
I am not the first to describe the fight among statisticians for eminence as a war (Mayo Blog). The statistics war is as old as modern statistics itself. The main parties in this war are the Fisherians, Bayesians, and Neymanians (or Neyman-Pearsonians).
Fisherians use p-values as evidence to reject the null-hypothesis; the smaller the p-value the better.
Neymanians distinguish between type-I and type-II errors and use regions of test statistics to reject null-hypotheses or alternative hypotheses. They also use confidence intervals to obtain interval estimates of population parameters.
Bayesians differ from the Fisherians and Neymanians in that their inferences combine information obtained from data with prior information. Bayesians sometimes fights with each other about the proper prior information. Some prefer subjective priors that are ideally based on prior knowledge. Others prefer objective priors that do not require any prior knowledge and can be applied to all statistical problems (Jeffreysians). Although they fight with each other, they are united in their fight against Fisherians and Neymanians, which they call Frequentists.
The statistics war has been going on for over 80 years and there has been no winner. Unlike empirical sciences, there are no new data that could resolve scientific controversies. Thus, the statistics war is more like wars in philosophy where philosophers are still fighting over the right way to define fundamental concepts like justice or happiness.
For applied researchers these statistics wars can be very confusing because a favorite weapon of statisticians is propaganda. In this blog post, I examine the Bayesian Submarine (Morey et al., 2016), which aims to sink the ship of Neymansian confidence intervals.
The Bayesian Submarine
Submarines are fascinating and are currently making major discoveries about sea life. The Bayesian submarine is rather different. It is designed to convince readers that confidence intervals provide no meaningful information about population parameters and should be abandoned in favor of Bayesian interval estimation.
Example 1: The lost submarine
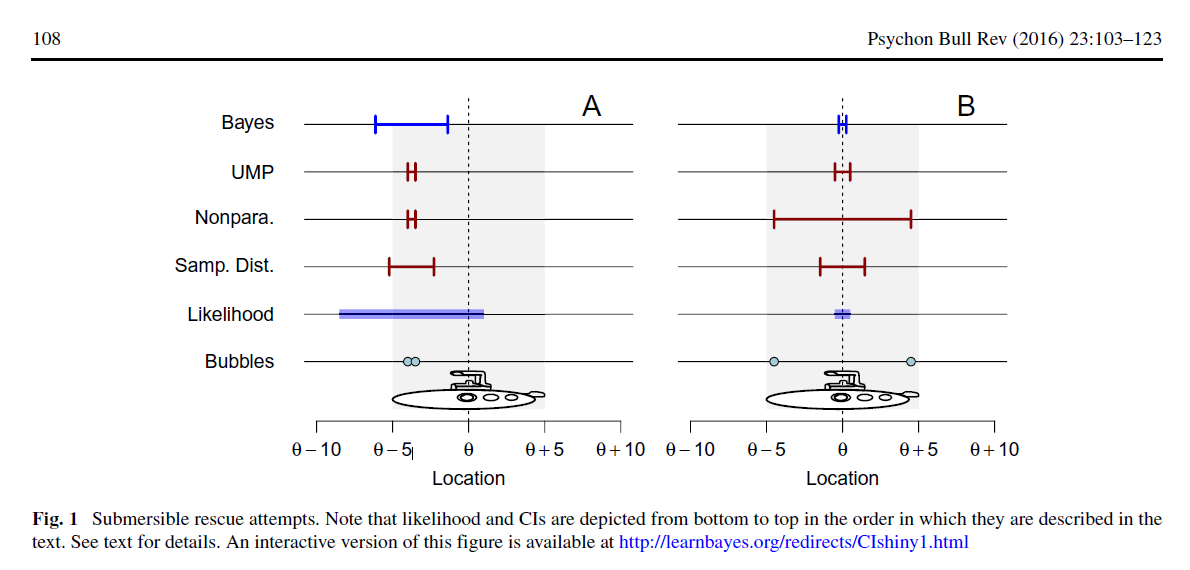
In this section, we present an example taken from the confidence interval literature (Berger and Wolpert, 1988; Lehmann, 1959; Pratt, 1961;Welch, 1939) designed to bring into focus how CI theory works. This example is intentionally simple; unlike many demonstrations of CIs, no simulations are needed, and almost all results can be derived by readers with some training in probability and geometry. We have also created interactive versions of our figures to aid readers in understanding the example; see the figure captions for details.
A 10-meter-long research submersible with several people on board has lost contact with its surface support vessel. The submersible has a rescue hatch exactly halfway along
its length, to which the support vessel will drop a rescue line. Because the rescuers only get one rescue attempt, it is crucial that when the line is dropped to the craft in the deep water that the line be as close as possible to this hatch. The researchers on the support vessel do not know where the submersible is, but they do know that it forms two distinctive bubbles. These bubbles could form anywhere along the craft’s length, independently, with equal probability, and float to the surface where they can be seen by the support vessel.
The situation is shown in Fig. 1a. The rescue hatch is the unknown location θ, and the bubbles can rise from anywhere with uniform probability between θ − 5 meters (the
bow of the submersible) to θ+5 meters (the stern of the submersible).
Let’s translate this example into a standard statistical problem. It is uncommon to have a uniform distribution of observed data around a population parameter. Most commonly, we assume that observations are more likely to cluster closer to the population parameter and that deviations between the population parameter and an observed value reflect some random process. However, a bound uniform distribution also allows us to compute the standard deviation of the randomly occurring data.
round(sd(runif(100000,0,10)),2) = 2.89
We only have two data points to construct a confidence interval. Evidently, the standard error based on a sample size of n = 2 is large (1/sqrt(2) = .71 (or 71% of a standard deviation). We can use the typical formula for sampling error, SD/sqrt(N) to estimate the sampling error as 2.89/1.41 = 2.04.
To construct a 95% confidence interval, we have to multiply the sampling error by the critical t.value for a probability of .975, which leaves .025 for the error region. Multiplying this by 2 gives a two-tailed error probability of .025 & 2 = 5%. That is, 5% of observations could be more extreme than the boundaries of the confidence interval just by chance alone. With 1 degree of freedom, we get a value of 12.71.
n = 2; alpha = .05; qt(1-alpha/2,n-1)
The width of the CI is determined by the standard deviation and sample size. So, the information is sufficient to say that the 95%CI is the observed mean +/- 2.04m * 12.71 = 25.92m.
Hopefully it is obvious that this 95%CI covers 100% of all possible values because the length of the submarine is limited to 10m.
In short, two data points provide very little information and make it impossible to say anything with confidence about the location of the hatch. Even without these calculations we can say with 100% confidence that the hatch cannot be further from the mean of the two bubbles than 5 meters because the maximum distance is limited by the length of the submarine.
The submarine problem is also strange because the width of confidence intervals is irrelevant for the rescue operation. With just one rescue line, the most optimal place is the mean of the two bubbles (see Figure, all intervals are centered on the same point). So, the statisticians do not have to argue, because they all agree on the location where to drop the rescue line.
How is the Bayesian submarine supposed to sink confidence intervals?
The rescuers first note that from observing two bubbles, it is easy to rule out all values except those within five meters of both bubbles because no bubble can occur further than 5 meters from the hatch.
Importantly, this only works for dependent variables with bounded values. For example, on an 11-point scale ranging from 0 to 10, it is obvious that any population mean cannot deviated from the middle of the scale (5) by more than 5 points. Even there it is not very relevant because the goal of research is not to find the middle of the scale, but to estimate the actual population parameter that could be anywhere between 0 and 10. Thus, the submarine example does not map on any empirical problem of interval estimation.
1. A procedure based on the sampling distribution of the mean
The first statistician suggests building a confidence procedure using the sampling distribution of the mean M . The sampling distribution of M has a known triangular distribution with θ as the mean. With this sampling distribution, there is a 50 % probability that M will differ from θ by less than 5 − 5/ √2, or about 1.46m.
This leads to the confidence procedure M = +/- 5 − 5/√2
which we call the “sampling distribution” procedure. This procedure also has the familiar form ¯x ± C × SE, where here the standard error (that is, the standard deviation of the estimate M) is known to be 2.04.
It is important to note that the authors use a 50% CI. In this special case, the confidence interval is equivalent to the standard deviation because the standard deviation is multiplied by 1 to determine the width of the confidence interval.
n = 2; alpha = .50; qt(1-alpha/2,n-1)
The choice of a 50%CI is also not typical in actual research settings. It is not clear, why we should accept such a high error rate, especially when the survival of the crew members is at stake. Imagine that the submarine had an emergency system that releases bubbles from the hatch, but the bubbles do not go straight to the surface. Yet there are hundreds of bubbles. Would we compute a 50% confidence interval or would we want to get a 99% confidence interval to bring the rescue line as close to the hatch as possible?
We still haven’t seen how the Bayesian submarine sinks confidence intervals. To make their case, the Bayesian soldiers compute several possible confidence intervals and show how they lead to different conclusions (see Figure). They suggest that this is a fundamental problem for confidence intervals.
It is clear, first of all, why the fundamental confidence fallacy is a fallacy.
They are happy to join forces with the Fisherians in their attack of Neymanian confidence intervals, while they usually attack Fisher for his use of p-values.
As Fisher pointed out in the discussion of CI theory mentioned above, for any given problem — as for this one — there are many possible confidence procedures. These confidence procedures will lead to different confidence intervals. In the case of our submersible confidence procedures, all confidence intervals are centered around M, and so the intervals will be nested within one another.
If we mistakenly interpret these observed intervals as having a 50 % probability of containing the true value, a logical problem arises.
However, shortly after the authors bring up this fundamental problem for confidence intervals, they mention that Neyman solved this logical problem.
There are, as far as we know, only two general strategies for eliminating the threat of contradiction from relevant subsets: Neyman’s strategy of avoiding any assignment of probabilities to particular intervals, and the Bayesian strategy of always conditioning on the observed data, to be discussed subsequently.
Importantly, Neyman’s solution to the problem does not lead to the Bayesians’ conclusion that he suggested we should not make probabilistic statements based on confidence intervals. Instead, he argued that we should apply the long-run success rate to make probability judgments based on confidence intervals. This use of the term probability can be illustrated with the submarine example. A simple simulation of the submarine problem shows that the 50% confidence interval contains the population parameter 50% of the time.
It is therefore reasonable to place relatively modest confidence in the belief that the hatch of the submarine is within the confidence interval. To be more confident, it would be necessary to lower the error rate, but this makes the interval wider. The only way to be confident with a narrow interval is to collect more data.
Confidence intervals do have exactly the properties that Neyman claimed they have and there is no logical inconsistency between the statement that we cannot quantify the probability of singular events, while we can use long-run outcomes of similar events to make claims about the probability of being right or wrong in a particular event.
Neyman compares this to gambling where it is impossible to say anything about the probability of a particular bet unless we know the long-run probability of similar bets. Researchers who use confidence intervals are no different from people who drive their cars with confidence because they never had an accident or who order a particular pizza because they ordered it many times before and liked it. Without any other relevant information, the use of long-run frequencies to assign probabilities to individual events is not a fallacy.
Conclusion
So, does the Bayesian submarine sink the confidence interval ship? Does the example show that interpreting confidence intervals as probabilities is a fallacy and a misinterpretation of Neyman? I don’t think so.
The probability of winning a coin toss (with a fair coin) is 50%. What is the probability that I win any specific game. It is not defined. It is 100% if I win and 0% if I don’t win. This is trivial and Neyman made it clear that he was not using the term probability in this sense. He also made it clear that he used the term probability to refer to the long-term proportion of correct decisions and most people would feel very confident in their beliefs and decision making if the odds of winning were 95%. Bayesians do not deny that 95% confidence intervals give the right answer 95% of the time. They just object to the phrase, “There is a 95% probability that the confidence interval includes the population parameter” when a researcher uses a 95%confidence interval. Similarly, they would object to somebody saying “There is a 99.9% chance that I am pregnant” when a pregnancy test with a 0.01% false positive rate shows a positive result. The woman is either pregnant or she is not, but we don’t know this until she does repeat the test several times or an ultrasound shows it. As long as there is uncertainty about the actual truth, the long-run frequency of false positives quantifies the rational belief in being pregnant or not.
What should applied researchers do. They should use confidence intervals with confidence. If Bayesians want to argue with them, all they need to say is that they are using a procedure that has a 95% probability of giving the right answer and it is not possible to say whether a particular result is one of the few errors. The best way to address this question is not to argue about semantics, but to do a replication study. And that is the good news. While statisticians are busy fighting with each other, empirical scientists can make progress by collecting more informative data and make actual progress.
In conclusion, the submarine problem does not convince me for many reasons. Most important, it is not even necessary to create any intervals to decide on the best action. Absent any other information, the best bet is to drop the rescue line right in the middle of the two bubbles. This is very fortunate for the submarine crew because otherwise the statisticians would still be arguing about the best course of action, while the submarine is running out of air.
I read several versons of this paper. An earlier version of this paper included a much better and convincing example that Cis suck. The example is like this.
Consider sampling from a normal distribution to estimate a population mean. The population sd is unknown. Assume the true mean is zero, unknown to you (no effect), but you also test H0: mu = 0.
It turns out that coverage > .95 for those instances where |t|< 1, and coverage 1. Or, coverage is not .95 but correlated to the value of t!
Conclusion: a 95% confidence interval is no longer a 95% ci after observing the data (in many common examples). So, why using a 95% CI? A 95% CI only says something about a procedure, but who cares about that when a researcher wants to say something about confidence for the data at hand?
This example is so convincing, that it convinced me that CIs are not at all that useful. What about you, Uli?
Sorry, coverage > .95 if |t| > 1, hence coverage is correlated with t and not 95%.
Mmm, I notice something is wrong with how I describe the example, it has to do with the hypothesis, sorry. I will ask for the original example.
The basic logic is that the t-value is also determined by the se of the mean. High t-values are correlated with smaller se and therefore short ci, leading to LOWER coverage. Whereas low t-values are correlated with higher se and therefore wide CI, leading to HIGHER coverage.
Only before sampling, the coverage of 95% Ci is 0.95. Sorry for confusion, just woke up.
All statistical tests make assumptions. When these assumptions are violated, the results will be wrong. I am just working on the second example in the published paper and here they use a faulty approach to generalize to all confidence intervals. There are several ways to get good confidence intervals for the amount of explained variance in a regression model (ANOVA with three groups is just regression).
So, it is just another example, how these authors like to use confusing special cases and then induce from one very contrived case to all cases. This is of course a fallacy. Showing confidence intervals are not always right is different from demonstrating that they are always wrong.
It would be much better if some trained Ph.D statisticians would critique this article, but I think they busy with making progress in statistics and don’t have the time or motivation to care about the low quality publications by psychologists.
I have never being convinced by what the yellow submarine attempts to show.
In a commentary I uploaded as a preprint in PsyArxiv–see https://psyarxiv.com/kvxc4–(after being rejected by the Psychonomic Bulletin and Review), I noted: “A. . .note of interest is to caution about the misleading environment that simulations provide. . . Simulations also lead to a fallacy of hindsight reasoning, namely because we know where the parameter lies (a.k.a., the outcome), so it is easy to ascertain which interval captures it or not, and with what precision. In real research, however, we do not have such prerogative; for example, I do not know what to gain from Morey et al.’s Figure 1, as I can see where the submarine is as well as I can appreciate that most intervals are equally bad at capturing the hatch in A and equally good at capturing the hatch in B. (Add to it that there is only one chance to save the crew and no procedure to decide which portion of the interval to use—therefore it is reasonable to assume the decision would be to use the centre of the selected interval—in which case parameter estimation is more relevant than estimation by interval, the crew would be dead under any of the intervals in Fig.1A and it would be saved under any of the intervals in B.)”
I do not think the statistics wars are really “credible”, either, but are based on fighting over trivialities than over real consequences. In fact, I can see the different statistical approaches (at least as far as estimation by intervals goes) as hierarchically nested into each other. “I talked about frequentist-based probabilities being nested into higher-level environments (statistical model – resampling – long-run behaviour), a feature which does not prevent Frequentism itself from being nested into a higher-level environment that allows for beliefs other than models’ assumptions to be taken into account. Bayesian statistics is such higher-level environment, capable of subsuming frequency statistics within the likelihood apparatus of its logic. Thus, not only one should expect coverage intervals to numerically correspond to credible intervals under certain Bayesian conditions (such as when using uniform priors or under the principle of stable estimation, Phillips, 1973 ; also Edwards, Lindman, & Savage, 1963 ), but this should be taken as a consequence of such nesting and not merely as a “hand-waving defense of confidence intervals” (Morey et al., 2016, p. 119). Thus, a Bayesian can, under certain inferential conditions, consider a coverage interval to be a credible interval (a.k.a., it shows sufficient, although not necessary, likelihood for such interpretation). The opposite is not true, and a frequentist confidence interval cannot inherit higher-level Bayesian interpretations it does not possess.”
Reblogged this on Casual no es Causal.