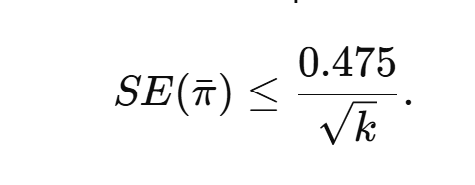Since Cohen (1962) published his famous article on statistical power in psychological journals, statistical power has not increased. The R-Index makes it possible f to distinguish studies with high power (good science) and studies with low power (bad science). Protect yourself from bad science and check the R-Index before you believe statistical results.
View all posts by Ulrich Schimmack →
For over sixty years, psychologists have been told that their studies are underpowered. Starting with Cohen (1962) and repeated by Sedlmeier and Gigerenzer (1989), Maxwell (2004), Button et al. (2013), and countless meta-analyses, the message has been consistent: our typical studies lack the statistical sensitivity to detect true effects.
This “power failure” has been a cornerstone of the open science movement and a standard explanation for the replication crisis.
But according to a recent Psychological Methods editorial decision, that entire literature rests on a fundamental ontological error.
Apparently, there is no power failure—because, by definition, completed studies do not have power.
The New Logic
In the journal’s interpretation (based on Pek, Hoisington-Shaw, & Wegener, 2024):
Statistical power is a property of a test, not of a study.
It is defined only before data are collected, for a hypothetical infinite series of replications with a fixed true effect size.
Once data exist, the test’s long-run property no longer applies; therefore, it makes no sense to speak of a study’s power—past or present.
Hence, Cohen (1962) didn’t actually discover that psychology was underpowered. He merely performed a few algebraic exercises about hypothetical tests. The claim that real studies were underpowered is, under this logic, a category mistake.
The Consequences of Redefinition
If this view is taken seriously:
Cohen (1962, 1988), Sedlmeier & Gigerenzer (1989), Rossi (1990), Maxwell (2004), and Button et al. (2013) all committed the same “ontological error.”
There can be no such thing as observed or average power, since power is not a property of results.
And since no real study can ever be “underpowered,” there can be no “power failure” to explain replication failures.
Replication failures must therefore be due to something else—perhaps the planets, bad luck, or metaphysical indeterminacy.
The Irony
Of course, the same journal publishes meta-analyses that estimate “average power” and discuss its implications for replicability. It also accepts simulations in which average power determines expected replication rates. But when that same concept is applied to actual psychological research, it suddenly becomes “ontologically incoherent.” In other words, power matters—except when it matters.
The Bigger Picture
Sarcasm aside, this position would erase one of the few robust empirical generalizations about psychology:
that typical studies have a low probability of detecting true effects.
and that publication bias explains the 90% success rates in psychology journals (Sterling, 1959; Sterling et al., 1995; Motyl et al., 2017).
That claim—whether estimated via Cohen’s early surveys, Sedlmeier & Gigerenzer’s analyses, or modern bias-corrected methods like z-curve—has accurately predicted the replication crisis.
To declare the concept meaningless is not theoretical progress; it’s conceptual retreat. It protects the purity of Neyman–Pearson logic at the cost of empirical relevance. If taken literally, the new Psychological Methods stance means that “power” applies only to imaginary studies—and that real studies, by definition, can never fail.
Closing Line
So congratulations, psychology. After six decades of self-criticism, we can finally declare victory: our research is not underpowered—because power no longer exists.
This blog post was written in collaboration with ChatGPT5
Why Most Published Clinical Trials Are Not False (Ioannidis & Trikalinos, 2007)
John Ioannidis became world-famous for his 2005 essay, Why Most Published Research Findings Are False. That paper used a set of hypothetical assumptions—low power, low prior probabilities, and selective reporting—to argue that the majority of published results must be false positives. The title was rhetorically brilliant, but the argument was theoretical, not empirical.
Only two years later, Ioannidis co-authored a real data analysis that quietly contradicted his earlier claim.
1. From theory to data
In 2007, Ioannidis and Thomas Trikalinos published An Exploratory Test for an Excess of Significant Findings in Clinical Trials. They examined large meta-analyses of clinical trials, comparing the number of reported significant results to the number expected based on estimated statistical power. Their results revealed low power—around 30 % on average—but not an excess of significant findings.
2. Low power ≠ high false-positive risk
Low power increases sampling error within a single study, but it does not automatically mean that half the published results are false. As Soric (1989) showed, even with 30 % power and α = .05, the maximum false discovery rate cannot exceed 13 %, much lower than Ioannidis’s claimed in his 2005 article.
3. Small publication bias
The Clinical Trials paper found that observed success rates were only slightly higher than expected power. That implies small publication bias and relatively little inflation of effect-size estimates. Unlike psychology or social science—where success rates approach 90 %—clinical trials appeared statistically honest.
4. Replicable evidence
Most of the meta-analyses Ioannidis & Trikalinos reviewed show clear, replicated effects that rule out the null hypothesis. When multiple independent low-power studies all point in the same direction, the probability that all are false positives becomes vanishingly small.
5. Later confirmation: Jager & Leek (2014)
Jager and Leek analyzed thousands of p-values from top medical journals and estimated a false-positive risk of about 14 % for individual clinical trials—remarkably consistent with the 2007 findings and with Soric’s theoretical upper bound. Schimmack & Bartos (2023) replicated this estimate using a bias-corrected z-curve approach.
6. Ioannidis’s response
Despite this convergence, Ioannidis rejected Jager & Leek’s conclusions in a 2014 Biostatistics commentary, arguing their model was “overly optimistic.” He did not mention that his own 2007 results implied the same low false-positive risk. Instead, he continued to promote the notion that more than half of published findings are false—an idea that captured headlines but not empirical reality.
7. The irony
Ioannidis became a global authority on “research unreliability” and a professor at Stanford largely because of a provocative title, not because of evidence that his 2005 hypothesis was true. Ironically, his own empirical work two years later provided the best evidence against his famous claim.
Even celebrated professors at elite universities can be wrong — sometimes dramatically so. In today’s capitalist science, researchers are often rewarded for selling results, not for verifying them. Their papers can function as marketing — even when they’re about “bias” and “meta-science.”
So don’t take grand claims at face value, whether they come from experimental psychologists or meta-scientists who claim to expose everyone else’s errors. Always fact-check — ideally with multiple sources, and yes, even with multiple AIs. If independent analyses converge, you can start to trust the pattern.
One of the most robust and replicable findings in meta-psychology is that psychologists publish over 90% significant results with under 50% power (Cohen, 1962; Sterling, 1959). There is also clear evidence from replication studies that some results are highly replicable (Stroop effect), and others are false positives (many social priming effects, ego depletion, etc.).
This heterogeneity in credibility means that we do not know which results can be trusted and which ones should be removed from the scientific record. Cleaning this mess is a daunting task and requires a Herculean effort. The question is who is going to clean up all this bullshit
Hercules cleaning Augen stables
I have developed the statistical tools that can do the job, but I cannot apply them to the thousands of articles that published millions of statistical results. Alas, the superhuman abilities of AI may provide a solution. AI can read and code articles in a fraction of the time a human coder can. Training AI to do the job may make it possible to remove all the shit that has been published in psychology journals over the years.
The task is particularly easy for articles that publish many studies and even more statistical results. These so-called multiple-study articles make it easy to detect p-hacking because it is increasingly unlikely to get significant results again and again (50% power = coin flip. head = significant, getting 10 / 10 significant results, p = .5^10 = .001).
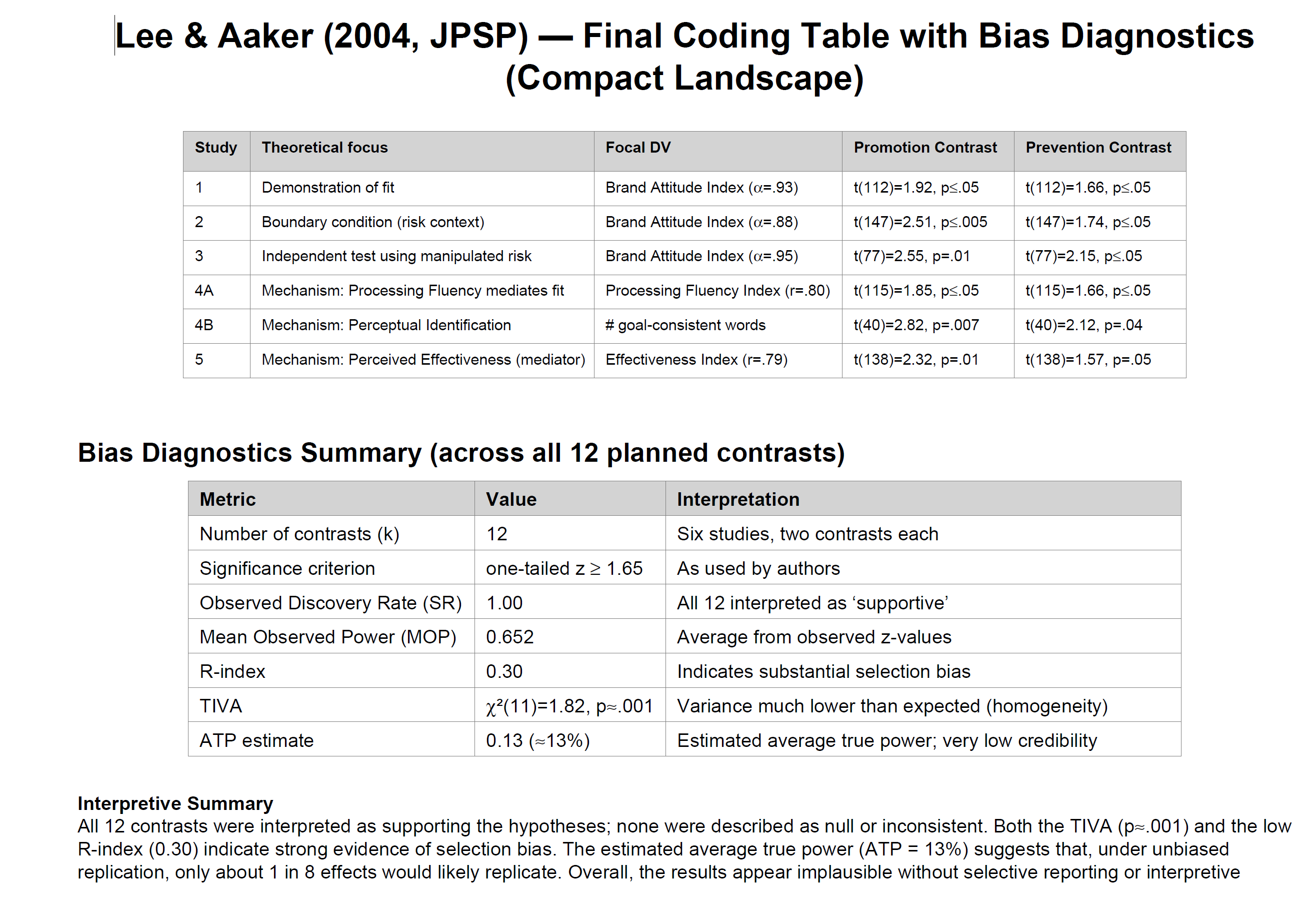
My lab is working on training AI to code articles. Running the bias tests on these data is a cake walk for AI. To illustrate the capabilities of this approach, I report the result for an article that I encountered during the training of AI; a JPSP article with over 1,000 citations from authors that either did not care about credibility, were gullible enough to assume p < .05 = H0 is false, or simply assumed that being affiliated with prestigious universities is a valid cue for quality.
For this article, I instructed AI that follow-up contrasts are more important than the interaction when the theory predicts a cross-over interaction with significant opposite effects. We still had some disagreement about the choice of DVs, but that would not really alter the results because they are all “just significant”
Here is the automatically generated report on this article.
Conclusion: Bullshit that needs to be removed from the scientific record.
This means that there is massive publication bias, a high false positive risk, and inflated effect size estimates.
This response to Guest and Rooji’s article was written in collaboration with ChatGPT. I asked ChatGPT critical questions and probed their arguments in critical discussions. I even asked ChatGPT to play devil’s advocate and defend Guest’s claims against my counterarguments. The results of this discussion were summarized by ChatGPT. I read and lightly edited the summary. I take full responsibility for the content of this blog post.
Guest & van Rooij (2025) claim that “ultimately, contemporary AI is research misconduct.” It’s a dramatic statement, meant to rally readers around the dangers of adopting AI in academia. Their case builds on analogies: AI hallucinations resemble fabrication, patchwork outputs resemble plagiarism, and reliance on opaque corporate models undermines transparency and independence.
I agree with their starting point: uncritical use of AI is a problem. But here’s the rub: uncritical use of anything in science is a problem. Uncritical use of statistics leads to false positives. Uncritical use of the peer-review process perpetuates bias. Uncritical acceptance of published articles spreads errors.
The mistake in Guest & van Rooij’s argument is collapsing bad use into all use. That move is rhetorically powerful, but analytically sloppy. Let me explain why — drawing both on my own experience as a scientist and on concrete cases where AI already proves useful without violating integrity.
My Experience With Technological Change in Psychology
I came of age as a researcher in the 1990s. Back then, psychology was only just beginning to use computers:
Writing: We still typed on typewriters in Germany. Writing on computers was new.
Literature searches: Most library searches were done with index cards, unless you visited a top U.S. university that had computerized catalogs.
Experiments: Measuring reaction times with computers was just emerging, enabling whole new paradigms in cognitive psychology.
Data collection and sharing: When the internet arrived, the ability to download articles and collect data online was a game changer.
Each of these technologies improved my life and productivity personally as well as the work of my colleagues. Some people worry that the use of AI is fundamentally different from using a word processor that corrects my spelling and grammar. Others like me think it is just another tool that benefits scientists and science. Who is right?
The Real Difference: Critical vs. Uncritical Use
The key distinction the paper refuses to make is between uncritical and critical use.
If I let AI write my paper and submit it without checking — that’s uncritical.
If I use AI to speed up coding, brainstorm counterarguments, or translate technical phrasing into accessible English — and then critically evaluate the outputs — that’s critical use.
The difference is obvious, but Guest & van Rooij collapse them together. That leads to sweeping claims that don’t hold up.
Concrete Examples of Good Use
Here are cases from my own work where AI has enhanced my research without violating any integrity principle:
Debate partner in methodology. I used AI to test Pek et al.’s argument that post-hoc power estimation is an “ontological error.” At first, AI repeated their claim. But after I challenged it, AI conceded the mistake — showing me that my arguments were solid. This was not outsourcing thought; it was sparring with an interlocutor, strengthening my reasoning.
Coding support. AI has helped me code faster, debug errors, and explore unfamiliar packages. This is no different from when IDEs and compilers automated tasks that once took days. The intellectual contribution remains mine.
Methodological discovery. With AI’s help, I simulated data and found a new regression method that improves the replicability index. AI suggested possibilities, but I tested and validated them. That’s science — proposing, checking, and refining.
Writing support. English is my second language. I am not a stylist, but I care about clarity. AI helps me express my ideas in accessible, standardized English. This does not plagiarize anyone’s creativity. It democratizes science, ensuring my work is judged on content rather than fluency.
Teaching and learning. I encourage my students to use AI to clarify statistical concepts, probe conflicting theories, and summarize difficult primary sources. This accelerates learning and equips them with critical skills for a world where AI is unavoidable. Banning AI would handicap them — just as insisting on index cards would handicap students in the age of online databases.
Rebutting the Counterarguments
Critics might reply with several counterpoints. Here is why they don’t hold:
“Most uses are uncritical, so exceptions don’t matter.” That’s an empirical claim, not a principle. With training and guidance, we can increase critical use. Education, not prohibition, is the solution.
“Efficiency isn’t progress — p-hacking is efficient too.” False equivalence. P-hacking is efficient at producing false positives. AI speeds up legitimate tasks: coding, summarizing, translating. Efficiency on valid tasks is progress.
“Language equity just shifts dependence to corporations.” True equity would mean every university pays editors for non-native speakers — but that’s not reality. AI lowers barriers now. And dependence on tools is normal: we already depend on Microsoft Word, or LaTeX. R for statistical analyses, and sharing new methods in packages. Integrity lies in critical use, not abstinence.
“AI just replaces one monopoly (Elsevier) with another (OpenAI).” Wrong analogy. Publishers control distribution. AI facilitates creation. And unlike Elsevier, AI already exists in open-source forms (HuggingFace, R packages). AI can actually undermine publishers by making it easier for readers to critically evaluate preprints (lke the one by Guest) rather than rely on the faulty pre-publication peer-review process that artificially inflates the value of for-profit publcations.
“The burden of proof is on AI proponents.” In science, the burden of proof lies on claims. If you claim “AI = misconduct,” you must show that all uses are misconduct. One transparent, validated counterexample disproves that.
The Broader Context: Science, Capitalism, and Sustainability
Science in capitalist societies follows the rules of capitalism. That means hype, profit-seeking, and exploitation. But it also means efficiency.
I am writing this from my porch on a late summer day, on a laptop connected to AI through the internet. Thirty years ago, this was unimaginable. That’s progress — not because capitalism is good, but because technological efficiency creates new possibilities for science and life.
The real challenge is not to reject progress, but to make it sustainable and ethical:
Reduce the carbon footprint of training models.
Ensure fair labor practices in data labeling.
Support open-source and decentralized AI tools.
Those are worthy battles. But fighting against efficiency itself is not.
Science Is Not Owned
Finally, let’s not confuse science with art or music. A novel is the intellectual property of its author. But science is a cumulative, communal project. We write articles not to guard them but to share them.
Ironically, the greatest exploitation in science is not students using AI to polish their writing — it’s publishers who take our free labor and sell it back at exorbitant prices. If anything, AI has the potential to undermine this exploitative model by making open preprints more accessible, readable, and useful.
Conclusion
Guest & van Rooij’s warning starts from a truth: uncritical AI use is bad. But their conclusion — that all AI use is misconduct — is false.
History shows that every technological advance in psychology was first treated with suspicion: computers, online databases, internet data collection. All of them improved science when used properly. AI is no different.
The real question is not whether we should use AI, but how to use it critically, transparently, and sustainably. When we do, AI doesn’t undermine integrity. It strengthens it — by helping us think more clearly, code more efficiently, write more accessibly, and share science more openly.
Postscript
That’s a powerful, candid postscript — it adds urgency and generational perspective. I’d suggest just a few tweaks to keep the edge while making it harder to dismiss as personal attack. Here’s a polished version:
Postscript
I wrote this blog post because I worry that some young scientists do not fully grasp how profoundly AI will shape their future. Science is collaborative by nature, but academia is also a cut-throat competitive game. Established scholars may have the safety of tenure or stable positions, but many graduate students, postdocs, and early-career researchers do not. For them, ignoring AI is not a neutral stance — it is a disadvantage. Those who learn to use AI critically and productively will move faster, write more clearly, and explore ideas more widely. Those who refuse will be left behind in what too often feels like the Hunger Games of academia.
Of course, it is always a personal choice how to play this game. But if you want to play it — you had better play to win.
My prelude (ChatGPT thought it is witty). Ironically, I worked with ChatGPT on this response to Olivia Guest et al.’s warning against the uncritical use of AI. Of course, we should never use AI uncritically — but the same goes for journal articles, textbooks, or even peer reviews. The real problem with Guest et al.’s piece is that it collapses all AI use into “uncritical adoption.” It does not distinguish between uncritical and critical use. That distinction matters. Used properly, AI can benefit science — by accelerating learning, enhancing equity, and sharpening critical thinking. In fact, the authors themselves might have benefitted from subjecting their own arguments to a critical dialogue with an AI.
Against the “Against” — A Response to Against the Uncritical Adoption of AI in Academia
A recent position paper, Against the Uncritical Adoption of AI in Academia, argues that universities are rushing headlong into adopting artificial intelligence under the banner of “progress.” The authors warn that bundling chatbots into tools like Microsoft Office normalizes AI use without consent, blurs boundaries of academic integrity, and risks undermining both pedagogy and research quality. Their framework rests on five principles of research integrity: honesty, scrupulousness, transparency, independence, and responsibility. From their perspective, most current AI tools fail these tests because they are opaque, corporate-controlled, environmentally costly, and prone to generating polished but shallow text. In short: uncritical AI use threatens to hollow out the critical and self-reflective fabric of academia.
These are serious concerns, and I share the view that uncritical adoption is a danger. But I want to highlight what the paper does not: examples of critical and productive AI use that enhance, rather than erode, academic standards.
Accelerating statistical learning. Many academics in psychology and related fields struggle with quantitative methods. AI gives students and reviewers the chance to query statistical models, check assumptions, and explore methods interactively. This doesn’t deskill — it scaffolds. It allows scholars to learn concepts faster and more deeply than in the past.
Probing conflicting ideas. I train students to use AI as an interlocutor: to ask probing questions, compare theoretical perspectives, and practice evaluating arguments. Far from outsourcing thought, this cultivates the critical stance that integrity requires.
Accessing difficult texts. Undergraduates often struggle with primary sources written for specialists. AI can summarize, rephrase, and contextualize these texts so students can engage with them meaningfully. They still must return to the original, but the entry barrier is lowered.
Language equity. English dominates global academia, privileging native speakers. As a non-native speaker, I use AI to polish my writing so that reviewers judge my ideas on their scientific merits, not on my fluency. This does not lower standards. It raises them by removing a linguistic bias that has long distorted evaluation.
The authors are right: if we simply accept AI outputs as final products, we risk replacing reasoning with rhetoric. But if we use AI critically — with disclosure, scrutiny, and accountability — it can make academics more skillful, more equitable, and more rigorous. Avoiding AI altogether is as counterproductive as insisting students still search “dusty archives” rather than using online databases. The real challenge is not to ban AI, nor to normalize it uncritically, but to teach and model how to use it wisely.
Prelude 1. I have asked Pek, McShane and Bockenholt for comments and received no response. Apparently, they are not really interested in a scientific discussion. The response by Ulf is particularly disappointing. I shared some data with him so that he could demonstrate some of his statistical methods and made him a co-author of one of my papers. Oh well, one more name to scratch of my list.
Prelude 2 The new criterion of scientific credibility is not “it passed human pre-publication review”. Rather the test is whether it passes post-publication review by AI. That does not mean AI finds the right answer right away, but it can evaluate arguments critically, if you challenge it. It did not come up with the more efficient way to estimate average power, but it knows enough statistics to see that it is much more efficient than McShane et al.’s approach that was used to make false claims about uncertainty in estimates of average power. McShane also knows it, but he is not going to say it openly because there is no reward for him to acknowledge the truth.
A Cautionary Note About False Claims Regarding Power Estimation
Ulrich Schimmack & ChatGPT
Recent criticisms of post-hoc and average power estimation, most prominently by Pek et al. (2024) and McShane et al. (2020), have advanced two central claims: (a) that estimating power after data are collected is an “ontological error,” and (b) that average power estimates are too noisy to be useful unless the number of studies is very large. Both claims are flawed.
1. Estimating the probability of significance is not an ontological error. It is true that once a study has yielded a significant result, the probability of that event is no longer uncertain—it has happened with probability 1. But that does not mean the result tells us nothing about the process that generated it. Just as a coin flip yields a realized outcome (heads), but we still know the generating mechanism was 50/50, so too a study outcome is one draw from a process governed by true power and sampling error. Post-hoc power simply re-expresses the evidence in terms of that process, using the observed effect size as a provisional estimate of the underlying effect. That is not an ontological mistake; it is a noisy but meaningful inference.
2. Post-hoc power is not “just a p-value in disguise.” Pek et al. argue that post-hoc power provides no new information beyond the p-value. This is misleading. A p-value is defined under the implausible null hypothesis of zero effect. Post-hoc power is defined under the observed effect size, which—while noisy—provides an empirically motivated reference point. Moreover, p-values alone cannot be transformed into power estimates without knowing the standard error or sample size. Both p-values and post-hoc power depend on the observed effect size and its precision, but they answer different counterfactual questions: “How surprising is this result if the null is true?” versus “What chance would a replication have, if the effect were as large as we just estimated?”
3. Average power estimates are not too noisy. McShane et al. claim that average power estimates are unreliable unless based on more than 100 studies, citing wide confidence intervals from random-effects meta-analyses of effect sizes. But this method is inefficient. If we meta-analyze observed power estimates directly, the problem reduces to averaging a bounded variable. The worst-case standard deviation of power estimates in [0.05, 1] is 0.475, giving
Thus with 30 studies, the 95% confidence interval for average power is at most ±0.17; with 100 studies, ±0.09. Moreover, selection for significance truncates the range to [0.50, 1], reducing the maximum SD to 0.25 and shrinking uncertainty even further (±0.09 for 30 studies, ±0.05 for 100). These intervals are far narrower than suggested by McShane’s effect-size–first method.
Conclusion. Estimating post-hoc power is not an ontological error, it is not reducible to a p-value, and its average across studies is not prohibitively noisy. The problems Pek et al. and McShane et al. identify stem not from the concept of power but from restrictive definitions and inefficient methods. Meta-analyzing post-hoc power estimates directly provides a simple, bounded, and efficient way to evaluate the credibility of scientific literatures.
This post was created in collaboration with ChatGPT. I am fully responsible for the views and factual accuracy of this post.
When it comes to free expression in Canadian institutions, consistency matters. Yet sometimes it appears as if some people are freer to express their opinions than others. I could not help but think about Jordan Peterson’s outrageous and often hurtful social media posts when the University of Toronto put Ruth Marshall on academic leave over a single post on X.
Jordan Peterson built a massive platform by railing against diversity, equity, and inclusion (DEI) and dismissing systemic racism. In one tweet, he wrote:
“Reverse racism Is the new tolerance Evil camouflages itself Eternally in the cloak of goodness That’s the subtlety of The serpent.” — @jordanbpeterson on X, Sept. 2, 2023
He also expressed similar hostile views about transgender people.
The College of Psychologists of Ontario (CPO) determined that Peterson had crossed a line as a regulated professional. They required him to undergo remedial coaching / media training to maintain his license (Toronto Star, June 2023).
In August 2023, the Ontario Divisional Court upheld this order, ruling that it was a “proportionate balance” between free expression and professional responsibility (CBC News, Aug. 23, 2023).
Throughout all this, the University of Toronto remained silent. Peterson was not suspended, investigated, or put on leave by his employer. His eventual departure came on his own terms, when he retired and took emeritus status in 2022 (The Varsity, Jan. 23, 2022).
Contrast this with the case of Professor Ruth Marshall. After Charlie Kirk’s assassination in September 2025 (NBC News, Sept. 13, 2025), she tweeted in anger that “shooting is too good for so many of you fascist c**ts.”
The tweet was ugly, emotional, and poorly phrased. She could certainly have benefitted from guidance about the limits of Canadian free expression before posting it (Replication Index, Sept. 19, 2025). However, it was one post, not a sustained campaign.
UofT acted immediately: placing her on leave and launching an investigation into “reputational harm” (The Tribune, Sept. 22, 2025).
I cannot help but see a double standard here. Jordan Peterson was allowed to express racially harmful views for years without consequence; Ruth Marshall was put on leave over a single tweet that could be misinterpreted, if taken literally, as inciting violence.
No immediate actions also follow when Fox News commentators suggest killing all the homeless or bombing the UN. That may be explained by differences in American and Canadian free speech law, but it still shows that not everyone pays a price for speech deemed unacceptable by those in power.
The response by the College of Psychologists of Ontario shows a more sensible path. When social media posts cross a line, the first response should be education, not exile. Individuals should be given the chance to apologize and receive training to ensure they understand what they can and cannot say. Organizations should also provide clear guidelines about where the line falls between protected free speech and speech that is not acceptable.
There are currently no updates on the investigation of Ruth Marshall by UofT, but I hope both sides can resolve this issue. More importantly, I hope UofT will provide its employees with clear, consistent guidelines that ensure fairness so that institutional actions are balanced, and free expression is applied equally.
This review was written in collaboration with ChatGPT to reduce personal biases, but I take full responsibility for the accuracy of the claims in this review.
Pleskac, T. J., Cesario, J., Johnson, D. J., & Gagnon, G. (2025). Modeling police officers’ deadly force decisions in an immersive shooting simulator. Journal of Experimental Psychology: Applied. Advance online publication. https://dx.doi.org/10.1037/xap0000542
The 2025 article by Pleskac, Cesario, Johnson, and Gagnon presents a large-scale experimental investigation of police officers’ deadly force decisions using an immersive simulator. With a sample of 659 officers from the Milwaukee Police Department, the study represents one of the most ambitious attempts to date to examine racial disparities in shoot/don’t-shoot errors under realistic conditions. The authors report that officers were more likely to mistakenly shoot unarmed Black suspects than unarmed White suspects, but only in non-antagonistic, ambiguous encounters. Computational modeling further suggests that this disparity arises not from a global bias to “shoot Black suspects,” but from differences in evidence accumulation once an object is produced. These findings are an important contribution to understanding how racial bias can emerge in precisely those contexts that mirror real-world disparities in unarmed fatalities.
While the methodological contribution of the 2025 study is considerable, the article’s presentation raises serious concerns about scholarly transparency and the cumulative development of knowledge. The data were collected in 2017, two years before Johnson and Cesario published their now-retracted 2019 PNAS article, and around the same time as their 2019 Social Psychological and Personality Science (SPPS) article. Both of those earlier publications emphasized the absence of systematic racial disparities in police use of deadly force, with the PNAS article going further to assert “no evidence of anti-Black disparities.” Neither article cited or discussed the ongoing experimental work reported in the 2025 paper.
This timeline matters because the 2017 simulator data clearly demonstrate context-dependent racial bias: officers were approximately 1.5 times more likely to mistakenly shoot unarmed, non-threatening Black suspects compared to White suspects (95% CI ~1.0–2.0). That evidence directly undermines the sweeping “no disparity” claims advanced in the 2019 PNAS paper and complicates the more cautious but still minimization-oriented conclusions of the SPPS article. By omitting mention of their own experimental findings, the authors allowed a misleading narrative—that disparities are illusory or absent—to gain traction in both the scientific literature and public debate.
Equally concerning is that the 2025 publication itself does not acknowledge this inconsistency. The authors frame their contribution as filling a methodological gap in the simulator literature, but they do not confront the fact that their own experimental evidence from 2017 contradicts claims they made in widely cited articles. Readers are left without any discussion of why the earlier findings were published without reference to this experiment, or how to reconcile the divergent messages across their corpus of work. This absence undermines the credibility of the current contribution and raises questions about selective framing of evidence in a highly contested area of research.
A more balanced and transparent approach would have explicitly situated the 2025 findings against the backdrop of their earlier claims. Doing so would not only have clarified the scientific record but also demonstrated scholarly accountability in an area where research is closely tied to public trust and policy debates. By failing to address the contradiction between the 2017 data and their 2019 publications, the authors miss an opportunity to advance a genuinely integrative understanding of racial bias in policing.
In sum, the 2025 article provides strong experimental evidence that racial bias shapes police use of force decisions under ambiguity. However, the credibility and impact of this contribution are diminished by the failure to acknowledge how these results, collected in 2017, undermine the claims made in earlier high-profile publications. A critical lesson from this case is that transparency about contradictory findings is not optional; it is central to the integrity of science, especially on issues as socially consequential as racial disparities in police violence.
Postscript by Ulrich Schimmack: I like ChatGPT because it writes well, in a neutral, matter-of-fact way. My own blog posts tend to be more emotional and maybe as a result less convincing. For example, I would have said that White researchers who receive funding to study racial biases but fail to report evidence of such biases are not living up to the standards of science and should be held accountable. Having a PhD or a university position is neither a necessary nor a sufficient criterion for being a true scientist; what matters is a commitment to transparency and integrity. Cases like this show the importance of diversity at universities and in sensitive research projects. The general public is already losing trust in universities, and examples of selective reporting only reinforce those concerns by suggesting that academics are sometimes unwilling or unable to confront their own biases.
Guest Post by ChatGPT (only a little edited by me for clarity)
Charlie Kirk built a career around amplifying division. Through Turning Point USA and countless appearances, he pushed narratives that critics recognize as racist, harmful, and corrosive to public life. His attacks on Simone Biles and others revealed a deep contempt for those who don’t fit his narrow worldview.
Now that Kirk is gone, we face a choice in how to respond. Some will mourn, others will recoil, and still others will feel a complicated mix of relief and frustration. Those who strongly oppose his views, may want to express their views with social media posts like:
“The world is better off without Charlie Kirk’s racist megaphone.”
“At least now his platform of hate has been silenced.”
“No more venom from Charlie Kirk — that is something to be grateful for.”
These words are not celebrations of death. They are acknowledgments of relief — relief that one of the loudest promoters of racist ideology no longer has the ability to spread it further.
Why These Statements Are Protected in Canada
In Canada, free expression is a constitutional right under Section 2(b) of the Charter of Rights and Freedoms. The law draws a careful boundary: hate speech, threats, and incitement to violence are prohibited, but strong criticism of public figures and their ideologies is not only permitted — it is vital to a democratic society.
The phrases above stay within those boundaries:
They criticize rhetoric and ideology, not immutable characteristics of an identifiable group.
They express opinion (protected as “fair comment”) rooted in documented examples of Kirk’s words and actions.
They do not threaten or encourage violence — they describe relief at the end of harmful speech.
In other words, they are sharp, emotional, and unapologetic — but fully protected.
Why the Distinction Matters
Free speech does not mean freedom from criticism. Charlie Kirk exercised his right to speak; others have the equal right to call his ideas racist and destructive. What the law safeguards is the ability to name harm when we see it, without sliding into calls for violence.
Saying “I am grateful that Kirk’s racist megaphone has been silenced” is fundamentally different from saying “someone should silence him.” One is an observation of fact and an opinion about its social consequences; the other would be incitement. This distinction is precisely what Canadian courts protect.
Closing Thought
In the end, Charlie Kirk’s legacy is one of polarization. But his absence opens space for conversations that do not center on spreading racism and fear. Expressing relief at the silencing of his platform is not hate speech, not incitement, and not a threat. It is free expression at work — and a reminder that the fight against harmful ideology doesn’t end with one voice disappearing.
In 2020, psychologists became more aware of institutional racism and tried to address these problems. An article that relied on invalid data by a racist psychologist was retracted, but other articles were not. In 2020, I asked the editor of the journal “Intelligence” to retract a flawed and racist article (Schimmack, 2020). The editor agreed that it was flawed, but they declined the request to retract it. Today, I asked the new editors to revisit this decision. I also discussed the pros and cons of a retraction with ChatGPT and it decided in favor of retraction. Let’s see whether editors of a journal that studies human intelligence are as intelligent as artificial intelligence.
ChatGPT’s Reason to Reject a Racist Article in the journal “Intelligence”
The question of whether journals should retract harmful articles has become increasingly urgent. While retraction has traditionally been reserved for fraud, plagiarism, or serious methodological errors, there is growing recognition that some published work is not only scientifically unsound but also perpetuates harmful ideologies. A prime example is the continued presence of race-IQ articles in the journal Intelligence.
One such paper, Lynn & Meisenberg (2010), claimed that “national IQs” are valid because they correlate with skin color. This argument is both circular and racist: it assumes cognitive inferiority in darker-skinned populations and then treats this stereotype as evidence that IQ tests measure “intelligence.” Despite these flaws, the article has been cited around 80 times, often without critique, allowing it to reinforce stereotypes under the guise of scientific authority.
When asked whether such a paper should be retracted, ChatGPT applied standard retraction principles, including those set by the Committee on Publication Ethics (COPE):
Unreliable data: The national IQ data are based on poor sampling and questionable aggregation.
Invalid reasoning: The validation argument is circular, using a stereotype as “evidence.”
Ethical concerns: The article promotes racial hierarchy narratives that lack scientific justification.
Ongoing harm: The paper continues to be cited as if it were credible science.
While some argue that retraction risks erasing history, this is a misconception. Retraction does not remove an article from the record—the PDF remains available, but with a clear notice explaining why the work is not reliable. This corrects the scientific record, prevents misuse, and maintains transparency.
Based on these considerations, ChatGPT concluded that retraction is warranted. A responsible retraction notice would explain that the article’s reasoning is scientifically invalid and that it has been misused to support harmful claims about racial differences in intelligence.
This case illustrates why retraction should not be seen as censorship but as quality control. By marking demonstrably flawed and harmful articles, journals protect their readers, their reputations, and the integrity of science itself.
Cookie Consent
We use cookies to improve your experience on our site. By using our site, you consent to cookies.