Poor Undergraduate Education in Statistics
Psychologists are not famous for their quantitative chops. Many undergraduate students treat statistics courses as an ordeal to survive, not a skill to master. In North America especially, large psychology departments rely on large undergraduate programs for funding, which creates pressure to keep students happy. One way to do that is to offer “statistics-light” courses that avoid scaring off tuition-paying customers. As a result, most psychology majors graduate believing that the key to scientific discovery is to get p-values below .05, and that the results in their textbooks are trustworthy simply because they are “statistically significant.”
Graduate Training Isn’t Much Better
The situation doesn’t improve much in graduate school. Students learn how to point-and-click their way through statistical software, run analyses, and search for p-values below .05—this time with the added incentive that significant results mean publications for them and their advisors.
Over sixty years ago, Sterling (1959) warned that this obsession with p < .05 undermines the already limited value of p-values. Cohen (1994) memorably satirized the mindset with his title “The Earth is Round, p < .05.”
Sterling (1995) also documented a glaring oddity: psychology papers overwhelmingly report significant results—often 90% or more. That kind of hit rate would require researchers to be right almost all the time in their predictions. Given that most psychologists use two-sided tests (“Does X increase or decrease Y?”), they can claim a “hit” in either direction. The only way to be wrong is if the true effect is exactly zero—something many argue is rare.
But there’s another reason to be skeptical: to produce so many p < .05 results without fraud or extreme data-torturing, studies would need high statistical power. And here’s the rub—psychologists’ understanding of power is notoriously shaky. Even some quantitative psychologists, who should know better, end up publishing articles that confuse rather than clarify (see Pek et al., 2024).
What Power Actually Means
I’ve taught undergraduates about statistical power for over a decade, and AI can now spit out perfectly serviceable definitions in seconds. Here’s one example:
Statistical power is the probability that a statistical test will correctly reject the null hypothesis (H₀) when a specific alternative hypothesis (H₁) is true—in other words, the probability of detecting an effect if it exists. Power = 1 − β, where β is the Type II error rate.
Power depends on:
Effect size (true magnitude of the effect)
Sample size (bigger samples, higher power)
Significance level α (threshold for rejecting H₀)
Variability (less noise, more power)
Power is Unknown
Why care? High power reduces false negatives, makes non-significant results interpretable, supports replicability, and prevents waste of resources. Most important, power helps researchers to get the desirable p-values below .05. Why would you not plan studies to have a high probability to get a significant result, as long as the effect is not really zero.
The problem is that power depends on the the true (population) effect size. We never actually know this value—we only estimate it from samples, and those estimates vary because of sampling error. This uncertainty is not a special flaw in power analysis; it’s the nature of empirical research.
When planning studies, researchers must guess effect sizes, plug them into a formula, and get a required sample size—often aiming for the conventional 80% power. In practice, that number often comes from convenience (“How many participants can we realistically get?”) rather than a solid prior estimate and sometimes power analysis are fudged to put in a sample size and get the effect size that would give 80% power.
What 80% Power Looks Like
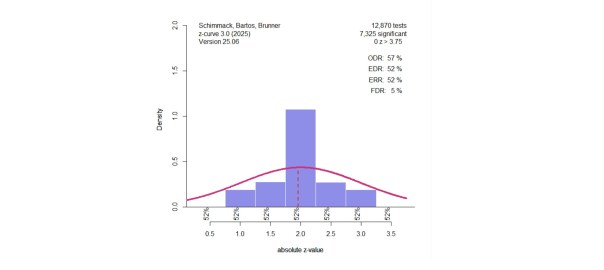
If we truly designed studies with 80% power and guessed the effect size perfectly, the resulting test statistics (converted to z-values) would form a predictable distribution:
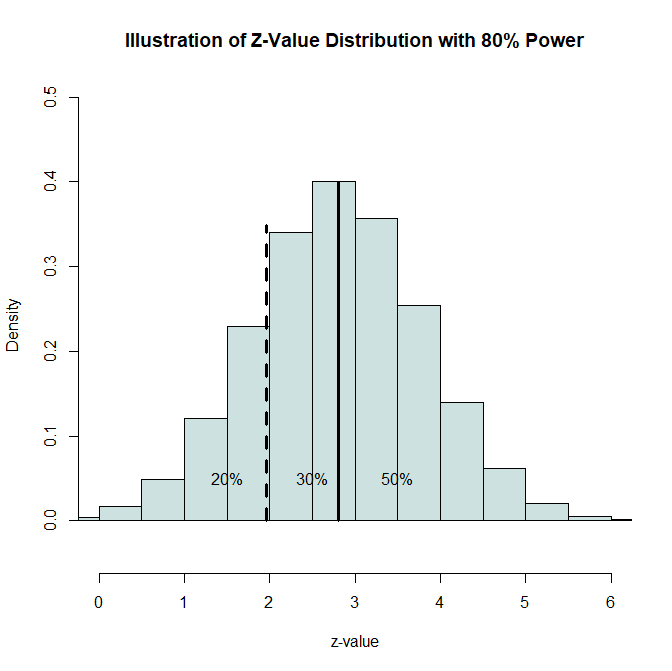
Figure 1. Distribution of z-values with 80% power. The dashed line marks the significance threshold (z = 1.96, p = .05), and the solid line marks the expected mean z for 80% power (z ≈ 2.8).
- 20% fall below the significance cut-off (non-significant)
- 30% are significant but below the expected mean
- 50% exceed the expected mean
This breakdown is a theoretical benchmark. If actual published results deviate strongly from it—say, 90% significant results instead of 80%—we know that our hypothesis that all studies have 80% power is wrong. Either researchers consistently underestimated effect sizes (unlikely), or results were selectively reported to favor significance (more likely).
Why Pek et al. Are Wrong About “Only for Planning”
Pek et al. (2024) argue that power is fine for planning studies but should not be used to evaluate completed ones. This is like saying we can predict a distribution under the null hypothesis and use it to interpret p-values, but once we see our data, that prediction magically disappears. It doesn’t. It is actually needed to draw inferences from the observed p-values. Thus, we are comparing actual data to a hypothetical distribution to make inferences about the direction of an effect.
The same is true for hypotheses about power. If we assume 80% power, we can predict the shape of the sampling distribution (Figure 1) and compare it with actual published data. Deviations tell us whether the true power was likely higher, lower, or compromised by selective reporting.
A Simple Example
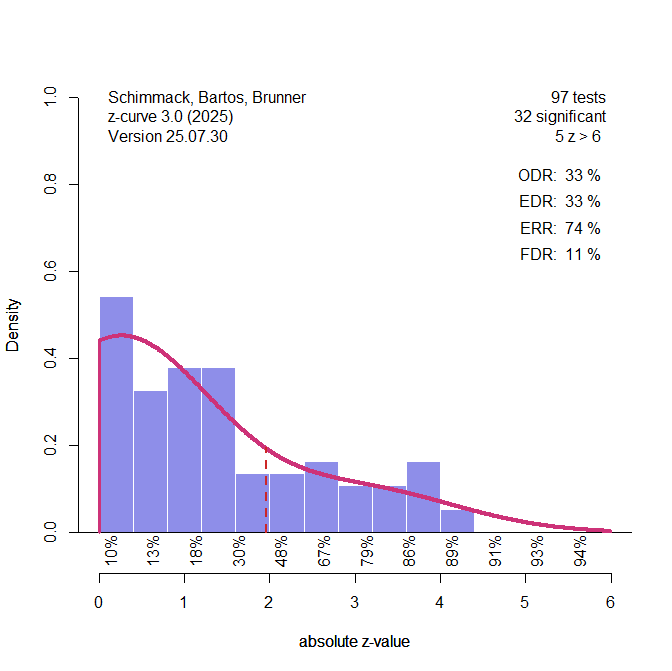
Consider Wegener & Petty (1996), Study 2, which had three independent samples. The key interaction effect produced z-values of 2.03, 1.99, and 2.53. All are significant but fall between 1.96 and 2.8.
With 80% power, there’s only about a 30% chance of landing in this range in a single study. Doing so three times in a row has a probability of about 0.027—well below the usual 0.05 cut-off. This suggests the results were not from well-powered studies that got lucky to produce 100% significant results with 80% power, but more consistent with low power plus selective significance.
The Real Value of Power
Ironically, power is not that useful for planning studies—because effect sizes are unknown and easily fudged. Its real strength is as a diagnostic tool for evaluating the credibility of published results. If the distribution of test statistics doesn’t match what we’d expect from a plausible power level, we have reason to doubt the findings.
This doesn’t require knowing the exact “true” power—just as we can test the null hypothesis without already knowing the population effect size. Similarly, we can make predictions based on hypotheses about power and use them to evaluate observed data. It just does not follow, that we can draw inferences from normal distributions at 0, but not from normal distributions centered at 2.8 or some other value, but many psychologists confuse null-hypthesis testing with nil-hypothesis testing (Cohen, 1994).
Final Thoughts
The resistance to using power this way is puzzling. Maybe it’s a misunderstanding of the concept, maybe it’s a desire to shield the literature from uncomfortable scrutiny. Either way, learning about power is not just a technical exercise—it’s a tool for scientific self-defense. If you see a literature where most p-values cluster between .05 and .005, be skeptical. If they’re mostly below .005, you can have more confidence.
Understanding power gives you the ability to look beyond “statistically significant” and ask: Was this result ever likely to be true?