
This blog post reports the results of an analysis that predicts variation in scores on the Satisfaction with Life Scale (Diener et al., 1985) from variation in satisfaction with life domains. A bottom-up model predicts that evaluations of important life domains account for a substantial amount of the variance in global life-satisfaction judgments (Andrews & Withey, 1976). However, empirical tests of this prediction fail to show this (Andrews & Withey, 1976).
Here I used the data from the Panel Study of Income Dynamics (PSID) well-being supplement in 2016. The analysis is based on 8,339 respondents. The sample is the largest national representative sample with the SWLS, although only respondents 30 or order are included in the survey.
The survey also included Cantril’s ladder, which was included in the model, to identify method variance that is unique to the SWLS and not shared with other global well-being measures. Andrews & Withey found that about 10% of the variance is unique to a specific well-being scale.
The PSID-WB module included 10 questions about specific life domains: house, city, job, finances, hobby, romantic, family, friends, health, and faith. Out of these 10 domains, faith was not included because it is not clear how atheists answer a question about faith.
The problem with multiple regression is that shared variance among predictor variables contributes to the explained variance in the criterion variable, but the regression weights do not show this influence and the nature of the shared variance remains unclear. A solution to this problem is to model the shared variance among predictor variables with structural equation modeling. I call this method Variance Decomposition Analysis (VDA).
MODEL 1
Model 1 used a general satisfaction (GS) factor to model most of the shared variance among the nine domain satisfaction judgments. However, a single factor model did not fit the data, indicating that the structure is more complex. There are several ways to modify the model to achieve acceptable fit. Model 1 is just one of several plausible models. The fit of model 1 was acceptable, CFI = .994, RMSEA = .030.

Model 1 used two types of relationships among domains. For some domain relationships, the model assumes a causal influence of one domain on another domain. For other relationship, it is assumed that judgments about the two domains rely on overlapping information. Rather than simply allowing for correlated residuals, this overlapping variance was modelled as unique factors with constrained loadings for model identification purposes.
Causal Relationships
Financial satisfaction (D4) was assumed to have positive effects on housing (D1) and job (D3). The rational is that income can buy a better house and pay satisfaction is a component of job satisfaction. Financial satisfaction was also assumed to have negative effects on satisfaction with family (D7) and friends (D8). The reason is that higher income often comes at a cost of less time for family and friends (work-life balance/trade-off).
Health (D9) was assumed to have positive effects on hobbies (D5), family (D7), and friends (D8). The rational was that good health is important to enjoy life.
Romantic (D6) was assumed to have a causal influence on friends (D8) because a romantic partner can fulfill many of the needs that a friend can fulfill, but not vice versa.
Finally, the model includes a path from job (D3) to city (D2) because dissatisfaction with a job may be attributed to few opportunities to change jobs.
Domain Overlap
Housing (D1) and city (D2) were assumed to have overlapping domain content. For example, high house prices can lead to less desirable housing and lower the attractiveness of a city.
Romantic (D6) was assumed to share content with family (D7) for respondents who are in romantic relationships.
Friendship (D8) and family (D7) were also assumed to have overlapping content because couples tend to socialize together.
Finally, hobby (D5) and friendship (D8) were assumed to share content because some hobbies are social activities.
Figure 2 shows the same figure with parameter estimates.

The most important finding is that the loadings on the general satisfaction (GS) factor are all substantial (> .5), indicating that most of the shared variance stems from variance that is shared across all domain satisfaction judgments.
Most of the causal effects in the model are weak, indicating that they make a negligible contribution to the shared variance among domain satisfaction judgments. The strongest shared variances are observed for romantic (D6) and family (D7) (.60 x .47 = .28) and housing (D1) and city (D2) (.44 x .43 = .19).
Model 1 separates the variances of the nine domains into 9 unique variances (the empty circles next to each square) and five variances that represent shared variances among the domains (GS, D12, D67, D78, D58). This makes it possible to examine how much the unique variances and the shared variances contribute to variance in SWLS scores. To examine this question, I created a global well-being measurement model with a single latent factor (LS) and the SWLS items and the Ladder measures as indicators. The LS factor was regressed on the nine domains. The model also included a method factor for the five SWLS items (swlsmeth). The model may look a bit confusing, but the top part is equivalent to the model already discussed. The new part is that all nine domains have a causal error pointing at the LS factor. The unusual part is that all residual variances are named, and that the model includes a latent variable SWLS, which represents the sum score of the five SWLS items. This makes it possible to use the model indirect function to estimate the path from each residual variance to the SWLS sum score. As all of the residual variance are independent, squaring the total path coefficients yields the amount of variance that is explained by a residual and the variances add up to 1.
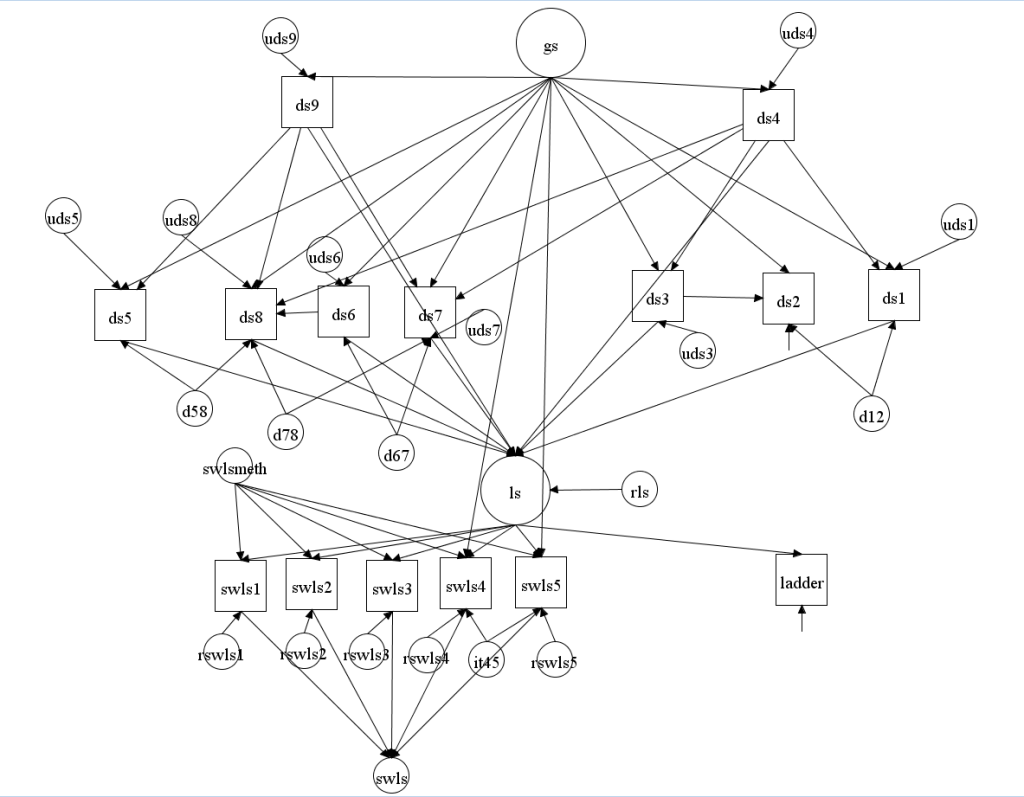
GS has many paths leading to SWLS. Squaring the standardized total path coefficient (b = .67) yields 45% of explained variance. The four shared variances between pairs of domains (d12, d67, d78, d58) yield another 2% of explained variance for a total of 47% explained variance from variance that is shared among domains. The residual variances of the nine domains add up to 9% of explained variance. The residual variance in LS that is not explained by the nine domains accounts for 23% of the total variance in SWLS scores. The SWLS method factor contributes 11% of variance. And the residuals of the 5 SWLS items that represent random measurement error add up to 11% of variance.
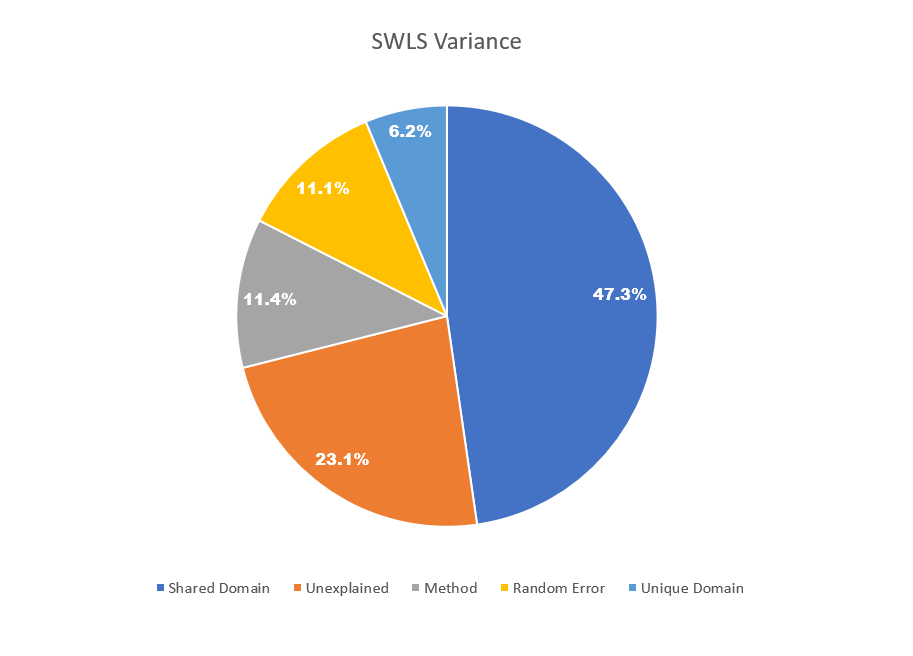
These results show that only a small portion of the variance in SWLS scores can be attributed to evaluations of specific life domains. Most of the variance stems from the shared variance among domains and the unexplained variance. Thus, a crucial question is the nature of these variance sources. There are two options. First, unexplained variance could be due to evaluations of specific domains and shared variance among domains may still reflect evaluations of domains. In this case, SWLS scores would have high validity as a global measure of subjective evaluations of domains. The other possibility is that shared variance among domains and unexplained variance reflects systematic measurement error. In this case, SWLS scores would have only 6% valid variance if they are supposed to reflect global evaluations of life domains. The problem is that decades of subjective well-being research have failed to provide an empirical answer to this question.
Model 2: A bottom-up model of shared variance among domains
Model 1 assumed that shared variance among domains is mostly produced by a general factor. However, a general factor alone was not able to explain the pattern of correlations and additional relationships were added to the model Model 2 assume that shared variance among domains is exclusively due to causal relationships among domains. Model fit was good, CFI = .994, RMSEA = .043.
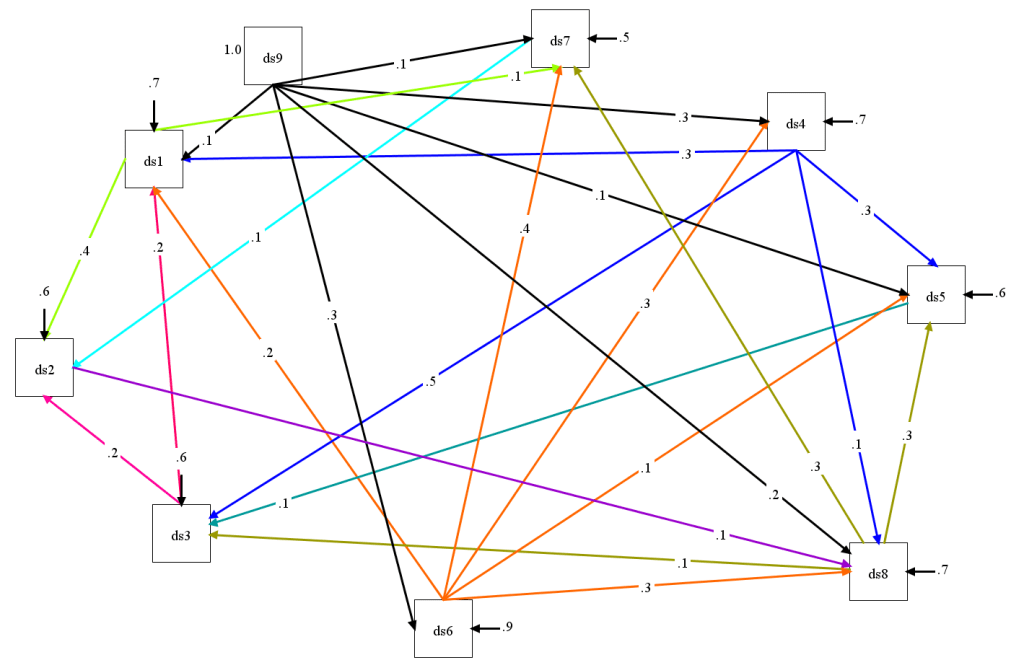
Although the causal network is not completely arbitrary, it is possible to find alternative models. More important, the data do not distinguish between Model 1 and Model 2. Thus, the choice of a causal network or a general factor is arbitrary. The implication is that it is not clear whether 47% of the variance in SWLS scores reflect evaluations of domains or some alternative, top-down, influence.
This does not mean that it is impossible to examine this question. To test these models against each other, it would be necessary to include objective predictors of domain (e.g., income, objective health, frequency of sex, etc.) in the model. The models make different predictions about the relationship of these objective indicators to the various domain satisfactions. In addition, it is possible to include measures of systematic method variance (e.g., halo bias) or predictors of top-down effects (e.g., neuroticism) in the model. Thus, the contribution of domain-specific evaluations to SWLS scores is an empirical question.
Conclusion
It is widely assumed that the SWLS is a valid measure of subjective well-being and that SWLS scores reflect a summary of evaluations of specific life domains. However, regression analyses show that only a small portion of the variance in global well-being judgments is explained by unique variance in domain satisfaction judgments (Andrews & Withey, 1976). In fact, most of the variance stems from the shared variance among domain satisfaction judgments (Model 1). Here I show that it is not clear what this shared variance represents. It could be mostly due to a general factor that reflects internal dispositions (e.g., neuroticism) or method variance (halo bias), but it could also result from relationships among domains in a complex network of interdependence. At present it is unclear how much top-down and bottom-up processes contribute to shared variance among domains. I believe that this is an important research question because it is essential for the validity of global life-satisfaction measures like the SWLS. If respondents are not reflecting about important life domains when they rate their overall well-being, these items are not measuring what they are supposed to measure; that is, they lack construct validity.