I wrote a commentary that made a very simple point. A published model assumed that the variance of z-scores is typically less than 1. I pointed out that this is not a reasonable assumption because the standard deviation of z-scores is at least one and often greater than 1, when studies vary in effect sizes, sample sizes, or both. This commentary was rejected. One reviewer even provided R-Code to make his or her case. Here is my rebuttal.
Here is the r-code provided by the reviewer. We see SDs of 0.59, 0.49 and 0.46. Based on these results, the reviewer thinks that setting a prior to a range of values between 0 and 1 is reasonable.

Let’s focus on the example that the reviewer claims is realistic for a p-value distribution for 80% power. The reviewer simulates this scenario with a beta distribution with shape parameters 1 and 31. The Figure shows the implied distribution of p-values. What is most notable is that p-values greater than .38 are entirely missing; the maximum p-value is .38.

In this figure 80% of p-values are below .05 and 20% are above .05. This is why the reviewer suggests that the pattern of observed p-values corresponds to a set of studies with 80% power.
However, the reviewer does not consider whether this distribution of p-values could arise from a set of studies where p-values are the result of the non-central parameter and sampling error that follows a sampling distribution.
To simulate studies with 80% power, we can simply use a standard normal distribution centered over 2.80. Sampling error will produce z-scores greater and smaller than the non-centrality parameter of 2.80. Moreover, we already know that the standard deviation of these tests statistics is 1 because z-scores have the standard normal distribution as a sampling distribution (a point made and ignored by the reviewers and editor).
We can know compute the two-tailed p-values for each z-test and plot the distribution of p-values. Figure 2 shows the actual distribution in black and the reviewer’s beta distribution in red.

It is visible that the actual distribution has a lot more p-values that are very close to zero, which corresponds to high z-scores. We can know transform the p-values into z-scores using the reviewers’ formula (for one-tailed tests).
y<-qnorm(mean=0,sd=1,p)
mean(y) #-2.54
sd(y) #1.11
We see that the standard deviation of these z-scores is greater than 1.
Using the correct formula for two-tailed p-values, we of course get the result that we already know to be true.
y = -qnorm(p/2)
mean(y) #2.80
sd(y) #1.00
It should be obvious that the reviewer made a mistake by assuming we can simulate p-value distributions with any beta-distribution. P-values cannot assume any distribution because the actual distribution of p-values is a function of the properties of the distribution of test-statistics that are used to compute p-values. With z-scores as test statistics it is well-known from intro statistics that sampling error follows a standard normal distribution, which is a normal distribution with a standard deviation of 1. Any transformation of z-scores into p-values and back into z-scores does not alter the standard deviation. Thus, the standard deviation has to be at least 1.
Heterogeneity in Power
The previous example assumed that all studies have the same amount of power. Allowing for heterogeneity in power, will further increase the standard deviation of z-scores. This is illustrated with the next example, where mean power is again 80%, but this time the non-centrality parameters vary with a normal distribution centered over 3.15 and a standard deviation of 1. Figure 3 shows the distribution of p-values which is even more extreme and deviates even more from the simulated beta-distribution by the reviewer.
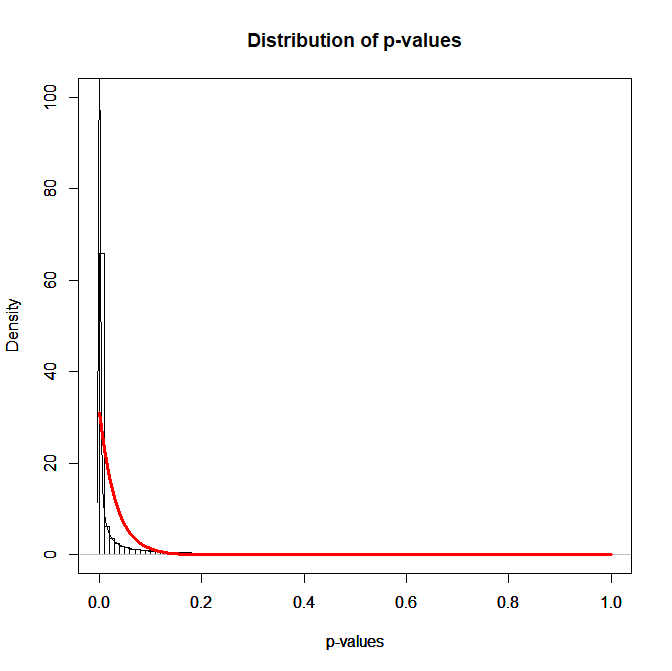
Using the reviewer’s formula, we now get a standard deviation of 1.54, but if we use the correct formula for two-tailed p-values, we end up with 1.41.
y<-qnorm(mean=0,sd=1,p)
mean(y) #-2.90
sd(y) #1.54
y = -qnorm(p/2)
mean(y) #3.16
sd(y) #1.39
This value makes sense because we simulated variation in z-scores with two standard normal distributions. One for the variation in the non-centrality parameters and one for the variation in sampling error. Adding two variances, gives a joint variance of 1 + 2 = 2, and a standard deviation of sqrt(2) = 1.41.
Conclusion
Unless I am totally crazy, I have demonstrated that we can use simple intro stats knowledge to realize that the standard deviation of p-values converted into z-scores has to be at least 1 because sampling error alone produces a standard deviation of 1. If the set of studies is heterogeneous and power varies across studies, the standard deviation will be even greater than 1. A variance less than 1 is only expected in unrealistic simulations or when researchers use questionable research practices, which reduces variability in p-values (e.g., all p-values greater than .05 are missing) and therewith also the variability in z-scores.
A broader conclusion is that the traditional publishing model in psychology is broken. Closed peer-review is too slow and unreliable to ensure quality control. Neither the editor of a prestigious journal, nor four reviewers were able to follow this simple line of argument. Open review is the only way forward. I guess I will be submitting this work to a journal with open reviews, where reviewers’ reputation is on the line and they have to think twice before they criticize a manuscript.
Quote from above: “A broader conclusion is that the traditional publishing model in psychology is broken. Closed peer-review is too slow and unreliable to ensure quality control.”
From the information i picked up here and there in the last years, i have come to the conclusion that peer-review as it is performed in the “traditional” journal-editor-peer reviewer model makes no sense. I even think it’s unscientific, and unethical.
I would even go so far to state that everyone still participating in that sh#t should have science points deducted from their “i am a scientist” card.
In all seriousness: why are you still participating in that bullsh#t? I checked the website of your university, and it stated there that you are a professor. If that means you are “tenured”, i reason you can’t be fired for not publishing in “official” journals, nor should you have to play the possible “publish or perish” game anymore.
I think if, and how, scientists use and/or cite papers is all the peer-review that makes sense (and is needed).
Yes, tenured and that gives me the freedom to blog, but pay raises are based on publications in peer-reviewed journals. So, I am taking a hit if I only blog and do not publish in peer-reviewed journals. Also, peer-review is not bad. I could make mistakes and nobody really comments on blogs. So, submitting work to a fair and open review by experts is not a bad thing. Glad we have progressive journals like Meta Psychology that value scientific accuracy over fake novelty and do not care about mistakes in published work.
“(…) but pay raises are based on publications in peer-reviewed journals.”
Ah, that is new information to me!
Why isn’t that stuff mentioned in all the recent discussions about the mess in academia?
Why aren’t all these “open science/let’s improve things” people talking, and doing something, about that?
p.s. thank you for your comment that review by others could be useful. I agree with that, but i think that should be done differently. For instance, you could ask colleagues to do that, and possibly reward them with co-authorship in case of a truly useful review/contribution, etc.