Picture Credit: Wolfgang Viechtbauer
Abstract
Social psychology, or to be more precise, experimental social psychology, has a replication problem. Although articles mostly report successful attempts to reject the null-hypothesis, these results are obtained with questionable research practices that select for significance. This renders reports of statistical significance results meaningless (Sterling, 1959). Since 2011, some social psychologists are actively trying to improve the credibility of published results. A z-curve analysis of results in JESP shows that these reforms have had a mild positive effect, but that studies are still underpowered and that non-significant results are still suspiciously absent from published articles. Even pre-registration has been unable to ensure that results are reported honestly. The problem is that there are no clear norms that outlaw practices that undermine the credibility of a field. As a result, some bad actors continue to engage in questionable practices that advance their careers at the expense of their colleagues and the reputation of the field. They may not be as culpable as Stapel, who simply made up data, but their use of questionable practices also hurts the reputation of experimental social psychology. Given the strong incentives to cheat, it is wildly optimistic to assume that self-control and nudges are enough to curb bad practices. Strict rules and punishment are unpopular among liberal-leaning social psychologists (Fiske, 2016), but they may be the most effective way to curb these practices. Clear guidelines about research ethics would not affect practices of most researchers who are honest and who are motivated by truth, but it would make it possible to take actions against those who abuse the system for their personal gains.
Introduction
There is a replication crisis in social psychology (see Schimmack, 2020, for a review). Based on actual replication studies, it is estimated that only 25% of significant results in social psychology journals can be replicated (Open Science Collaboration, 2015). The response to the replication crisis by social psychologists has been mixed (Schimmack, 2020).
The “Journal of Experimental Social Psychology” provides an opportunity to examine the effectiveness of new initiatives to improve the credibility of social psychology because the current editor, Roger Giner-Sorrola, has introduced several initiatives to improve the quality of the journal.
Giner-Sorolla (2016) correctly points out that selective reporting of statistically significant results is the key problem of the replication crisis. Given modest power, it is unlikely that multiple hypothesis tests within an article are all significant (Schimmack, 2012). Thus, the requirement to report only supporting evidence leads to dishonest reporting of results.
“A group of five true statements and one lie is more dishonest than a group of six true ones; but a group of five significant results and one nonsignificant is more to be expected than a group of six significant results, when sampling at 80% statistical power.” (Gina-Sorrola, 2016, p. 2).
There are three solutions to this problem. First, researchers could reduce the number of hypothesis tests that are conducted. For example, a typical article in JESP reports three studies, which implies a minimum of three hypothesis tests, although often more than one hypothesis is tested within a study. The number of tests could be reduced by a third, if researchers would conduct one high-powered study rather than three moderately powered studies (Schimmack, 2012). However, the editorial did not encourage publication of a single study and there is no evidence that the number of studies in JESP articles has decreased.
Another possibility is to increase power to ensure that nearly all tests can produce significant results. To examine whether researchers increased power accordingly, it is necessary to examine the actual power of hypothesis tests reported in JESP. In this blog post, I am using z-curve to estimate power.
Finally, researchers may report more non-significant results. If studies are powered at 80%, and most hypotheses are true, one would expect that about 20% (1 out of 5) hypothesis tests produce a non-significant result. A simple count of significant results in JESP can answer this question. Sterling (1959) found that social psychology journals nearly exclusively report confirmation of predictions with p < .05. Motyl et al. (2017) replicated this finding for results from 2003 to 2014. The interesting question is whether new editorial policies have reduced this rate since 2016.
JESP has also adopted open-science badges that are rewarding researchers for sharing materials, sharing data, or pre-registering hypothesis. Of these badges, pre-registration is most interesting because it aims to curb the use of questionable research practices (QRPs, John et al., 2012) that are used to produce significant results with low power. Currently, there are relatively few articles where all studies are preregistered. However, JESP is interesting because editors sometimes request a final study that is preregistered following some studies that were not preregistered. Thus, JESP has published 58 articles with at least one preregistered study. This makes it possible to examine the effectiveness of preregistration to ensure more honest reporting of results.
Automated Extraction of Test Statistics
The first analyses are based on automatically extracted test statistics. The main drawback of automatic extraction is that it does not distinguish between manipulation checks and focal hypothesis tests. Thus, the absolute estimates do not reveal how replicable focal hypothesis tests are. The advantage of automatically extracted test-statistics is that it uses all test-statistics that are reported in text (t-values, F-values), which makes it possible to examine trends over time. If power of studies increases, test-statistics for focal and non-focal hypothesis will increase.
To examine time-trends in JESP, I downloaded articles from ZZZZ to 2019, extracted test-statistics, converted them into absolute z-scores, and analyzed the results with z-curve (Brunner & Schimmack, 2019; Bartos & Schimmack, 2020). To illustrate z-curve, I present the z-curve for all 45,792 test-statistics.
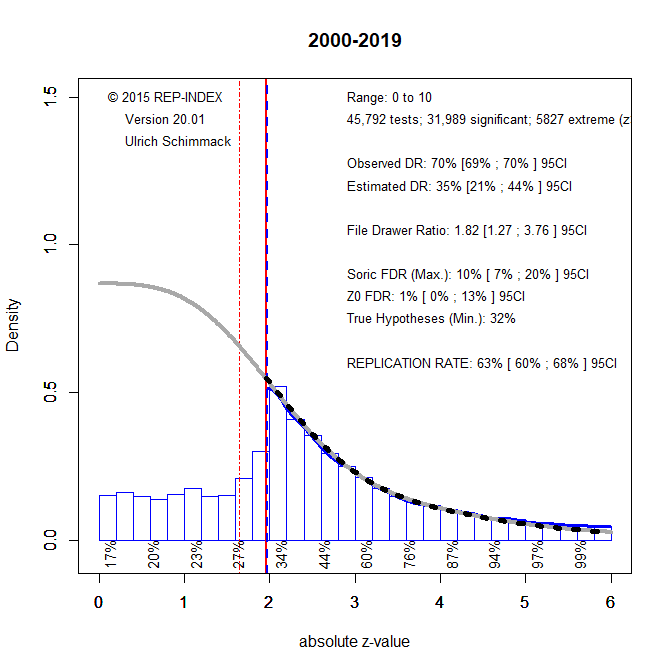
Visual inspection of the z-curve plot shows clear evidence that questionable research practices contributed to significant results in JESP. the distribution of significant z-scores peaks at z = 1.96, which corresponds to p = .05 (two-sided). At this point, there is a steep drop of reported results. Based on the distribution of significant results, z-curve also estimates the expected distribution of non-significant results (grey curve). There is a clear discrepancy between the observed frequencies of non-significant results and the expected frequencies of non-significant results. This discrepancy is quantified by the discovery rates; that is, the percentage of significant results. The observed discovery rate is 70%. The expected discovery rate is only 35% and the 95%CI ranges from 21% to 44%. Thus, the observed discovery rate is much higher than we would expect if there were no selection for significance in the reporting of results.
Z-curve also provides an estimate of the expected replication rate (ERR). This is the percentage of significant results that would be significant again if the studies could be replicated exactly with the same sample size. The ERR is 63% with a 95%CI ranging from 60% to 68%. Although this is lower than the recommended level of 80% power, it does not seem to justify the claim of a replication crisis. However, there are two caveats. First, the estimate includes manipulation checks. Although we cannot take replication of manipulation checks for granted, they are not the main concern. The main concern is that theoretically important, novel results do not replicate. The replicability of these results will be lower than 63%. Another problem is that the ERR is based on the assumption that studies in social psychology can be replicated exactly. This is not possible, nor is it informative. It is also important that results generalize across similar conditions and populations. To estimate the outcome of actual replication studies that are only similar to the original studies, the EDR is a better estimate (Bartos & Schimmack, 2020), and the estimate of 35% is more in line with the result that only 25% of results in social psychology journals can be replicated (Open Science Collaboration, 2015).
Questionable research practices are more likely to produce just-significant results with p-values between .05 to .005 than p-values below .005. Thus, one solution to the problem of low credibility, is to focus on p-values less than .005 (z = 2.8). Figure 2 shows the results when z-curve is limited to these test statistics.

The influence of QRPs now shows up as a pile of just-significant results that are not consistent with the z-curve model. For the more trustworthy results, the ERR increased to 85%, but more importantly, the EDR increased to 75%. Thus, readers of JESP should treat p-values above .005 as questionable results, while p-values below .005 are more likely to replicate. It is of course unclear how many of these trustworthy results are manipulation checks or interesting findings.
Figures 1 and 2 helped to understand ERR and EDR. The next figure shows time trends in the ERR (solid) and EDR (dotted) using results that are significant at .05 (black) and those significant at .005.
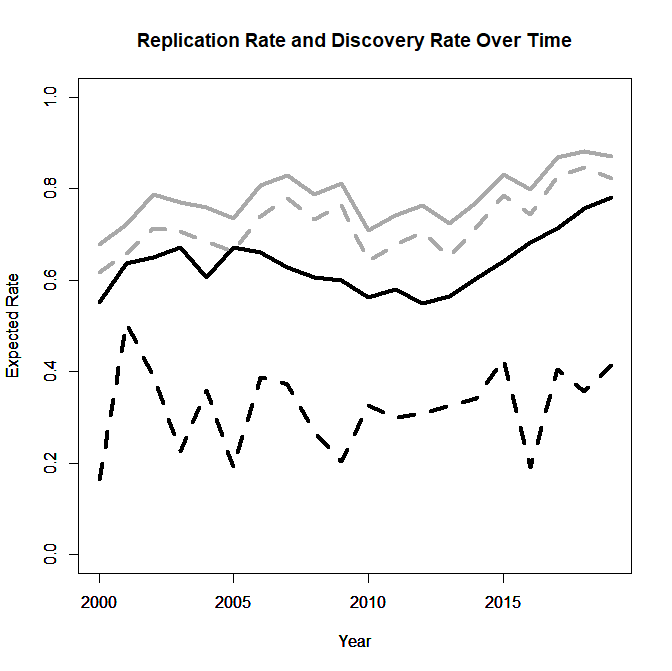
Visual inspection suggests no changes or even a decrease in the years leading up to the beginning of the replication crisis in 2011. ERR and the EDR for p-values below .005 show an increasing trend in the years since 2011. This is confirmed by linear regression analysis for the years 2012 to 2019, t(6)s > 4.62. However, the EDR for all significant results does not show a clear trend, suggesting that QRPs are still being used, t(6) = 0.84.
Figure 3 shows the z-curve plot for the years 2017 to 2019 to get a stable estimate for current results.

The main difference to Figure 1 is that there more highly significant results, which is reflected in the higher ERR of 86%, 95%CI = 82% to 91%. However, the EDR of 36%, 95%CI = 24% to 57% is still low and significantly lower than the observed discovery rate of 66%. Thus, there is still evidence that QRPs are being used. However, EDR estimates are highly sensitive to the percentage of just-significant results. Even excluded only results between 2 and 2.2, leads to a very different picture.
Most important, the EDR jumps from 36% to 73%, which is even higher than the ODR. Thus, one interpretation of the results is that a few bad actors continue to use QRPs that produce p-values between .05 and .025, while most other results are reported honestly.
In sum, the results based on automated-extraction of test statistics shows a clear improvement in recent years, especially for p-values below .005. This is consistent with observations that sample sizes have increased in social psychology (reference). The main drawback of these analysis is that estimates based on automated extraction do not reveal the robustness of focal hypothesis tests. This requires hand-coding of test statistics. These results are examined next.
Motyl et al.’s Hand-Coding of JESP (2003,2004,2013,2014).
The results for hand-coded focal tests justify the claim of a replication crisis in experimental social psychology. Even if experiments could be replicated exactly, the expected replication rate is only 39%, 95%CI = 26% to 49%. Given that they cannot be replicated exactly, the EDR suggests that as few as 12% of replications would be successful and the 95%CI includes 5%, meaning all significant results were false positives, 95%CI = 5% to 33%. The comparison to the observed discovery rate of 86% shows the massive use of QRPs to produce mostly significant results with low power. The time-trend analysis suggests that these numbers are representative of results in experimental social psychology until very recently (see also Cohen, 1962).
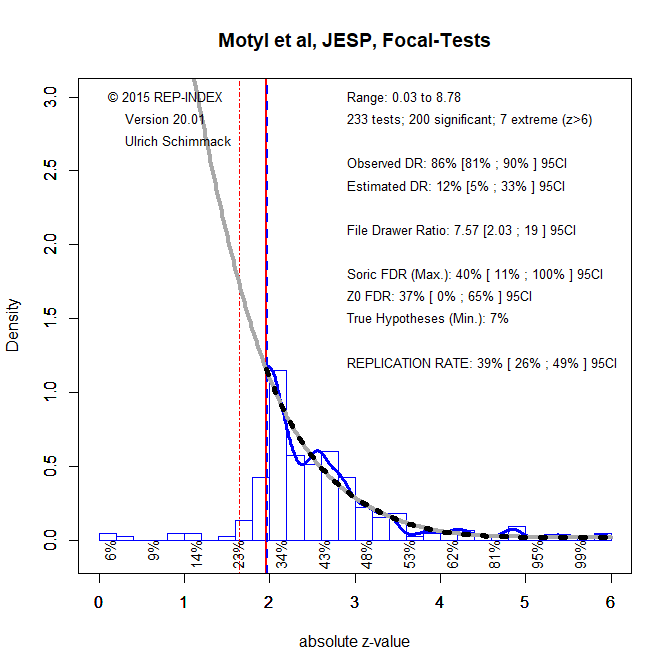
Focusing only on p-values below .005 may be a solution, but the figure shows that few focal tests reach this criterion. Thus, for the most part, articles in JESP do not provide empirical evidence for social psychological theories of human behavior. Only trustworthy replication studies can provide this information.
Hand-Coding of Articles in 2017
To examine improvement, I personally hand-coded articles published in 2017.
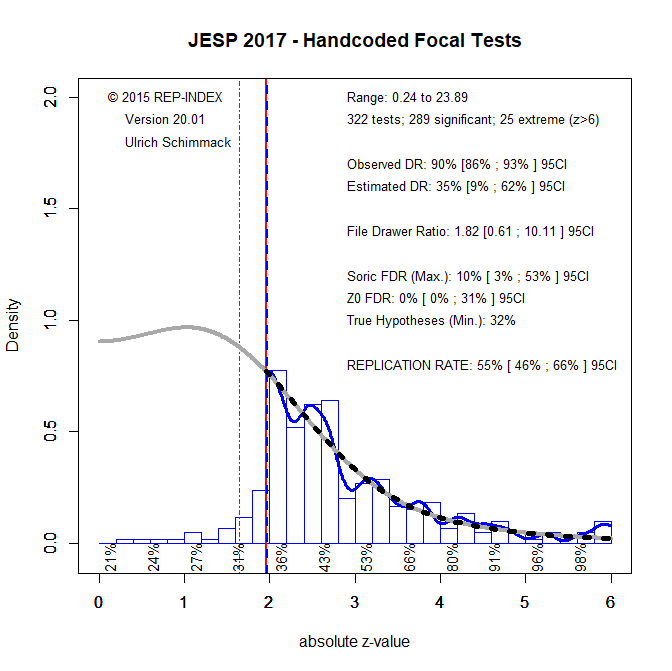
The ERR increased from 39% to 55%, 95%CI = 46% to 66%, and the confidence intervals barely overlap. However, the ERR did not show a positive trend in the automated analysis and even a value of 55% is still low. The EDR also improved from 12% to 35%, but the confidence intervals are much wider, which makes it hard to conclude from these results that this is a real trend. More important, an EDR of 35% is still not good. Finally. the results continue to show the influence of questionable research practices. The comparison of the ODR and EDR shows that many non-significant results that are obtained are not reported. Thus, despite some signs of improvement, these results do not show a radical shift in research practices that is needed to make social psychology more trustworthy.
Pre-Registration
A lot of reformers pin their hope on pre-registration as a way to curb the use of questionable research practices. An analysis of registered reports suggests that this can be the case. Registered reports are studies that are accepted before data are collected. Researchers then collect the data and report the results. This publishing model makes it unnecessary to use QRPs to produce significant results in order to get a publication. Preregistration in JESP is different. Here authors voluntarily post a data analysis plan before they collect data and then follow the preregistered plan in their analysis. To the extent that they do follow their plan exactly, the results are also not selected to be significant. However, there are still ways in which selection for significance may occur. For example, researchers may choose not to publish a preregistered study that produced a non-significant results or editors may not accept these studies for publication. It is therefore necessary to test the effectiveness of pre-registration empirically. For this purpose, I coded 210 studies in 58 articles that included at least one pre-registered study. There were 3 studies in 2016, 15 in 2017, 92 in 2018, and 100 in 2019. Five studies were not coded because they did not test a focal hypothesis or used sequential testing.
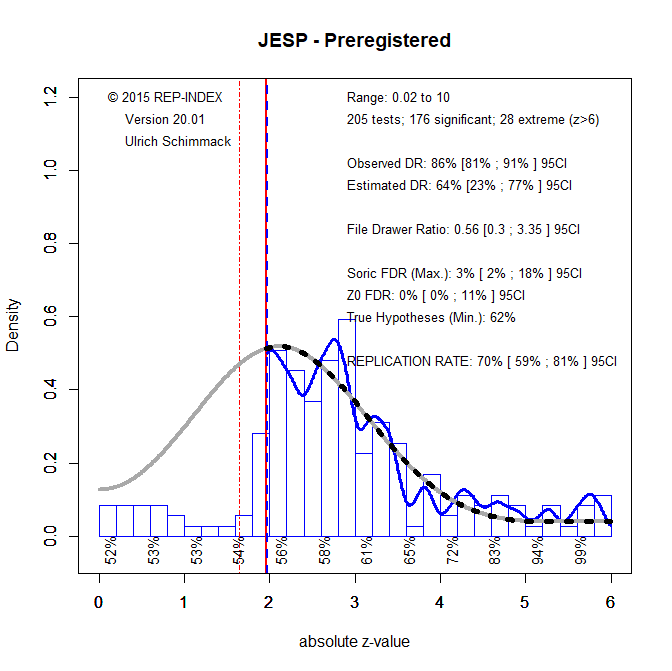
On a positive note, the ERR and EDR are higher than the comparison data for all articles in 2017. However, it is not clear how much of this difference is due to a simple improvement over time or preregistration. Not so good is the finding that the observed discovery rate is still high (86%) and this does not even count marginally significant results that are also used to claim a discovery. This high discovery rate is not justified by an increase in power. The EDR suggests that only 62% of results should be significant and the 95%CI does not include 86%, 95%CI = 23% to 77%. Thus, there is still evidence that QRPs are being used even in articles that receive a pre-registration badge.
One possible explanation is that articles can receive a pre-registration badge if at least one of the studies was pre-registered. Often this is the last study that has been requested by the editor to ensure that non-preregistered results are credible. I therefore also z-curved only studies that were pre-registered. There were 134 pre-registered studies.
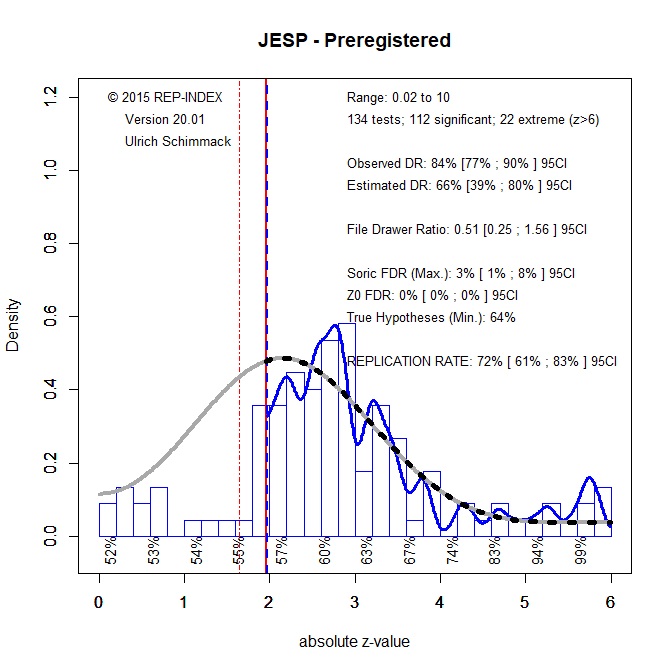
The results are very similar to the previous results with ERR of 72% vs. 70% and EDR of 66% vs. 64%. Thus, there is no evidence that pre-registered studies are qualitatively better and stronger. Moreover, there is also no evidence that pre-registration leads to more honest reporting of non-significant results. The observed discovery rate is 84% and rises to 90% when marginally significant results are included.
Conclusion
Social psychology, or to be more precise, experimental social psychology, has a replication problem. Although articles mostly report successful attempts to reject the null-hypothesis, these results are obtained with questionable research practices that select for significance. This renders reports of statistical significance results meaningless (Sterling, 1959). Since 2011, some social psychologists are actively trying to improve the credibility of published results. A z-curve analysis of results in JESP shows that these reforms have had a mild positive effect, but that studies are still underpowered and that non-significant results are still suspiciously absent from published articles. Even pre-registration has been unable to ensure that results are reported honestly. The problem is that there are no clear norms that outlaw practices that undermine the credibility of a field. As a result, some bad actors continue to engage in questionable practices that advance their careers at the expense of their colleagues and the reputation of the field. They may not be as culpable as Stapel, who simply made up data, but their use of questionable practices also hurts the reputation of experimental social psychology. Given the strong incentives to cheat, it is wildly optimistic to assume that self-control and nudges are enough to curb bad practices. Strict rules and punishment are unpopular among liberal-leaning social psychologists (Fiske, 2016). The problem is that QRPs hurt social psychology, even if it is just a few bad actors who engage in these practices. Implementing clear standards with consequences would not affect practices of most researchers who are honest and who are motivated by truth, but it would make it possible to take actions against those who abuse the system for their personal gains.
4 thoughts on “Estimating the Replicability of Results in ‘Journal of Experimental Social Psychology””