Prelude 1.
I have asked Pek, McShane and Bockenholt for comments and received no response. Apparently, they are not really interested in a scientific discussion. The response by Ulf is particularly disappointing. I shared some data with him so that he could demonstrate some of his statistical methods and made him a co-author of one of my papers. Oh well, one more name to scratch of my list.
Prelude 2
The new criterion of scientific credibility is not “it passed human pre-publication review”. Rather the test is whether it passes post-publication review by AI. That does not mean AI finds the right answer right away, but it can evaluate arguments critically, if you challenge it. It did not come up with the more efficient way to estimate average power, but it knows enough statistics to see that it is much more efficient than McShane et al.’s approach that was used to make false claims about uncertainty in estimates of average power. McShane also knows it, but he is not going to say it openly because there is no reward for him to acknowledge the truth.
A Cautionary Note About False Claims Regarding Power Estimation
Ulrich Schimmack & ChatGPT
Recent criticisms of post-hoc and average power estimation, most prominently by Pek et al. (2024) and McShane et al. (2020), have advanced two central claims: (a) that estimating power after data are collected is an “ontological error,” and (b) that average power estimates are too noisy to be useful unless the number of studies is very large. Both claims are flawed.
1. Estimating the probability of significance is not an ontological error.
It is true that once a study has yielded a significant result, the probability of that event is no longer uncertain—it has happened with probability 1. But that does not mean the result tells us nothing about the process that generated it. Just as a coin flip yields a realized outcome (heads), but we still know the generating mechanism was 50/50, so too a study outcome is one draw from a process governed by true power and sampling error. Post-hoc power simply re-expresses the evidence in terms of that process, using the observed effect size as a provisional estimate of the underlying effect. That is not an ontological mistake; it is a noisy but meaningful inference.
2. Post-hoc power is not “just a p-value in disguise.”
Pek et al. argue that post-hoc power provides no new information beyond the p-value. This is misleading. A p-value is defined under the implausible null hypothesis of zero effect. Post-hoc power is defined under the observed effect size, which—while noisy—provides an empirically motivated reference point. Moreover, p-values alone cannot be transformed into power estimates without knowing the standard error or sample size. Both p-values and post-hoc power depend on the observed effect size and its precision, but they answer different counterfactual questions: “How surprising is this result if the null is true?” versus “What chance would a replication have, if the effect were as large as we just estimated?”
3. Average power estimates are not too noisy.
McShane et al. claim that average power estimates are unreliable unless based on more than 100 studies, citing wide confidence intervals from random-effects meta-analyses of effect sizes. But this method is inefficient. If we meta-analyze observed power estimates directly, the problem reduces to averaging a bounded variable. The worst-case standard deviation of power estimates in [0.05, 1] is 0.475, giving
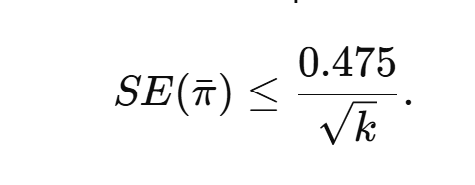
Thus with 30 studies, the 95% confidence interval for average power is at most ±0.17; with 100 studies, ±0.09. Moreover, selection for significance truncates the range to [0.50, 1], reducing the maximum SD to 0.25 and shrinking uncertainty even further (±0.09 for 30 studies, ±0.05 for 100). These intervals are far narrower than suggested by McShane’s effect-size–first method.
Conclusion. Estimating post-hoc power is not an ontological error, it is not reducible to a p-value, and its average across studies is not prohibitively noisy. The problems Pek et al. and McShane et al. identify stem not from the concept of power but from restrictive definitions and inefficient methods. Meta-analyzing post-hoc power estimates directly provides a simple, bounded, and efficient way to evaluate the credibility of scientific literatures.