psy·cho·met·rics /ˌsīkəˈmetriks/ noun
1. the science of measuring mental processes and capacities.
Nearly two decades have passed since Denny Borsboom (2006) published his “Attack of the Psychometricians”. The article made several important points about the disconnect between psychologists and psychometricians. After the psychometric revolution in the 1950s (Campbell & Fiske, 1959; Cronbach & Meehl, 1955), psychology and psychometrics separated into largely independent fields that only have the word “psycho” in common. This is unfortunate because valid empirical research requires valid measures, but many popular measures in psychological research are used without proper validation (Schimmack, 2010; 2021).
Borsboom listed several reasons for the disconnect between these two fields, such as (a) a history of operationalism in psychology, (b) the dominance of classical test theory, (c) the lack of easily accessible software to conduct psychometric analyses, and (d) insufficient mathematical training in psychology programs. Not much has changed over the past 20 years, except the availability of software programs that make it easy to conduct psychometric analysis like MPLUS (Muthen & Muthen, 2017) or the lavaan package in R (Rosseel, 2012). To encourage future generations of psychologists to validate their measures properly, an introduction to basic psychometrics is needed.
The key assumption of psychometrics is that theoretically constructs cannot be directly observed. To study these constructs empirically, it is necessary to create and test measurement models that relate observed variables that measure a construct to unobserved variables that represent variation in a theoretical construct (e.g., low vs. high self-esteem). These unobserved variables are often called latent variables.
Many psychologists are still uncomfortable with the notion of latent variables that are not directly observed. Without a hint of irony, an award-winning personality psychologist published an article that compared latent variables to the Easter bunny (Revelle, 2023). Many other personality psychologists have dismissed latent variable models with arguments that they are difficult to use, time consuming, and often do not fit the data (McCrae et al., 1996). To make latent variable models more acceptable, it is necessary to cure psychologists from their latent variable phobia.
Latent Variables
A few years before his attack, Borsboom and colleagues (2003) published an extensive philosophical discussion of latent variable models. Unfortunately, the article failed to provide a better understanding of latent variables for two reasons. First, it is highly abstract and dense without concrete examples. Second, the article first provides a reasonable interpretation of latent variables, but then claims that this interpretation does not apply to studies of personality traits. This false claim has further delayed interest in psychometrics by psychologists, especially personality psychologists. Thus, it is important to provide an accessible and correct introduction to latent variables and latent variable models for psychologists who care about the validity of their measures.
The first step towards demystification of latent variables is to question the term latent. Latent is of course just a term and the meaning of a latent variable is mathematically defined by mathematical relationships. However, without training in psychometrics, readers do not know what a latent variable is and may rely on the term latent to make sense of it. This is a problem because latent has a connotation of not being real. Borsboom et al. (2003) argue against latent variables because they invite “metaphysical speculations” (p. 217). However, latent variables are not mystical or metaphysical. They are simply variables that are not directly observed.
Few people will doubt that things can exist without being directly observed, especially if we focus on observation by humans. The Earth and life on Earth existed before it was observed by humans. Thus, it would be silly to question the existence of a construct simply because it is not directly observable to humans. To notice radioactive exposure, humans need a Geiger counter because they did not evolve a sensory system sensitive to radioactive materials. This does not mean radioactive materials do not exist or that radioactive exposure cannot be a cause of death. Many achievements in the natural sciences were made by creating measures that make it possible to quantify unobservable variables. Thus, the term unobserved variable demystifies them and makes it clear that they are nothing like Eastern Bunnies, witchcraft, or dragons.
Psychometrics literally means measurement of the mind. It emerged as a subdiscipline of psychology because psychologists needed measures of psychological processes to study them. For example, psychometrics required valid measures of hearing to study the experience of physical differences in volume. Similarly, psychologists require valid measures of experiences that are only observable to individuals by means of introspection such as thoughts and feelings. Only behaviorists can get away without valid measures of thoughts and feelings because they focus on observable behaviors. However, modern psychologists who want to study the mind need psychometrics to measure human’s psyche.
The Myth of Error Free Measurement
The main purpose of latent variable models in psychometrics is to examine measurement error. Most psychologists would agree that measurement error is a problem for empirical researchers. However, in practice most researchers conduct their studies as if measurement model is not a problem at all. This inconsistent approach to measurement error was nicely documented in Schmidt and Hunter’s (1996) article on the practice to report Cronbach’s alpha in the method section of an article and then to ignore this information in the discussion of results. For example, a personality researcher may interpret a retest correlation of r = .7 as evidence that there is considerable change in personality over time (Roberts et al., 2000). This interpretation assumes that personality was measured with perfect reliability. Latent variable models are needed to control for random measurement error (Anusic & Schiimmack, 2016).
To model measurement error, psychometric models assume that the variance in an observed variable has two parts. One part is caused by the construct of interest. The other part is caused by other processes that affect the measure independent of the actual construct of interest. This assumption is illustrated in Figure 1, using the graphic language of structural equation modeling. In this language, arrows represent cause-effect relationships with arrows pointing from causes to effects. Boxes represent observed variables where each participant in the sample has a value on the observed variable. Finally, circles or ovals represent unobserved variables. There also can be curved, double-headed arrows connecting variables, representing correlation without any assertion of cause and effect, but they are not used to relate constructs to measures of a construct.
In Figure 1, the observed variance is caused by two unobserved variables, the variation in the construct of interest and the variation in other causes that produces measurement error.

Figure 1 illustrates that observed variables are imperfect measures of the true variance in a construct (top oval) because some of the variance is caused by measurement error (bottom oval). Neither variance in the construct nor measurement error are directly observable. Thus, they are latent variables. Thus, when Revelle compared latent variables to the Easter Bunny, he basically suggested that measurement error is as unreal as the Easter Bunny (Measurement Error = Latent Variable, Latent Variable = Easter Bunny, hence Measurement Error = Easter Bunny).
Based on the questionable assumption that measurement error does not exist, personality psychologists can avoid validating observed measures with latent variable models. However, this is a highly questionable assumption. Once we add “error-free” to the name of a construct, it is easy to see that many constructs in psychology are unobservable. Even variables like age would be difficult to measure error-free, without the emphasis that our society places on this variable. In other societies, people’s age can be estimated, but their true age is often an unobservable variable. Moreover, people may lie about their age. Thus, it would be foolish to take self-reported age as an error-free measure of age, which is the reason why bars card patrons that look potentially under age.
In short, it is hardly controversial that variance in observed measures can be caused by factors that were not intended to produce variation in observed scores. This variance is called error variance. The main purpose of psychometrics, the science of psychological measurement, is to find ways to separate the true variance caused by the construct a psychologists wants to measure (e.g., attentiveness, pleasure, self-esteem, extraversion) from error variance. Thus, the purpose of psychometrics and latent variables is clear. The real problem is to separate construct and error variance in real datasets.
The Causal Status of Latent Variables
Borsboom et al.’s (2003) artcile has an extensive discussion of causality and unobserved variables that imply problems with causal interpretations of latent variables. Their main argument is that causation requires covariation and if something is stable it cannot be a cause. This is only true if there is variation in the cause. For example, few people would doubt that life on Earth is caused by the sun, but Earth and sun are single entities and we cannot study the covariation between having or not having a sun and life or no life on earth. In murder cases, we often are pretty sure who was the killer, but there is no covariation to study cause-effect relationships. Gravity is a constant, but that does not mean it cannot stop me from flying or even jumping 10 feet into the air. I may be wrong here, but I think constant causes exist. They just produce constant effects and this makes it difficult to study them. The arctic is covered in ice because temperatures are below zero. We know that this can change if temperatures rise above zero degrees, but while temperatures are constantly below zero, it will remain covered in ice.
Longitudinal studies also make it possible to test cause-effect relationships that are constant for some time, but not forever. For example, the effect of housing on housing satisfaction can show that stable differences in housing produce stable differences in housing satisfaction before and after moving, while housing satisfaction changes from before to after moving (Nakazato & Schimmack, 2010).
In sum, cause-effect relationships will produce stability while causes do not change and produce change in effects when causes change. Changes in causes are often helpful to study cause-effect relationships, which makes experimental manipulation of potential causes so useful, but cause-effect relationships exist even when causes are stable. In short, it is preposterous to argue that cause-effect relationships do not exist without observable covariations.
Borsboom et al. (2003) seems to have been led astray by philosophical treatments of causality and got lost in discussions of Einstein’s intelligence if he had been a fruit fly (p. 212). I think it is more constructive to focus on actual examples in psychological research. Take a real survey question as an example. Let’s say Shaggy is asked how often he had sex last month. No question about causality, just a frequency count. He examines his memory (shower, counter, sofa, …) and answers 15 times. According to Borsboom (2003) there can be no cause effect relationship between the actual frequency and the survey response because obviously the frequency of sex in the past month is a constant. However, it seems plausible that the cause-effect relationship is based on retrieval from episodic memory. It is also plausible that this retrieval process is not perfect. Thus, even something as objective as act frequencies that even behaviorists would accept as a valid psychological construct, is often a latent variable because measures of these act-frequencies are not error-free, unless we observe the behavior of mice in Skinner boxes.
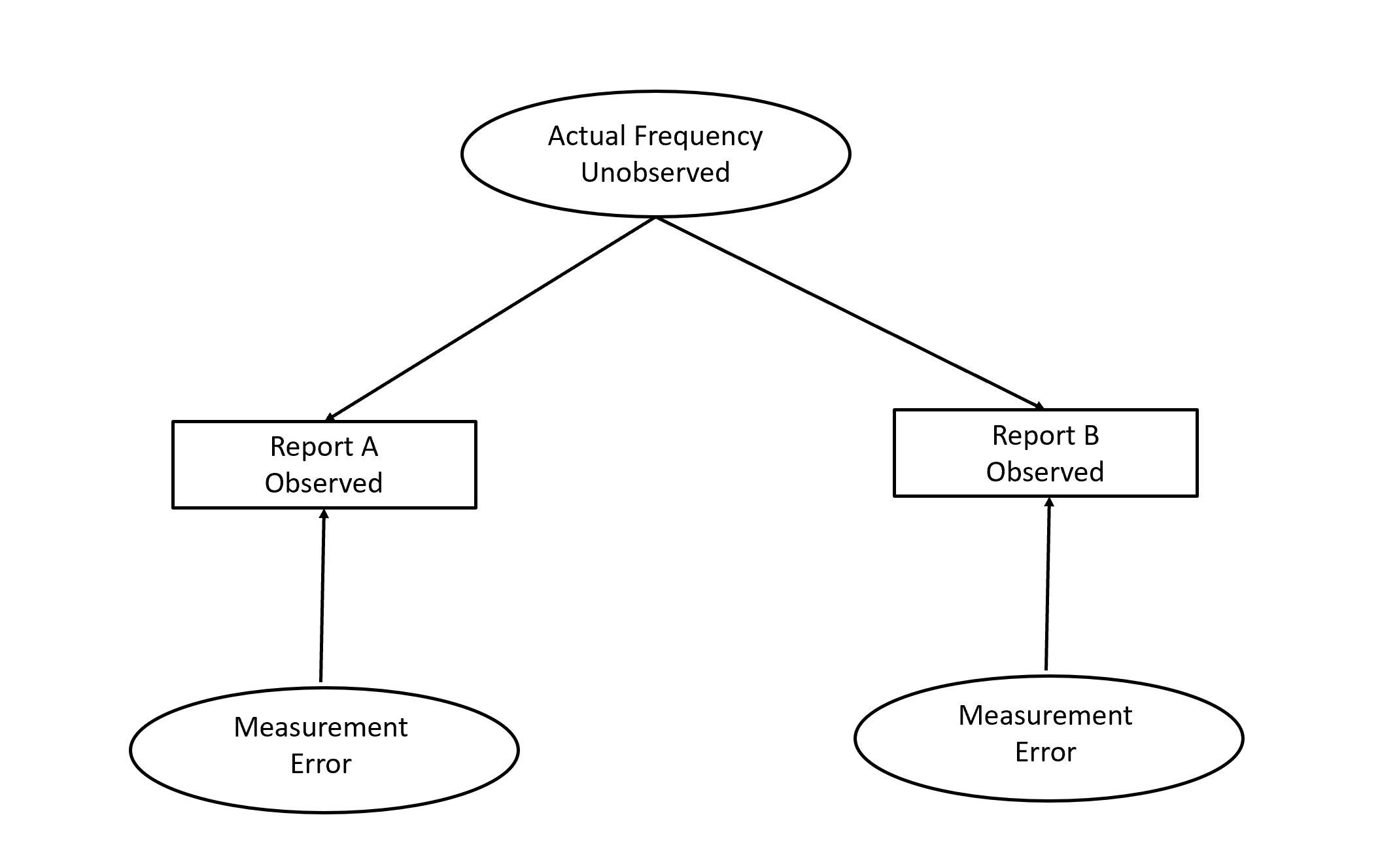
A simple way to demonstrate measurement error is to obtain act-frequency reports from two people. In relationship research, partners are often asked to report on their sexual frequency with their partner. The typical correlation between these reports is about r = .6. Evidently, the true correlation has to be r = 1 because intercourse is a dyadic variable. Thus, correlations less than 1 suggest measurement error in these reports. The reverse is not true. A correlation of r = 1 could still be produced by systematic measurement error (e.g. two unmarried religious partner might both lie and say that they did not have intercourse). However, the important point is that correlations less than 1 can only be produced by measurement error because the stable position of both partners on the unobserved variable is the same. In this example, it would be foolish to deny the existence of the true frequency as an unobserved variable and to look for direct effects of the two reports on each other to explain the correlation. Intercourse of partner A does not cause intercourse of partner B or vice versa. The correlation is produced by the unobserved third variable that represents the true frequency without measurement error. This causal model is illustrated in Figure 2. In this Figure, the correlation between the two observed variables is produced by the two effects of the unobserved third variable on each observed variable.
Confusing Construct-Measure Relationships with Construct-Construct Relationships
Another problem in Borsboom et al.’s (2003) discussion of latent variables is the confusion of two types of causality that are clearly distinguished in latent variable models. One cause-effect relationship relates theoretical constructs to observed measures of constructs. For example, variation in true levels of radiation is related to readings on a Geiger counter or variation in the true frequency of sex is related to the reported frequency of sex. These cause effect relationships are the primary focus of psychometrics.
Another type of cause-effect relationships relates constructs to each other. This is the primary focus of psychological research. For example, relationship researchers have examined the effects of frequency of sex on life-satisfaction (Muise, Schimmack, & Impett, 2016). Whether sexual frequency influences or predicts life-satisfaction is not a psychometric question. Rather, it requires that psychometric problems in the measurement of sexual frequency and life-satisfaction have been solved to study whether the error-free variables are related.
Borsboom et al. (2023) confused the relationship between measures and constructs with construct-construct relationships because they focussed on highly abstract constructs like the Big Five personality traits or general intelligence. Here the question is not whether these constructs are causes of specific behaviors or life-outcomes. The question is whether these constructs actually exist. Uncertainty about the existence of these constructs arises from the fact that they are removed from the observed measures that are used to identify these constructs. Take Extraversion as an example. In Big Five theory, extraversion is defined as a broad trait that influences several specific traits like sociability, gregariousness, excitement seeking, and a positive disposition. Even if we have valid measurement models for the specific traits, we can doubt that the relationship among the specific traits is caused by a single higher-order trait called Extraversion. However, this question is not a psychometric question because the Big Five model is a model of relationships among constructs, whereas psychometrics is limited to the causal relationship between constructs and measures. Psychometric analysis may reveal that many existing Big Five measures have poor validity, but it cannot reveal whether the Big Five exist or not. The latter is a purely substantive research question that requires knowledge about personality rather than expertise in psychometrics.

A Powerful Example of Unobserved Causes
One of the best examples of the use of unobserved variable models to study causality are latent variable models of twin data. Altough latent variable models have been used extensively by behavioural geneticists, Borsboom et al. (2003) do not mention this application of latent variable models. The most simple model is used for twins separated at birth who do not know each other. Obtaining a sample of these twins often produces correlations for measures of physical and psychological characteristics called phenotypes. Behavioral geneticists often forget to correct for measurement error in their observed variables, but we can easily specify a measurement model for a phenotype. The crucial question is why twins have similar phenotypes. For example, the correlation for height of identical twins is r = .9. Is this correlation caused by genetic or environmental factors? The answer to this question is easy for twins separated at birth. Without environmental similarity, genetic similarity has to account for the similarity in the phenotype. This causal model is shown in Figure 4. In this example, genes are unobserved, but real causes of behavior. Causal inferences rest on knowledge about genes and environments and assumptions about their contributions to variation in a phenotype. None of these theoretical assumptions have anything to do with psychometrics, but we would still need latent variables to model the effects of unmeasured causes.
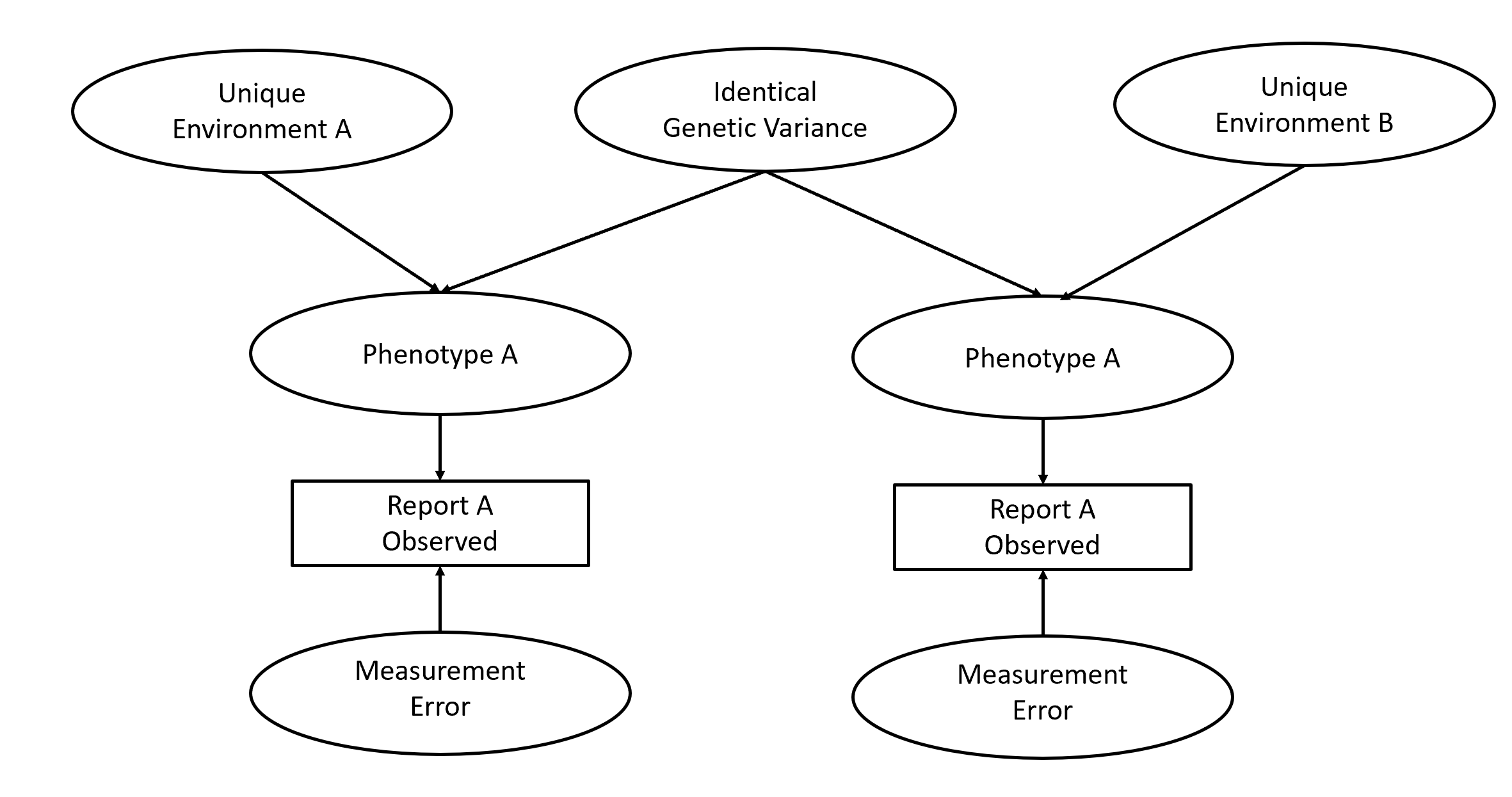
In sum, while it may be more interesting to speculate about Einstein and fruit flies, actual research examples show that latent variables are needed to model unobserved causes and that the use of latent variables for this purpose has nothing to do with psychometrics. Genetic differences are stable and can produce stable differences between people. At some point, Borsboom et al. (2003) even concede that this is the case for traits like height. There claim that it does not apply to psychological traits is based on their skepticism about specific trait theories, but not a reasonable argument against the use of latent variables to model unobserved causes of behavior.
Latent Variables Are Everywhere
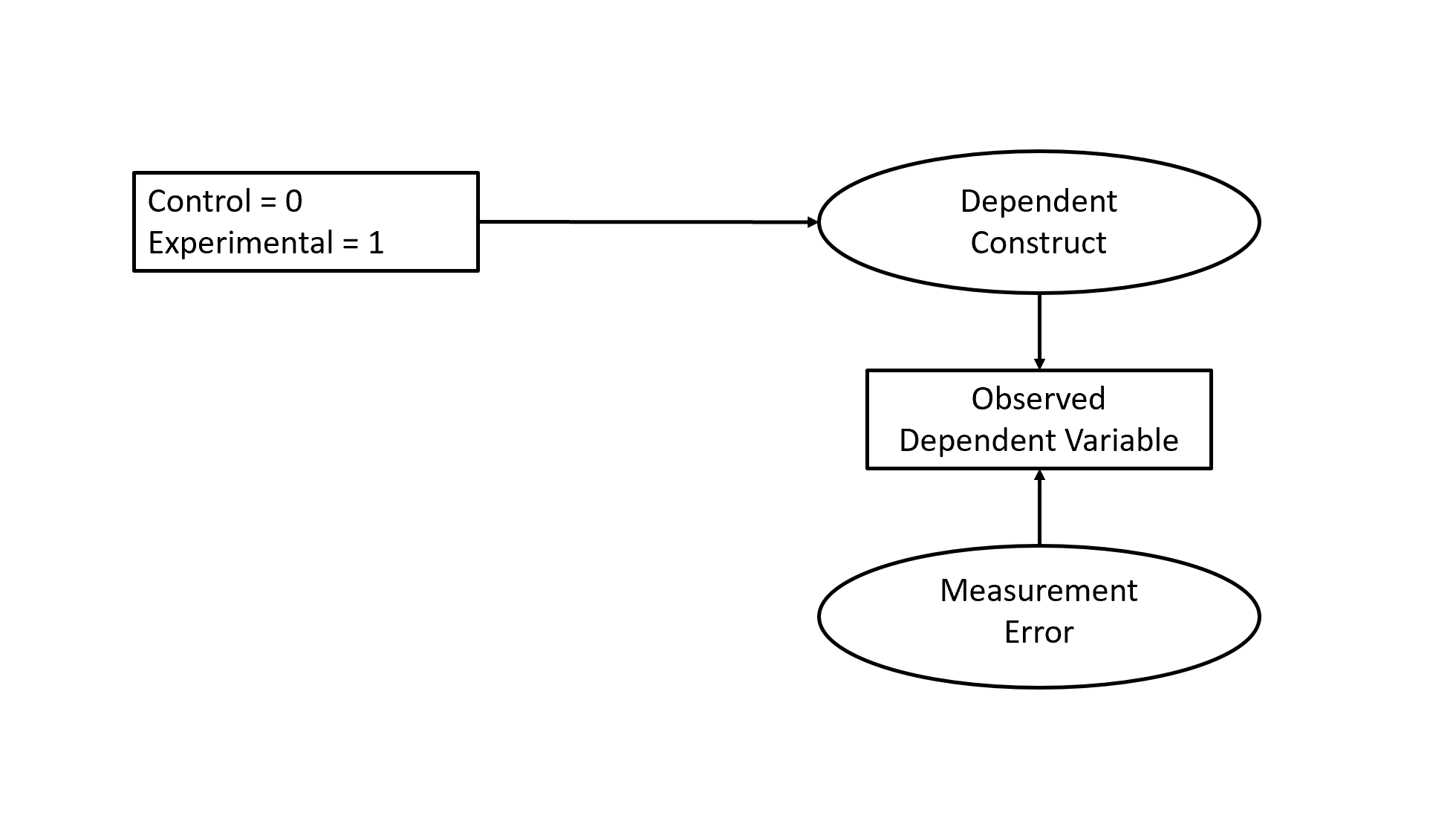
Even hard-core experimentalists have to deal with latent variables although they often present their results without discussing the influence of unobserved causes. Take a simple experiment that randomly assigns participants to an experimental condition or a control condition. After the manipulation, the dependent variable is measured. The statistical analysis shows that the means of the two groups differ, but it also shows that there is variation within each group. Researchers compute the standardized effect size and find that the mean difference equals .8 standard deviations. They report this as a strong effect based on Cohen (1988). However, an effect size of d = .8 corresponds to a correlation of r = .37, which implies that only r = .37^2 = 14% of the variance in the dependent variable is explained by the manipulation. The remaining 86% of the variance is essentially a latent variable although it is typically called residual variance. One could argue that some of this residual variance is error variance. To distinguish between variance due to unmeasured causes and measurement error, one would need a measurement model for the dependent variable. This model is also needed to obtain a proper measure of the effect size because measurement error attenuates effect size estimates in experiments with random assignment of participants.
Latent Variables Can Become Manifest
The term latent means that something is not yet visible, but may become so in the future. This is also true for latent variables. Personality psychologists are often satisfied with labelling a factor from an exploratory factor analysis. For example, the terms Openness, Agreeableness, or Conscientiousness are merely labels for latent variables observed in exploratory analyses. This practice has led to criticism that these factors do not correspond to any real causes of human behavior. A response to this criticism would be to develop direct measures of these latent variables. Research on the structure of affective traits shows how this can be done. Diener et al. (1995) examined the covariation among six basic emotions, namely happiness, love, anger, fear, sadness and self-conscious emotions (guilt, shame). They proposed that two higher-order factors explain most of the correlations among these traits. Positive Affect (PA) accounts for the covariance between happiness and love and Negative Affect (NA) accounts for the covariance among the other traits. Finally, PA and NA were moderately negatively correlated. Diener et al. (1995) simply labeled the higher order factors PA and NA, but provided no direct evidence for the hypothesis that the factors represent the valence of affective experiences. Payne and Schimmack replicated Diener et al.’s (1995) study and added valence items to the set of items. The valence items were used to create a measurement model for PA and NA. The results confirmed that the factors that account for the covariance among specific affects reflect the valence of affective experiences. Thus, variables that were latent in Diener et al.’s (1995) study became manifest variables in the replication study. This example shows the dialectic relationship between theory development and measurement in science (Cronbach & Meehl, 1955). Avoiding latent variables because there are currently no measures of these theoretical constructs impedes theory development and scientific progress.
Pseudometrics
Borsboom et al.’s (2003) lengthy discussion of latent variables ended with a disappointing conclusion.
“The realist interpretation of latent variable theory seems to lead to conclusions that we are not willing to draw. Psychology has a strong empiricist tradition, and we do not want to go beyond the observations— at least, no further than strictly necessary. As a result, there is a feeling that realism about latent variables takes us too far into metaphysical speculations” (p. 217)
This conclusion undermines the fundamental purpose of psychometrics. Psychometrics requires going beyond observations because observations are never error-free. To dismiss latent variables as a representation of error-free variables to examine measurement error in observed scores is essentially a death-nail for psychometrics. We simply assume observed scores are error free and never wonder about measurement error again. I call this approach to psychological measurement pseudometrics. Unfortunately, Borsboom has been successful in spreading fear of latent variables and pseudometrics for two decades without much push back from psychometricians or psychologists. Psychometricians just continue to use latent variable models and psychologists never bothered with measuremnet models in the first place. Thus, pseudometrics has not really changed existing practices in either fields, but it has prevented progress in measurement of psychological constructs.
One example of pseudometrics is Cramer et al.’s (2012) study of 240 personality items that were created to measure 30 simple traits and the Big Five personality traits. The theoretical model is that 8 items are measures of a single specific trait with measurement error. Averaging across these 8 items produces a sum score that is still a biased measure of a construct. On top of the 30 measurement models is a theoretical model of the correlations among the 30 specific constructs. This part of the model is not a psychometric model and not subject to psychometric criticism. Disregarding the theory underlying the 240 items, Cramer et al. simply show a two-dimensional plot of the 28,920 correlations. They then visually inspect the plot to conclude that the Big Five factors are not represented in this set of items. “This visualized pattern of correlations between personality items is not convincingly suggestive of five distinct latent traits” (p. 419). Ironically, we can cite Borsboom (2006) to make the point that eyeballing correlation matrices cannot “be considered an optimal research procedure. ” (p. 436). Indeed, this practice should be called psuedometrics.
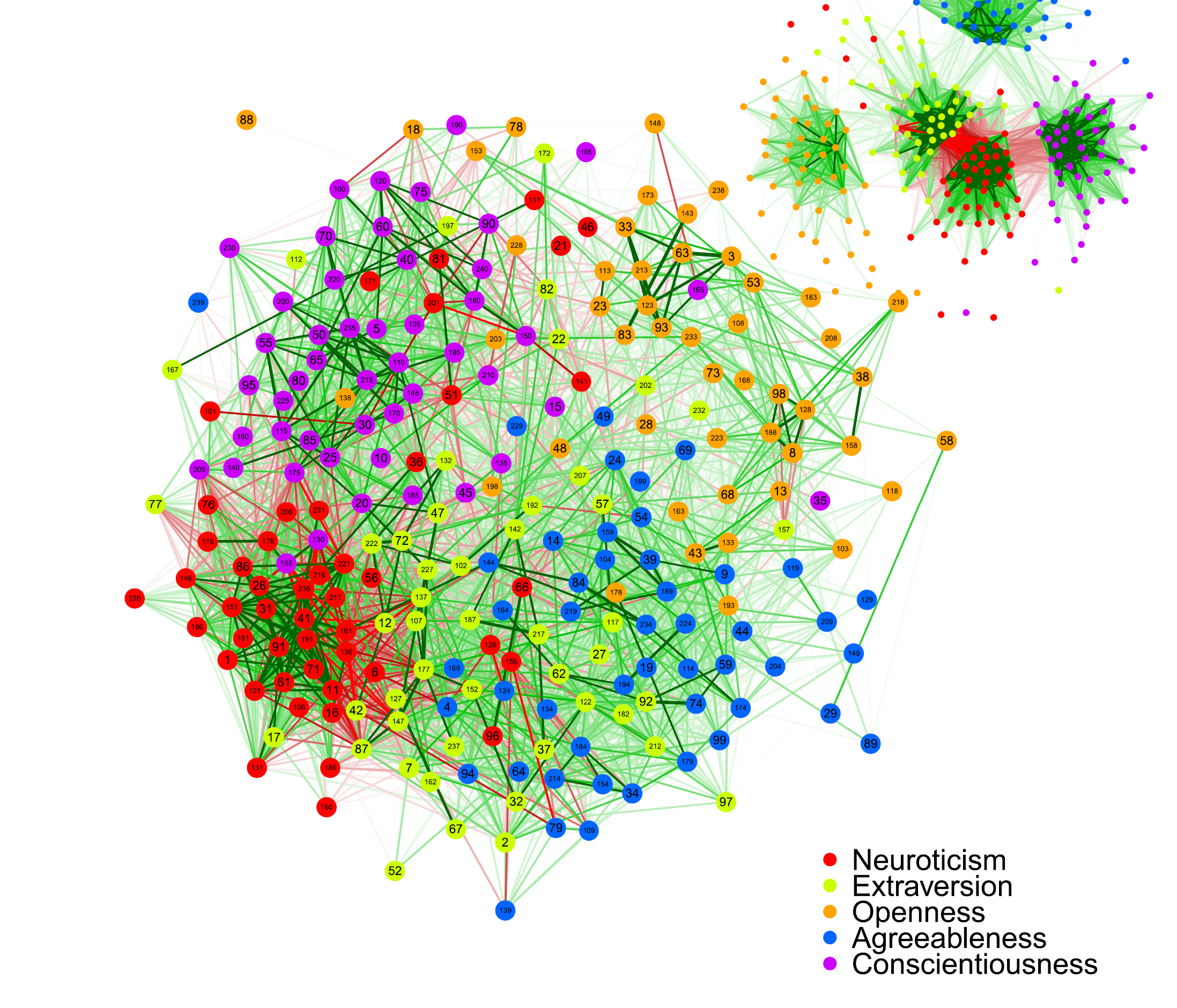
A better solution is to fit a latent variable model to the data. This model has a measurement model that relates items to specific trait factors and a structural model that relates specific factors to broad factors. Contrary to Cramer et al.’s claims, a model with five broad factors fits the data reasonably well.
Borsboom and colleagues have published many other articles that use single-items as if they are error-free measures of theoretical constructs to then present pictures of inter-item correlations. Visualizing inter-item correlations is not a crime, but it is also not psychometrics. Items are by definition researchers’ creations that are unlikely to map one to one onto actual causal factors that influence human behavior. The task of psychometricians is to examine how good observed measures are and to do so they need latent variable models. Psychometricians who do not believe in latent variable are charlatans who sidestep the actual task of a psychometrician to find valid measures of the mind. Let’s call them pseudometricians.
References
Borsboom, D. (2006). The attack of the psychometricians. Psychometrika, 71(3), 425–440.
Borsboom, D., Mellenbergh, G. J., & van Heerden, J. (2003). The theoretical status of latent variables. Psychological Review, 110(2), 203–219
Rosseel, Y.~(2012) lavaan: An R Package for Structural Equation Modeling. \emph{Journal of Statistical Software}, 48(2), 1-36. http://www.jstatsoft.org/v48/i02/.
Campbell, D. T., & Fiske, D. W. (1959). Convergent and discriminant validation by the multitrait-multimethod matrix. Psychological Bulletin, 56(2), 81–105
Cramer, A. O. J., Van der Sluis, S., Noordhof, A., Wichers, M., Geschwind, N., Aggen, S. H., Kendler, K. S., & Borsboom, D. (2012). Dimensions of normal personality as networks in search of equilibrium: You can’t like parties if you don’t like people. European Journal of Personality, 26(4), 414–431. https://doi.org/10.1002/per.1866
Cronbach, L. J., & Meehl, P. E. (1955). Construct validity in psychological tests. Psychological Bulletin, 52(4), 281–302
McCrae, R. R., Zonderman, A. B., Costa, P. T., Jr., Bond, M. H., & Paunonen, S. V. (1996). Evaluating replicability of factors in the Revised NEO Personality Inventory: Confirmatory factor analysis versus Procrustes rotation. Journal of Personality and Social Psychology, 70(3), 552–566
Muthén, L.K., & Muthén, B.O. (2017). Mplus User’s Guide. Eighth Edition. Los Angeles, CA: Muthén & Muthén.
Revelle, W. (2024). The seductive beauty of latent variable models: Or why I don’t believe in the Easter Bunny. Personality and Individual Differences, 221, 112552
Roberts, B. W., & DelVecchio, W. F. (2000). The rank-order consistency of personality traits from childhood to old age: A quantitative review of longitudinal studies. Psychological Bulletin, 126(1), 3–25
Schimmack, U. (2010). What multi-method data tell us about construct validity. European Journal of Personality, 24(3), 241–257
Schimmack, U. (2021). The Validation Crisis in Psychology. Meta-Psychology, 5, MP.2019.1645
Schmidt, F. L., & Hunter, J. E. (1996). Measurement error in psychological research: Lessons from 26 research scenarios, Psychological Methods, 1, 199–223.
Among other things, this post makes the important point that virtually nothing is measured without error. We are interested in how happy people feel, but all we have in a data set is reported happiness. We are interested in racism, but all we have is expressed racism. Even for very concrete variables like sleep time and body mass index, all we have are imperfect reflections of what we are really interested in. Truly, we are like the people in Plato’s cave, chained in place and able to look only at shadows on the wall, cast by the fire.
If you don’t buy this, then maybe you are an orthodox Skinnerian behaviourist. My hat is off to you. You were a real scientist, and you backed it up by helping to produce a technology that actually worked. However, you are dead now. Rest in peace.
So it would seem obvious that we should admit that our theoretical ideas are about constructs we cannot observe exactly, and our data are at best noisy approximations of those constructs. Not only should we embrace (and try to extend) classical test theory, but we should incorporate measurement error and latent variables into the statistical models we use. For psychologists, the most accessible version of such methods are structural equation models (sem).
It’s natural to push back. Realism is a virtue, but so is simplicity. Do we really need structural equation models? One could argue that nothing is perfect, and as the famous saying goes, “Essentially all modes are wrong, but some are useful.” (Box and Draper, 1987, p. 424). The usefulness of standard statistical methods is beyond dispute (so they say), and we are busy. Let’s carry on.
This is a fair argument. One can argue against a statistical method on the basis that it’s based on unrealistic assumptions, but the argument is a lot stronger if it can be shown that those unrealistic assumptions tend to produce conclusions that are incorrect. It turns out that in one common scenario, ignoring measurement error can have very specific and very bad consequences.
The standard linear regression model makes a subtle and usually unstated assumption that the independent variables are measured without error. This assumption is not only unrealistic from a modeling standpoint, it is disastrously harmful to statistical testing. Brunner and Austin (2009) show that when independent variables are measured with error, the ability of regression techniques to “control” for extraneous variables is imperfect. As a consequence, the probability of false significance can be much greater than the purported 0.05 level, even when all other assumptions are satisfied. Note that this problem applies to various types of regression and various forms of measurement error, but it’s only an issue for observational data. With random assignment, everything is okay. In particular, covariates that are measured with error still can explain some of the variance in the dependent variable, removing it from the error term and making the tests more sensitive. It’s all fine as long as the noisy covariate is unrelated to the experimental treatment, as it will be with random assignment.
So for correlational data, ignoring measurement error is an exercise in self-deception. Structural equation models are not as convenient as traditional methods, and they involve a blend of substantive theory, hard core stats and methodology than may take many researchers outside their comfort zones. However, they are probably the right tool for the job. Psychometricians (not pseudometricians) can be very useful here, because structural equation models basically import a psychometric model into the statistical analysis, and the measurement model is always the trickiest part. Long live psychometrics.
References
Box, G. E. P. and Draper, N. R. (1987). Empirical Model-Building and Response Surfaces. New York: Wiley.
Brunner, J. and Austin, P. C. (2009). Inflation of Type I error rate in multiple regression when independent variables are measured with error. Canadian Journal of Statistics, 37, 33-46.