
A recent article by Nuijten, van Assen, Augusteijn, Crompvoets, and Wicherts reported the results of a meta-meta-analysis of intelligence research. The authors extracted 2442 eect sizes from 131 meta-analyses. The authors made these data openly available to allow “readers to pursue other categorizations and analyses” (p. 6). In this blog post, I report the results of an analysis of their data with z-curve.2.0 (Bartos & Schimmack, 2020; Brunner & Schimmack, 2020). Z-curve is a powerful statistical tool that can (a) examine the presence of publication bias and/or the use of questionable research practices, (b) provide unbiased estimate of statistical power before and after selection for significance when QRPs are present, and (c) estimate the maximum number of false positive results.
Questionable Research Practices
The term questionable research practices refers to a number of statistical practices that inflate the number of significant results in a literature (John et al., 2012). Nuijten et al. relied on the correlation between sample size and effect size to examine the presence of publication bias. Publication bias produces a negative correlation between sample size and effect size because larger effects are needed to get significance in studies with smaller samples. The method has several well-known limitations. Most important, a negative correlation is also expected if researchers use larger samples when they anticipate smaller effects, either in the form of a formal a priori power analysis or based on informal information about sample sizes in previous studies. For example, it is well-known that effect sizes in molecular genetics studies are tiny and that sample sizes are huge. Thus, a negative correlation is expected even without publication bias.
Z-curve.2.0 avoids this problem by using a different approach to detected the presence of publication bias. The approach compares the observed discovery rate (i.e., the percentage of significant results) to the expected discovery rate (i.e., the average power of studies before selection for significance). To estimate the EDR, z-curve.2.0 fits a finite mixture model to the significant results and estimates average power based on the weights of a finite number of non-centrality parameters.
I converted the reported information about sample size, effect size, and sampling error into t-values, and then converted the t-values. Extremely large t-values of 20 were fixed to a value of 20. Then t-values were converted into absolute z-scores.
Figure 1 shows a histogram of the z-scores in the critical range from 0 to 6. All z-scores greater than 6 are assumed to have a power of 1 with a significance threshold of .05 (z = 1.96).
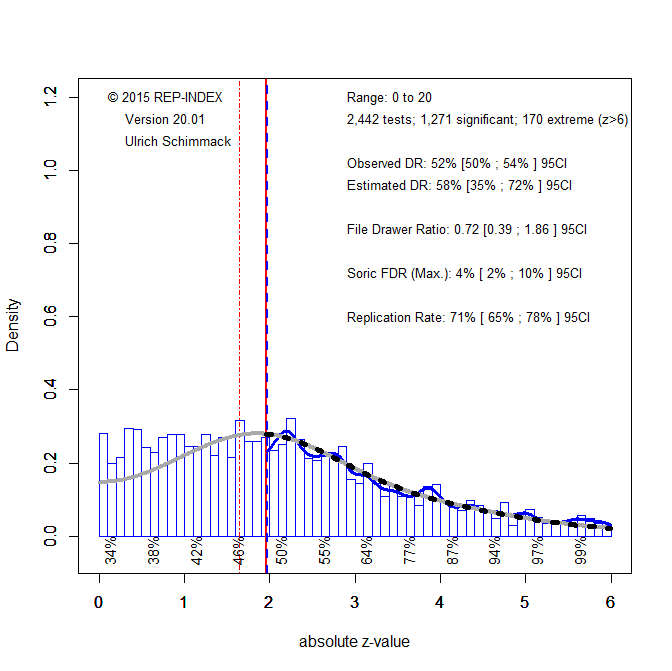
The critical comparison of the observed discovery rate (52%) and the expected discovery rate (58%) shows no evidence of QRPs. In fact, the EDR is even higher than the ODR, but the confidence interval is wide and includes the ODR. When there is no evidence that QRPs are present, it is better to use all observed z-scores, including the credible non-significant results, to fit the finite mixture model. Figure 2 shows the results. The blue line moved to 0, indicating that all values were used for estimation.
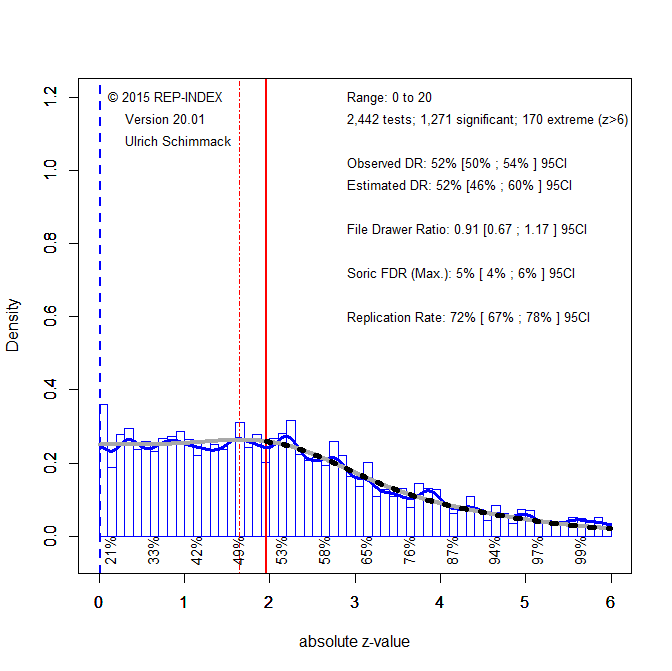
Visual inspection shows a close match between the observed distribution of z-scores (blue line) and the predicted distribution by the finite mixture model (grey line). The observed discovery rate now closely matches the expected discovery rate of 52%. Thus, there is no evidence of publication bias in the meta-meta-analysis of effect sizes in intelligence research.
Interestingly, there is also no evidence that researchers used mild QRPs to move marginally significant results just below .05 on the other side of the significance criterion to produce just significant results. There are two possible explanation for this. On the one hand, intelligence researchers may be more honest than other psychologists. On the other hand, it is possible that meta-analyses are not representative of the focal hypothesis tests that led to publication of original research articles. A meta-analysis of focal hypothesis tests in original articles is needed to answer this question.
In conclusion, this superior analysis of the presence of bias in the intelligence literature showed no evidence of bias. In contrast, Nuijten et al. (2020) found a significant correlation between effect sizes and sample sizes which they call small study effect. The problem with this finding is that it can reveal either careful planning of sample sizes (good practices) or the use of QRPs (bad practices). Thus, their analyses does not tell us whether there is bias in the data. Z-curve.2.0 resolves this ambiguity and shows that there is no evidence of selection for significance in these data.
Statistical Power
Nuijten et al. used Cohen’s classic approach to investigate power (Cohen, 1962). Based on this approach, they concluded “we found an overall median power of 11.9% to detect a small effect,54.5% for a medium effect, and 93.9% for a large effect (corresponding to a Pearson’s r of 0.1, 0.3, and 0.5 or a Cohen’s d of 0.2, 0.5, and 0.8, respectively)”
This information merely provides information about the sample sizes in the different studies. Studies with small sample sizes have low power to detect a small effect size. As most studies had small sample sizes, the average power to detect small effects is low. However, this does not tell us anything about the actual power of studies to obtain significant results for two reasons. First, effect sizes in a meta-meta-analysis are extremely heterogeneous. Thus, not all studies are chasing small effect sizes. As a result, the power of studies is likely to be higher than the average power to detect small effect sizes. Second, the previous results showed that (a) sample sizes correlate with effect sizes and (b) there is no evidence of QRPs. This means that researchers are a priori deciding to use smaller samples to search for larger effects and larger samples to search for smaller effects. This means that formal or informal a priori power analyses ensure that small samples can have as much or more power than large samples. It is therefore not informative to conduct power analysis only based on information about sample size. Z-curve.2.0 avoids this problem and provides estimates of the actual mean power of studies. Moreover, it provides two estimates of power for two different populations of studies. One population are all studies that are conducted by intelligence researchers without selecting for significance. This estimate is the expected discovery rate. Z-curve also provides an estimate for the population of studies that produced a significant result. This population is of interest because only significant results can be used to claim a discovery; with an error rate of 5%. When there is heterogeneity in power, the mean power after selection for significance is higher than the average power before selection for significance (Brunner & Schimmack, 2020). When researchers attempt to replicate a significant results to verify that it was not a false positive result, mean power after selection for significance provides the average probability that an exact replication study will be significant. This information is valuable to evaluate the outcome of actual replication studies (cf. Schimmack, 2020).
Given the lack of publication bias, there are two ways to determine mean power before selection for significance. We can simply compute the average of significant results and we can use the estimated discovery rate. Figure 2 shows that both values are 52%. Thus, the average power of studies conducted by intelligence researchers is 52%. This is well-below the recommended level of 80%.
The picture is a bit better for studies with a significant result. Here the average power called the expected replication rate is 71% and the 95% confidence interval approaches 80%. Thus, we would expect that more than 50% of significant results in intelligence research can be replicated with a significant result in the replication study. This estimate is higher than for social psychology, where the expected replication rate is only 43%.
False Positive Psychology
The past decade has seen a number of stunning replication failures in social psychology (cf. Schimmack, 2020). This has led to a concern that most discoveries in psychology if not in all sciences are false positive results that were obtained with questionable research practices (Ioannidis, 2005 ; Simmons et al., 2011). So far, however, these concerns are based on speculations and hypothetical scenarios rather than actual data. Z-curve.2.0 makes it possible to examine this question empirically. Although it is impossible to say how many published results are in fact false positive results, it is possible to estimate the maximum number of false-positive results based on the discovery rate. (Soric, 1989). As the observed and expected discovery are identical, we can use the value of 52% as our estimate of the discovery rate. This implies that no more than 5% of the significant results are false positive results. Thus, the empirical evidence shows that most published results in intelligence research are not false positives.
Moreover, this finding implies that most non-significant results are false negatives or type-II errors. That is, the null-hypothesis is also false for non-significant results. This is not surprising because many intelligence studies are correlational and the nil-hypothesis that there is absolutely no relationship between two naturally occurring variables has a low a priori probability. This also means that intelligence researchers would benefit from specifying some minimal effect size for hypothesis testing or to focus on effect size estimation rather than hypothesis testing.
Conclusion
Nujiten et al. conclude that intelligence research is plagued by QRPs. “Based on our findings, we conclude that intelligence research from 1915 to 2013 shows signs that publication bias may have caused overestimated effects”. This conclusion ignores that small-sample effects are ambiguous. The superior z-curve analysis shows no evidence of publication bias. As a result, there is also no evidence that reported effect sizes are inflated.
The z-curve.2.0 analysis leads to a different conclusion. There is no evidence of publication bias, significant results have a probability of 70% to be replicated in exact replication studies and even if exact replication studies are impossible the discovery rate of 50% implies that we should expect the majority of replication attempts with the same sample sizes to be successful (Bartos & Schimmack, 2020). In replication studies with larger samples even more results should replicate. Finally, most of the non-significant results are false negative results because there are few true null-hypothesis in correlational research. A modest increase in sample sizes could easy achieve 80% power which is typically recommended.
A larger concern is the credibility of conclusions based on meta-meta-analyses. The problem is that meta-analysis focus on general main effects that are consistent across studies. In contrast, original studies may focus on unique patterns in the data that can not be subjected to meta-analysis because direct replications of these specific patterns are lacking. Future research therefore needs to code the focal hypothesis tests in intelligence articles to examine the credibility of intelligence research.
Another concern is the reliance on alpha = .05 as a significance criterion. Large genomic studies have a multiple comparison problem where 10,000 analyses can easily produce hundreds of significant results with alpha = .05. This problem is well-known and genetics studies now use much lower alpha levels to test for significance. A proper power analysis of these studies needs to use the actual alpha level rather than the standard level of .05. Z-curve is a flexible tool that can be used with different alpha levels. Therefore, I highly recommend z-curve for future meta-scientific investigations of intelligence research and other disciplines.
References
Bartoš, F., & Schimmack, U. (2020). z-curve.2.0: Estimating replication and discovery rates. Under review.
Brunner, J., & Schimmack, U. (2020). Estimating population mean power under conditions of heterogeneity and selection for significance. Meta- Psychology. MP.2018.874, https://doi.org/10.15626/MP.2018.874
Cohen, J. (1962). The statistical power of abnormal-social psychological research: A review. Journal of Abnormal and Social Psychology, 65, 145–153. http://dx.doi.org/10.1037/h0045186
Ioannidis, J. P. A. (2005). Why most published research findings are false. PLoS Medicine, 2, e124. http://dx.doi.org/10.1371/journal.pmed.0020124
John, L. K., Loewenstein, G., & Prelec, D. (2012). Measuring the Prevalence of Questionable Research Practices With Incentives for Truth Telling. Psychological Science, 23(5), 524–532. https://doi.org/10.1177/0956797611430953
Schimmack, U. (2020). A meta-psychological perspective on the decade of replication failures in social psychology. Canadian Psychology/Psychologie canadienne. Advance online publication. https://doi.org/10.1037/cap0000246
Simmons, J. P., Nelson, L. D., & Simonsohn, U. (2011). False-positive psychology: Undisclosed flexibility in data collection and analysis allows presenting anything as significant. Psychological Science, 22, 1359 –1366. http://dx.doi.org/10.1177/0956797611417632
Sorić, B. (1989). Statistical “discoveries” and effect-size estimation.Journal of the American Statistical Association,84(406), 608-610.
This is very interesting work. I am interested in using zcurve but I think I would benefit from seeing some code. Is your analysis of the Nuijten, van Assen, Augusteijn, Crompvoets, and Wicherts data available? Specifically I would like to see how you turned their sample size, effect size, and sampling error into t-values, and then converted the t-values.
A test-statistic like a t-value is a ratio of the effect size over the sampling error, So ES/SE = t.
You can then use N-2 to get df, and get the p-value, which is the transformed using the inverse normal distribution into a z-score.
As the direction does not matter, the absolute values are used for the z-curve analysis.