations of life based on personal criteria (LS).
As discussed earlier, a latent SWB model may still be useful as a causal model—for example, to test whether hedonic experiences predict life satisfaction—but this does not imply that SWB itself is a coherent, unified construct. Conceptually, it is not. The degree to which people rely on affective experiences when making life evaluations is an empirical question that requires a clear distinction between hedonic indicators (PA, NA) and subjective indicators (LS) based on individuals’ own evaluative frameworks.
Here is the revised Conclusion section:
Conclusion
Life satisfaction judgments are a prominent subjective indicator of well-being. They are based on a distinctive approach to defining well-being—one that gives individuals the authority and responsibility to define happiness for themselves. This perspective emerged from opinion and survey research, where social scientists sought to understand how people evaluate their own lives. In contrast, philosophers have traditionally attempted to define happiness objectively, applying a single standard to all individuals. These efforts have given rise to both eudaimonic and hedonistic theories of well-being.
Diener (1984) classified eudaimonic indicators as objective, and affective experiences as subjective, because they are shaped by the personalities of the individuals experiencing them. He also classified life satisfaction judgments as subjective, because they require individuals to evaluate their lives according to their own criteria. This led to the now-common definition of subjective well-being (SWB) as consisting of high PA, low NA, and high LS. However, this definition has created considerable confusion, particularly because it is unclear how to integrate information from PA, NA, and LS into a single SWB indicator.
I have argued that SWB is not a well-defined theoretical construct. The label simply groups two theories of happiness—hedonistic and subjectivist—under a broad umbrella, but this does not mean they form a unified concept. Hedonic balance is subjective in the sense that affective experiences are internal, but its use as a well-being indicator is grounded in hedonistic philosophy, which asserts that pleasure and pain are the only relevant evaluative criteria. In contrast, life satisfaction judgments are subjective because they give people the freedom to define happiness for themselves. This conception is not rooted in a philosophical definition of happiness but instead reflects a pluralistic, individual-centered approach: happiness is whatever people believe it to be.
This makes life satisfaction a unique and important social indicator. It is not merely a component of SWB, but an independent construct that captures people’s own evaluations of their lives—evaluations that may or may not align with affective states. While this conclusion may reinforce existing practices in social indicators research, it is valuable to clarify the conceptual foundation for using life satisfaction as a measure of happiness. Life satisfaction is a valid indicator of happiness only under the assumption that happiness cannot be objectively defined and that people can generate meaningful, personal theories of well-being. This approach stands in contrast to hedonistic models and should not be collapsed into a composite SWB score alongside PA and NA.
References
Andrews, F. M., & McKennell, M. C. (1980). Measures of self-reported well-being: Their affective, cognitive, and other components. Social Indicators Research, 8(2), 127–155.
Anglim, J., & Grant, S. (2016). Predicting psychological and subjective well-being from personality: Incremental prediction from 30 facets over the Big Five. Journal of Happiness Studies, 17(1), 59–80. https://doi.org/10.1007/s10902-014-9583-7
Anglim, J., Horwood, S., Smillie, L. D., Marrero, R. J., & Wood, J. K. (2020). Predicting psychological and subjective well-being from personality: A meta-analysis. Psychological Bulletin, 146(4), 279–323. https://doi.org/10.1037/bul0000226
Anusic, I., Schimmack, U., Pinkus, R. T., & Lockwood, P. (2009). The nature and structure of correlations among Big Five ratings: The halo-alpha-beta model. Journal of Personality and Social Psychology, 97(6), 1142–1156. https://doi.org/10.1037/a0017159
Barrett, L. F. (1997). The relationships among momentary emotion experiences, personality descriptions, and retrospective ratings of emotion. Personality and Social Psychology Bulletin, 23(10), 1100–1110. https://doi.org/10.1177/01461672972310010
Busseri, M. A., & Sadava, S. W. (2011). A review of the tripartite structure of subjective well-being: Implications for conceptualization, operationalization, and synthesis. Personality and Social Psychology Review, 15(3), 290–314. https://doi.org/10.1177/1088868310391271
Chen, Y. R., Nakagomi, A., Hanazato, M., Abe, N., Ide, K., & Kondo, K. (2025). Perceived urban environment elements associated with momentary and long-term well-being: An experience sampling method approach. Scientific Reports, 15(1), 4422. https://doi.org/10.1038/s41598-025-88349-x
Connolly, F. F., & Gärling, T. (2024). What distinguishes life satisfaction from emotional wellbeing? Frontiers in Psychology, 15, 1434373. https://doi.org/10.3389/fpsyg.2024.1434373
Costa, P. T., Jr., & McCrae, R. R. (1980). Influence of extraversion and neuroticism on subjective well-being: Happy and unhappy people. Journal of Personality and Social Psychology, 38(4), 668–678. https://doi.org/10.1037/0022-3514.38.4.668
Diener, E. (1984). Subjective well-being. Psychological Bulletin, 95(3), 542–575. https://doi.org/10.1037/0033-2909.95.3.542
Diener, E., Smith, H., & Fujita, F. (1995). The personality structure of affect. Journal of Personality and Social Psychology, 69(1), 130–141. https://doi.org/10.1037/0022-3514.69.1.130
Diener, E., Wirtz, D., Tov, W., Kim-Prieto, C., Choi, D. W., Oishi, S., & Biswas-Diener, R. (2010). New well-being measures: Short scales to assess flourishing and positive and negative feelings. Social Indicators Research, 97(2), 143–156. https://doi.org/10.1007/s11205-009-9493-x
Eid, M., Notz, P., Steyer, R., & Schwenkmezger, P. (1994). Validating scales for the assessment of mood level and variability by latent state–trait analyses. Personality and Individual Differences, 16(1), 63–76. https://doi.org/10.1016/0191-8869(94)90134-4
Gere, J., & Schimmack, U. (2011). A multi-occasion multi-rater model of affective dispositions and affective well-being. Journal of Happiness Studies, 12(6), 931–945. https://doi.org/10.1007/s10902-010-9237-3
Kainulainen, S., Saari, J., & Veenhoven, R. (2018). Life satisfaction is more a matter of feeling-well than having-what-you-want: Tests of Veenhoven’s theory. International Journal of Happiness and Development, 4(3), 209–235. https://doi.org/10.1504/IJHD.2018.095260
Keyes, C. L. M., Shmotkin, D., & Ryff, C. D. (2002). Optimizing well-being: The empirical encounter of two traditions. Journal of Personality and Social Psychology, 82(6), 1007–1022. https://doi.org/10.1037/0022-3514.82.6.1007
Kööts-Ausmees, L., Realo, A., & Allik, J. (2013). The relationship between life satisfaction and emotional experience in 21 European countries. Journal of Cross-Cultural Psychology, 44(2), 223–244. https://doi.org/10.1177/0022022112451054
Kuppens, P., Realo, A., & Diener, E. (2008). The role of positive and negative emotions in life satisfaction judgments across nations. Journal of Personality and Social Psychology, 95(1), 66–75. https://doi.org/10.1037/0022-3514.95.1.66
Michalos, A. C. (2014). Subjective indicators. In A. C. Michalos (Ed.), Encyclopedia of quality of life and well-being research (pp. 6427–6430). Springer. https://doi.org/10.1007/978-94-007-0753-5_2899
Mill, A., Realo, A., & Allik, J. (2015). Retrospective ratings of emotions: The effects of age, daily tiredness, and personality. Frontiers in Psychology, 6, 2020. https://doi.org/10.3389/fpsyg.2015.02020
Payne, B. K., & Schimmack, U. (2020). The impact of domain satisfaction and personality on global life satisfaction: Testing top-down and bottom-up effects. Journal of Research in Personality, 87, 103979. https://doi.org/10.1016/j.jrp.2020.103979
Rojas, M., & Veenhoven, R. (2013). Contentment and affect in the estimation of happiness. Social Indicators Research, 110(2), 415–431. https://doi.org/10.1007/s11205-011-9863-7
Röcke, C., Hoppmann, C. A., & Klumb, P. L. (2011). Correspondence between retrospective and momentary ratings of positive and negative affect in old age: Findings from a one-year measurement burst design. The Journals of Gerontology Series B: Psychological Sciences and Social Sciences, 66(4), 411–415. https://doi.org/10.1093/geronb/gbr024
Ryan, R. M., & Deci, E. L. (2001). On happiness and human potentials: A review of research on hedonic and eudaimonic well-being. Annual Review of Psychology, 52, 141–166. https://doi.org/10.1146/annurev.psych.52.1.141
Schimmack, U., Diener, E., & Oishi, S. (2002). Life-satisfaction is a momentary judgment and a stable personality characteristic: The use of chronically accessible and stable sources. Journal of Personality, 70(3), 345–384. https://doi.org/10.1111/1467-6494.05008
Schimmack, U., & Kim, A. Y. (2020). Stability and change of affective well-being: Longitudinal evidence from the MIDUS study. Journal of Personality and Social Psychology, 118(1), 190–209. https://doi.org/10.1037/pspp0000228
Schimmack, U., Radhakrishnan, P., Dzokoto, V., & Ahadi, S. (2002). Culture, personality, and subjective well-being: Integrating process models of life satisfaction. Journal of Personality and Social Psychology, 82(4), 582–593. https://doi.org/10.1037/0022-3514.82.4.582
Schimmack, U., Schupp, J., & Wagner, G. G. (2008). The influence of environment and personality on the affective and cognitive components of subjective well-being. Social Indicators Research, 89(1), 41–60. https://doi.org/10.1007/s11205-007-9232-0
Schneider, S., & Schimmack, U. (2010). Self-informant agreement in well-being ratings: A meta-analysis. Social Indicators Research, 94(3), 363–376. https://doi.org/10.1007/s11205-009-9440-y
Veenhoven, R. (2009). How do we assess how happy we are? Tenets, implications and tenability of three theories. In A. K. Dutt & B. Radcliff (Eds.), Happiness, economics and politics: Towards a multidisciplinary approach (pp. 45–69). Edward Elgar Publishing.
