Since 2011, it is an open secret that many published results in psychology journals do not replicate. The replicability of published results is particularly low in social psychology (Open Science Collaboration, 2015).
A key reason for low replicability is that researchers are rewarded for publishing as many articles as possible without concerns about the replicability of the published findings. This incentive structure is maintained by journal editors, review panels of granting agencies, and hiring and promotion committees at universities.
To change the incentive structure, I developed the Replicability Index, a blog that critically examined the replicability, credibility, and integrity of psychological science. In 2016, I created the first replicability rankings of psychology departments (Schimmack, 2016). Based on scientific criticisms of these methods, I have improved the selection process of articles to be used in departmental reviews.
1. I am using Web of Science to obtain lists of published articles from individual authors (Schimmack, 2022). This method minimizes the chance that articles that do not belong to an author are included in a replicability analysis. It also allows me to classify researchers into areas based on the frequency of publications in specialized journals. Currently, I cannot evaluate neuroscience research. So, the rankings are limited to cognitive, social, developmental, clinical, and applied psychologists.
2. I am using department’s websites to identify researchers that belong to the psychology department. This eliminates articles that are from other departments.
3. I am only using tenured, active professors. This eliminates emeritus professors from the evaluation of departments. I am not including assistant professors because the published results might negatively impact their chances to get tenure. Another reason is that they often do not have enough publications at their current university to produce meaningful results.
Like all empirical research, the present results rely on a number of assumptions and have some limitations. The main limitations are that
(a) only results that were found in an automatic search are included
(b) only results published in 120 journals are included (see list of journals)
(c) published significant results (p < .05) may not be a representative sample of all significant results
(d) point estimates are imprecise and can vary based on sampling error alone.
These limitations do not invalidate the results. Large difference in replicability estimates are likely to predict real differences in success rates of actual replication studies (Schimmack, 2022).
University of Texas – Austin
I used the department website to find core members of the psychology department. I counted 35 professors and 6 associate professors. Not all researchers conduct quantitative research and report test statistics in their result sections. I limited the analysis to 20 professors and 3 associate professors who had at least 100 significant test statistics. As noted above, this eliminated many faculty members who publish predominantly in neuroscience journals.
Figure 1 shows the z-curve for all 10,679 tests statistics in articles published by 23 faculty members. I use the Figure to explain how a z-curve analysis provides information about replicability and other useful meta-statistics.
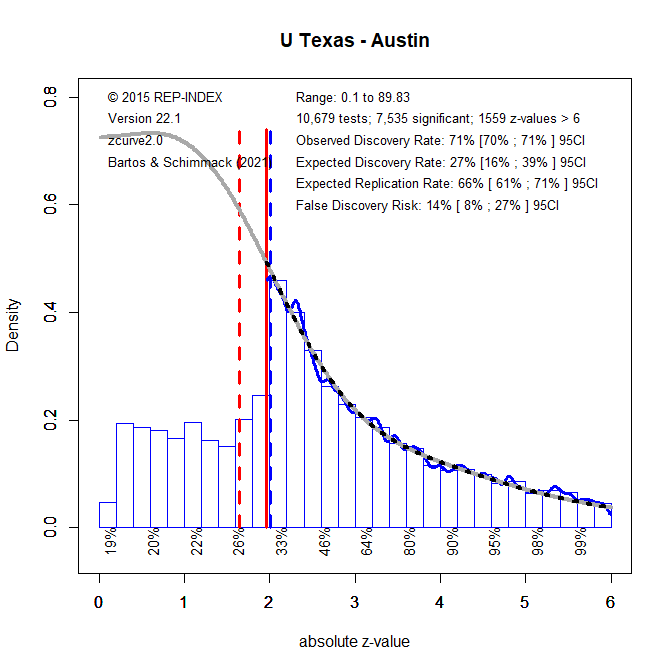
1. All test-statistics are converted into absolute z-scores as a common metric of the strength of evidence (effect size over sampling error) against the null-hypothesis (typically H0 = no effect). A z-curve plot is a histogram of absolute z-scores in the range from 0 to 6. The 1,559 z-scores greater than 6 are not shown because z-scores of this magnitude are extremely unlikely to occur when the null-hypothesis is true (particle physics uses z > 5 for significance). Although they are not shown, they are included in the meta-statistics.
2. Visual inspection of the histogram shows a steep drop in frequencies at z = 1.96 (solid red line) that corresponds to the standard criterion for statistical significance, p = .05 (two-tailed). This shows that published results are selected for significance. The dashed red line shows significance for p < .10, which is often used for marginal significance. Thus, there are more results that are presented as significant than the .05 criterion suggests.
3. To quantify the amount of selection bias, z-curve fits a statistical model to the distribution of statistically significant results (z > 1.96). The grey curve shows the predicted values for the observed significant results and the unobserved non-significant results. The statistically significant results (including z > 6) make up 27% of the total area under the grey curve. This is called the expected discovery rate because the results provide an estimate of the percentage of significant results that researchers actually obtain in their statistical analyses. In comparison, the percentage of significant results (including z > 6) includes 69% of the published results. This percentage is called the observed discovery rate, which is the rate of significant results in published journal articles. The difference between a 71% ODR and a 27% EDR provides an estimate of the extent of selection for significance. The difference of~ 45 percentage points is fairly large. The upper level of the 95% confidence interval for the EDR is 39%. Thus, the discrepancy is not just random. To put this result in context, it is possible to compare it to the average for 120 psychology journals in 2010 (Schimmack, 2022). The ODR (71% vs. 72%) and the EDR (27% vs. 28%) are very similar to the average for 120 psychology journals.
4. The z-curve model also estimates the average power of the subset of studies with significant results (p < .05, two-tailed). This estimate is called the expected replication rate (ERR) because it predicts the percentage of significant results that are expected if the same analyses were repeated in exact replication studies with the same sample sizes. The ERR of 66% suggests a fairly high replication rate. The problem is that actual replication rates are lower than the ERR predictions (about 40% Open Science Collaboration, 2015). The main reason is that it is impossible to conduct exact replication studies and that selection for significance will lead to a regression to the mean when replication studies are not exact. Thus, the ERR represents the best case scenario that is unrealistic. In contrast, the EDR represents the worst case scenario in which selection for significance does not select more powerful studies and the success rate of replication studies is not different from the success rate of original studies. The EDR of 27% is lower than the actual replication success rate of 40%. To predict the success rate of actual replication studies, I am using the average of the EDR and ERR, which is called the actual replication prediction (ARP). For UT Austin, the ARP is (66 + 27)/2 = 47%. This is just a bit above the currently best estimate of the success rate for actual replication studies based on the Open Science Collaboration project (~40%). Thus, UT Austin results are expected to replicate at the average rate of psychological research.
5. The EDR can be used to estimate the risk that published results are false positives (i.e., a statistically significant result when H0 is true), using Soric’s (1989) formula for the maximum false discovery rate. An EDR of 22% implies that no more than 18% of the significant results are false positives, but the lower limit of the 95%CI of the EDR, 18%, allows for 31% false positive results. Most readers are likely to agree that this is too high. One solution to this problem is to lower the conventional criterion for statistical significance (Benjamin et al., 2017). Figure 2 shows that alpha = .005 reduces the point estimate of the FDR to 2% with an upper limit of the 95% confidence interval of 5%. Thus, without any further information readers could use this criterion to interpret results published in articles by psychology researchers at UT Austin. Of course, this criterion will be inappropriate for some researchers, but the present results show that the traditional alpha criterion of .05 is also inappropriate to maintain a reasonably low probability of false positive results.
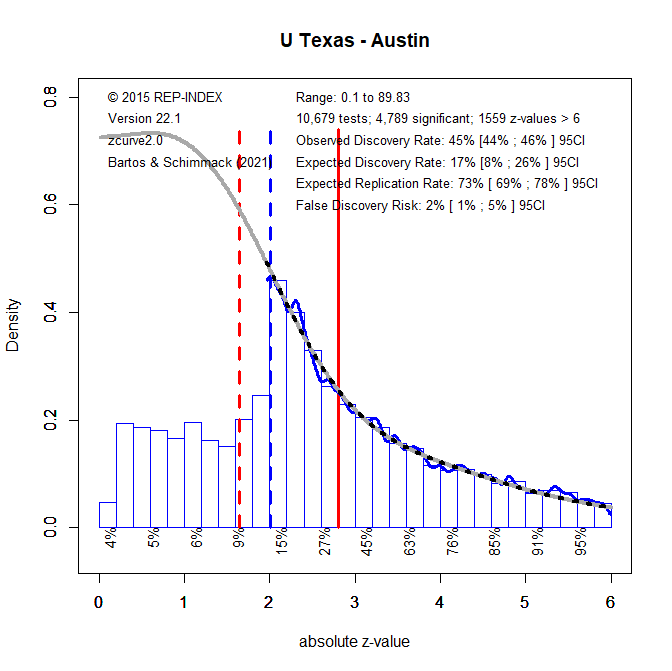
Some researchers have changed research practices in response to the replication crisis. It is therefore interesting to examine whether replicability of newer research has improved. To examine this question, I performed a z-curve analysis for articles published in the past five year (2016-2021).
The results show an improvement. The EDR increased from 27% to 41%, but the confidence intervals are too wide to infer that this is a systematic change. The false discovery risk dropped to 8%, but due to the smaller sample size the upper limit of the 95% confidence interval is still 19%. Thus, it would be premature to lower the significance level at this point. notable improvement. The muted response to the replication crisis is by no means an exception. Rather, currently the exception is Stanford University that has shown the only significant increase in the EDR.

Only one area had enough researchers to conduct an area-specific analysis. The social area had 8 members with useable data. The z-curve is similar to the overall z-curve. Thus, there is no evidence that social psychology at UT Austin has lower replicability than other areas.

There is considerable variability across individual researchers, although confidence intervals are often wide due to the smaller number of test statistics. The table below shows the meta-statistics of all faculty members that provided results for the departmental z-curve. You can see the z-curve for individual faculty member by clicking on their name.
| Rank | Name | ARP | ERR | EDR | FDR |
| 1 | Chen Yu | 74 | 77 | 71 | 2 |
| 2 | Yvon Delville | 71 | 76 | 66 | 3 |
| 3 | K. Paige Harden | 62 | 69 | 54 | 4 |
| 4 | Cristine H. Legare | 58 | 73 | 42 | 7 |
| 5 | James W. Pennebaker | 55 | 63 | 47 | 6 |
| 6 | William B. Swann | 53 | 75 | 32 | 11 |
| 7 | Bertram Gawronski | 52 | 74 | 29 | 13 |
| 8 | Jessica A. Church | 51 | 77 | 24 | 17 |
| 9 | David M. Buss | 48 | 76 | 20 | 21 |
| 10 | Jasper A. J. Smits | 45 | 57 | 33 | 11 |
| 11 | Michael J. Telch | 45 | 67 | 23 | 17 |
| 12 | Hongjoo J. Lee | 44 | 70 | 18 | 24 |
| 13 | Cindy M. Meston | 44 | 55 | 34 | 10 |
| 14 | Jacqueline D. Woolley | 42 | 66 | 18 | 24 |
| 15 | Christopher G. Beevers | 41 | 62 | 20 | 21 |
| 16 | Marie H. Monfils | 41 | 67 | 16 | 27 |
| 17 | Samuel D. Gosling | 38 | 53 | 22 | 18 |
| 18 | Arthur B. Markman | 38 | 59 | 18 | 24 |
| 19 | David S. Yeager | 38 | 48 | 28 | 14 |
| 20 | Robert A. Josephs | 37 | 46 | 28 | 14 |
| 21 | Jennifer S. Beer | 36 | 51 | 20 | 21 |
| 22 | Frances A. Champagne | 34 | 55 | 13 | 34 |
| 23 | Marlone D. Henderson | 27 | 34 | 19 | 22 |