P-curve was introduced a little over a decade ago by Uri Simonsohn, Leif D. Nelson, and Joseph P. Simmons (2014); the same team that later launched the DataColada blog. It is a selection-model approach designed specifically for examining the evidential value of published findings when non-significant results are missing and publication bias inflates estimates of power that ignore selection bias.
The method’s goal and its historical context
Its statistical goal is instead to test the null hypothesis that all significant results are false positives. While methodologists warned about this possibility (Rosenthal, 1979), it was considered unlikely that large sets of studies could be published without real effects. However, the DataColada team showed that it can be relatively easy to produce significant results without real effects when the data are p-hacked (Simmons, Nelson, & Simonsohn (2011, Psychological Science, “False-Positive Psychology”). Awareness of inflated type-I error rates and replication failures raised concerns that most results might be false positives (Ioannidis, 2005).
Applications and Limitations
Over the past decade, p-curve has been applied in numerous meta-analyses, and the typical conclusion is that the analyzed literature shows evidential value. However, this conclusion has a critical limitation: rejecting the null hypothesis that all results are false positives does not reveal how many results are false positives, how large the true effects are, or how much reported effect sizes are inflated by publication bias. The latest version of p-curve provides an estimate of “power” to provide quantitative information about the amount of evidential value in a set of studies. This blog post examined the controversy surrounding this parameter of the p-curve model.
Scope of the Discussion
To be clear, the developers also introduced a version of p-curve for effect-size estimation, but this procedure has been used rarely and performs worse than alternative bias-correcting methods when credible nonsignificant evidence is available (see Carter et al., 2019). Consequently, the present discussion focuses on p-curve as a test of evidential value, as implemented in the public p-curve app, rather than as an estimator of effect magnitude.
The Current Debate
Morey and Davis-Stober (2025) published a formal critique in the Journal of the American Statistical Association (JASA) (see my earlier post, Rindex.08.08.25). Uri Simonsohn (2025) responded in a post on the DataColada blog (#129).
The key issue is how p-curve performs when the power of studies varies across studies (i.e., heterogeneity in power). Morey and Davis-Stober present a simulation with true mean power of 66 percent, yet p-curve returns an estimate of 87%, a 21-percentage point difference. Simonsohn shows simulations where bias is never larger than 5%.
Simulation Hacking
The controversy illustrates a broader methodological issue that might be called simulation hacking. Just as empirical researchers can obtain desired results through selective analyses (p-hacking), methodologists can shape conclusions by emphasizing simulation conditions where a method performs particularly well or poorly. This does not mean that the chosen scenarios are unrealistic; rather, it highlights that statistical procedures often perform differently across contexts. A method may be robust and informative for some purposes yet unreliable for others, depending on which assumptions the simulations accentuate.
Simulating Field Wide Heterogeneity

Morey and Davis-Stober (2025) simulated a distribution of true effect sizes that is shown in their Figure 1. This distribution is broadly consistent with the average effect sizes reported in psychology meta-analyses (Richard et al., 2003). Such a distribution can be used to simulate p-values from studies testing a wide variety of hypotheses and research designs that aim to estimate the typical power of studies in psychology (e.g., Cohen, 1962; Schimmack, 2020; Soto & Schimmack, 2024). These conditions generate extreme heterogeneity in statistical power across studies. Morey and Davis-Stober’s analysis suggests that under such heterogeneity, p-curve will produce inflated estimates of average power.
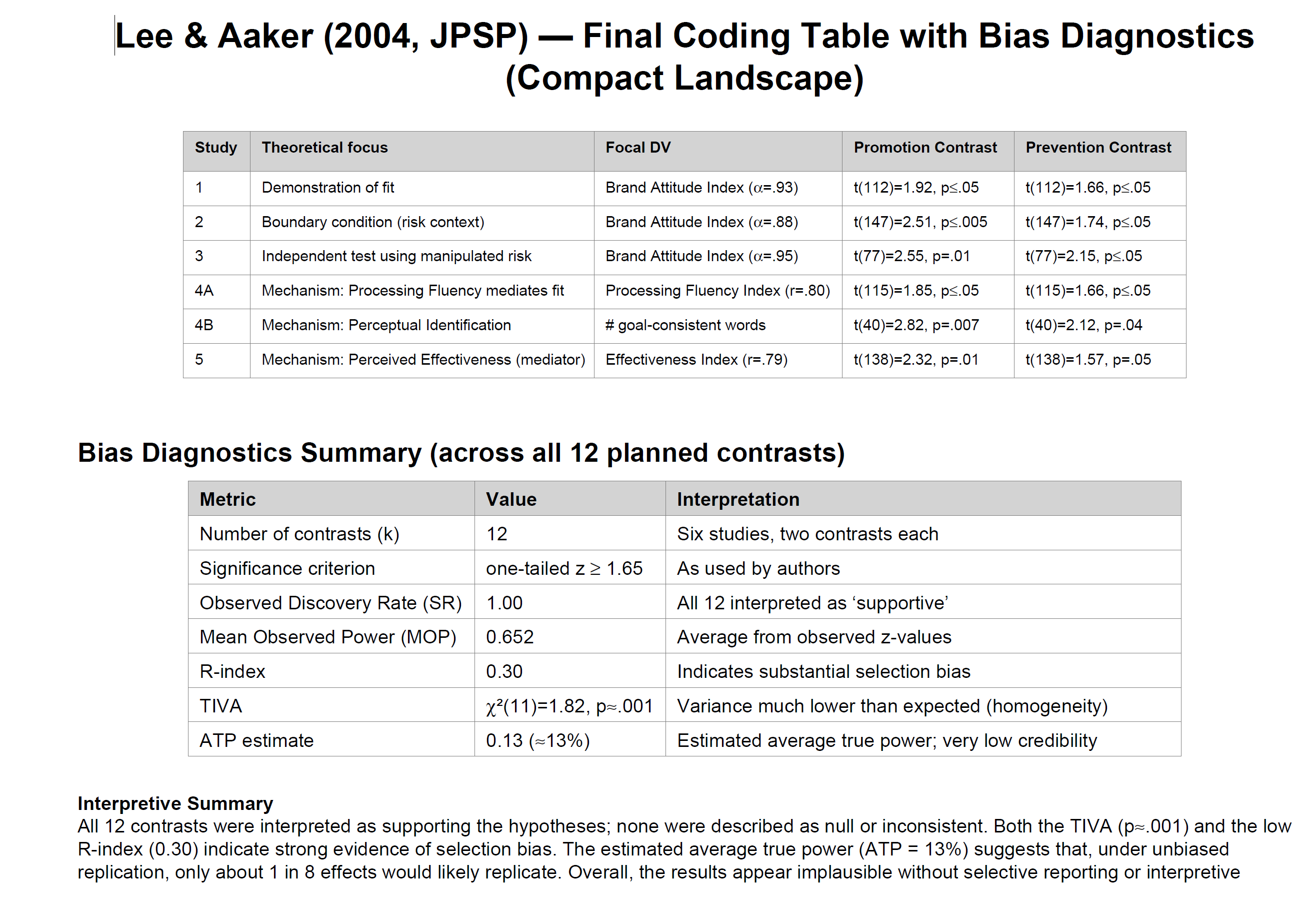
A concrete example is provided by the Reproducibility Project (Open Science Collaboration, 2015). These data are especially informative because the outcomes of the replication studies offer an independent benchmark of the original studies’ power to produce significant results without selection bias. The observed replication rate implies an average true power of less than 40%. Schimmack (2025) analyzed the p-values of the original studies and obtained a p-curve estimate of power of 91%, 95% CI = 86% to 94% (Schimmack, 2025).
If the replication outcomes were unknown, this p-curve result would incorrectly suggest that the high proportion of significant findings in psychology journals (Sterling et al., 1995) reflects genuinely high study power rather than publication bias or p-hacking. In conclusion, a tool that was developed in response to the replication crisis to reveal p-hacking would falsely suggest that power is high and p-hacking is rare.
Simulating Meta-Analyss of P-Hacked Literatures
Simonsohn (2025) simulated studies with low power that never exceeds 80%. Examples like this can be found in meta-analysis of p-hacked studies. For example, a recent p-curve analysis of 825 terror-management studies yielded a power estimate of only 25%, 95%CI = 21% to 29%. This finding implies that exact replications of these studies would produce at most 30% significant results; a rate that is similar to the success rate in actual replication studies (Open Science Collaboration, 2015). An anecdote tells about a social psychologist who prided himself on a success rate of 1 out of 3 studies and compared it baseball, where a 30% batting average is excellent.
The problem here is not that p-curve estimates are biased. Rather, the problem is that they can be easily misinterpreted, if heterogeneity in power is ignored. After all, p-curve does reject the null-hypothesis that all studies are false positives. Assuming that all studies have the same power also implies that there are no false positive results; contrary to Simmons et al.’s (2011) suspicion that false positives are common. P-curve simply does not provide information about false positives unless all significant results are false. The power estimate could be an average of false positives and true positives with high power.
Stay Calm: Use Z-Curve
There is no need to fight over p-curve because we have a better method that works with and without heterogeneity called z-curve (Bartos & Schimmack, 2022; Brunner & Schimmack, 2020). When we developed z-curve, we compared it against alternative models. We presented all simulations, even those where p-curve performed a bit better with homogenous data. The simulation showed that both methods have only a small bias when heterogeneity is small, but p-curve has a large bias when heterogeneity is large. So, we can simply use z-curve for all data.
Here is a simple example that shows how z-curve is superior to p-curve, even if p-curve estimates are only slightly biased. The simulation uses 50% false positives, and 50% true positives with 80% power. It is easy to see that we would expect .50 * .05 + .50 * .80 = .025 + .40 = 42.5% significant results. This is the expected replication rate if the studies were replicated exactly without selection bias. It is called power in p-curve, but that term ignores that real data may contain false positives.

Consistent with Simonsohn’s claims, the bias in the p-curve estimate is small (p-curve estimate: 44% vs. true parameter: 42.5%), but p-curve does not tell us whether all studies have about 40% power or whether this is an average of studies that vary in power or even include false positive results.

Z-curve’s estimate of the expected replication rate (ERR) is accurate (42%). More important, it also recognizes that the data are heterogeneous. A simple way to see this is that it estimates a lower discovery rate for all studies, including non-significant results that are not reported. A discrepancy between EDR and ERR indicates heterogeneity because studies with higher power have a higher chance of being in the set of significant results.
Z-curve also estimates the expected discovery rate for the full range of z-values, including non-significant results that are not reported (see the red dotted line). The EDR of 11% is incompatible with the observed discovery rate of 100% (only significant results are published). Even the upper limit of the CI is only 18% (about 5 studies for each significant result). The p-curve power estimate cannot be used to evaluate publication bias, although p-curve is often falsely used as a test of publication bias.
Finally, the EDR can be used to estimate the false positive risk with a formula by Soric (1989). We know the true percentage is 50%. The z-curve estimate is only 45%, but the 95%CI around this estimate is wide. Most troubling, the 1,000 studies do not rule out the possibility that all studies are false positives (the 95%CI includes 100%). This is very different from the inference we may draw from the p-curve estimate of 42% power that does not suggest a high rate of false positive results.
Z-curve also provides additional information about the expected discovery rate (EDR) for different ranges of observed z-values (see percentages below the x-axis of the z-curve plot). Results that are just significant (e.g., z = 2 to 2.5) are likely to include many false positives; in this range and the expected discovery rate is only about 27%.
By contrast, studies with larger z-values (e.g., z > 4) are almost certainly based on true effects and have an expected replication probability of around 80%. Z-curve slightly overestimate replicability for these high z-values, but the main point is that discovery rates are expected to change dramatically due to heterogeneity in the probability to obtain significant results.
Conclusion
This blog post showed how silly it is to fight over p-curve with carefully selected simulation scenarios. P-curve makes the unrealistic assumption that studies are homogenous. Z-curve avoids this assumption, models heterogeneity, and provides more information about the data than p-curve can. So, researchers can just use z-curve, and the performance of p-curve is no longer relevant. It is a bit like testing assumptions about equal variances in t-tests. We can just use a t-test that avoids this assumption.
It is clear why Simonsohn does not mention a method that replaced p-curve several years ago on the Datacolada blogpost or allows comments that would alert readers to alternative methods. It is not clear why Morey and Davis-Stober criticize a method that is obsolete and do not mention that their criticisms have been addressed by a better method. But then, who understands the childish games of academics that produce publications, but not knowledge.
Unlike Datacolada my blog allows for comments and I welcome comments by Datacolada, Morey, Davis-Stober, or anybody else.