Authors: Z-Curve Development Team
Note 1/5/24.
This is Draft2.0. It was revised after further consultation with Erik van Zwet about his approach. In this communication it became clear that Erik’s method can be fitted to absolute z-scores. So, the comparison of the two methods with positive and negative z-scores is no longer relevant. The use of abs(z) also produced better estimates with the original dataset, but continues to perform worse than z-curve when the set of studies includes more powerful studies than those in the Cochrane Review. It remains the case that z-curve performs as well or better than vanZwert’s new approach because it does not require unrealistic assumptions about the distribution of power in sets of studies with varying effect sizes and sample sizes (Brunner & Schimmack, 2021).
Abstract
Two recent studies that extended Jager and Leek’s (2014) analysis of p-values in medical research are reviewed. A comparison of the statistical models shows that z-curve (Schimmack & Bartos, 2013) is superior to the new method proposed by vanZwet et al. (2023). Both studies show that clinical trials have low power (~ 30%), but also low false positive rates (~14%) that can be reduced to less than 5% by setting alpha to .01. Whereas abstracts in clinical journals show clear evidence of selection bias (70% significant results), Cochrane reviews show no evidence of selection bias (~ 30% significant results). The results show that clinical trials are more credible than Ioannidis (2005) suggested. In the absence of publication bias, Cochrane reviews produce unbiased effect size estimates of population effect sizes and can be used to guide practical decisions.
Introduction
The replication crisis is a term for the assumption that empirical science is less credible than it pretends to be and that most published results may be false (Ioannidis, 2005). While there are many factors that can produce misleading evidence for scientific claims, the key factor is the use of questionable research practices that produce more statistically significant results than the power of empirical studies warrants.
A seminal study examined the replicability of social psychological experiments and found that only 25% of replication studies obtained a statistically significant result again (OSC, 2015). This low success rate undermines the credibility of original articles publshed in social psychology journals that report over 90% significant result (Schimmack, 2020).
Ioannidis (2005) famously suggested that many critical trials also inflate evidence in medicine and that at least 50% of statistically significant results are false positives. Jager and Leek (2014) provided the first empirical test of this prediction. They extracted the statistical results of clinical trials from journal abstracts and modeled the distribution of p-values with a mixture model of true and false hypotheses (false hypotheses = no effect, H0 is true). They estimated a false positive risk of 13% for results that reached significance with alpha = .05. Jager and Leek’s seminal attempt to provide empirical evidence about the credibility of evidence in medicine had relatively little impact on discussions about the replication crisis in medicine, presumably because it was harshly criticized by several prominent statisticians.
Ioannidis (2014) declared in the title of his comment that Jager and Leek’s “estimate of the science-wise false discovery rate and application to the top medical
literature is false” (p. 28). To justify this conclusion, he claimed that excluding 470 p-values (from 5792, 8%) ”markedly affects the overall FDR estimates, and totally invalidates FDR estimates comparing journals and years” (p. 32). Yet, even if all of these 470 results were false positives, it would increase the estimated FDR only from 14% to (.14*.92 + .08*1 = 21%. Ioannidis (2014) also claimed that “much of the data is either wrong or makes little sense” (p. 32). If this were true, it would imply that medical abstracts are useless. His final conclusion was that Jager and Leek’s article serves as a warning “how badly things can go when automated scripts are combined with wrong methods and unreliable data” (p. 34). However, he never produced better empirical estimates of the false discovery risk in medical trials.
Gelman and O’Rouke (2014) simple found “their claims unbelievable” (p. 19). One of their key concerns is that “there is just too much selection going on” (p. 20) to obtain reasonable estimates, even though Jager and Leek’s model took selection bias into account. Ultimately, they express skepticism about the value of modeling distributions of p-values. “To us, an empirical estimate would involve looking at some number of papers with p-values and then follow up and see if the claims were replicated,” (p. 22). This did not stop Gelman from being a co-author of a recent article that used p-values to make recommendations about the interpretation of results in clinical trials (vanZwet et al., 2023).
Goodman (2014) criticizes the use of multiple p-values from a single study because these results are not independent and it is difficult to model these data without information about the amount of dependency. Another criticism was the choice of top journals. Presumably, higher false positive rates could be found in clinical trials published in less prominent journals or when pilot studies are included. A third concern was that results reported in abstracts may be misleading because abstracts feature significant results. Goodman (2014) also demands that “any estimate of the reliability of the medical literature must incorporate, as a primary result and not just as a sensitivity analysis, some estimate of the effect of biases” (p. 26). Yet, Goodman was a co-author of a recent article that used p-values to examine evidence in clinical trials without mentioning selection bias at all (vanZwet et al., 2023).
It would take nearly another decade before researchers tried again to examine the credibility of clinical trials based on distributions of p-values in two independent studies (Schimmack & Bartos, 2023; vanZwet et al., 2023). Both articles used z-scores rather than p-values, but this is a minor technical detail because p-values can be converted into z-scores and vice versa. The advantage of z-scores is that they have more interpretable distributions (see Figures below).
Schimmack and Bartos (2023) used a model that was first developed to estimate mean power of studies that are selected for significance (Brunner & Schimmack, 2021). The model is called z-curve because it fits a mixture model to the observed distribution of z-scores. The aim of z-curve1.0 was to predict the outcome of replication studies when original studies are selected for significance. This model was applied to studies in social psychology where selection bias leads to success rates over 90% (Schimmack, 2020; Sterling, 1995). Z-curve2.0 extended z-curve to estimate mean power of all studies, including non-significant studies that are not reported (Bartos & Schimmack, 2022). An estimate of the discovery rate without selection bias makes it possible to estimate the amount of selection bias (Sterling et al., 1995). Selection bias is simply the difference between the observed discovery rate (ODR; i.e., the percentage of significant results) and the estimated discovery rate (EDR; i.e., mean power to produce significant results). Without bias, the observed discovery rate matches the estimated discovery rate because the percentage of significant results is a direct function of mean power (Brunner & Schimmack, 2021). The EDR also provides an estimate of the maximum false discovery rate (Soric, 1989). The main advantage of this approach is that it does not require a priori assumptions about the amount of false and true hypotheses that are being tested. Thus, the results do not depend on assumptions that make claims about false discovery rates speculative.
Schimmack and Bartos (2023) applied z-curve.2.0 to results extracted from abstracts in medical journals. They also compared z-curve.2.0 to Jager and Leek’s model. The key finding was that z-curve.2.0 performed better than Jager and Leek’s model in simulation studies. When the model was applied to 19,751 p-values from medical abstracts using an improved extraction method, it closely reproduced Jager and Leek’s results. The point estimate was 13% with a 95% confidence interval ranging from 8% to 21%. Thus, the results confirmed that the false positive risk in clinical trials is well below 50%. The article also produced several new ways to assess clinical trials. Most important, there was clear evidence of selection bias in abstracts of journal articles. The observed discovery rate (i.e., abstracts that reported a significant result) was 70%, the model predicted only 30% significant results. Thus, the actual discovery rate more than doubles in abstracts of published articles. Finally, z-curve estimated that the mean power of studies that produced a significant result was 65% (95%CI = 61% to 69%), which implies that about 2/3 of clinical trials with a significant results are expected to produce a significant result again in an exact replication study with the same sample size. Overall, these results suggest that selection bias makes it difficult to interpret the point-estimate of the population effect size in a single clinical trial, but that clinical trials in general produce solid empirical evidence, especially when the evidence is pooled in meta-analyses.
vanZwet et al. (2023) took a different approach. First, they created their own model of z-value distributions. Second, they relied on Cochrane reviews to obtain information about effect sizes and sampling error in clinical trials and used this information to compute z-values, z ~ ES/SE (ES = effect size, SE = sampling error). I will first discuss their model and then discuss the results based on Cochrane reviews.
vanZwet et al. do not provide evidence of the validity of their model, nor do they compare their model to previous models (Jager & Leek, 2014; Bartos & Schimmack, 2021). The main differences between their model and z-curve is that their model assumes (a) full normal distributions rather than truncated, folded normal distributions, (b) allows for standard deviations greater than zero to model variation in population parameters (i.e., differences in sample sizes and population effect sizes) and sampling error, while z-curve uses (truncated, folded standard normal distributions and only models sampling error (SD = 1), and (c) their model assumes a mean of zero, whereas z-curve allows for variation in means to model variability in population parameters. The key assumptions that distinguish vanZwet’s model from z-curve are the use of full normal distributions centered at zero. Therefore, I call it the symmetrical-full-normal model (SFN-curve).
vanZwet et al. provide no theoretical justification for their assumptions that distributions of z-values from clinical trials or other studies should fit the SFN model. In personal email communication, vanZwet justified the model by stating that they “analyzed a specific dataset in an entirely appropriate way.” (December, 2023). However, the article did not provide any information about model fit. Therefore, I conducted my own comparison of model fit by fitting the data from vanZwet et al.’s article with SFN-curve and with z-curve. While z-curve is usually fitted with absolute z-scores because the sign is irrelevant, the software allows specifying negative means of the mixture components. Using this approach makes it possible to directly compare the fit of the two models against each other in a plot of the predicted density distributions.
Figure 1 shows a histogram of the k = 23,557 z-values used by vanZwet et al. along with the density distributions estimated by kernel density (blue) z-curve (dark green line) and SFN-curve (red line). Visual inspection is sufficient to see that both models fit the data relatively well, but that z-curve fits the data better than SFN-curve.
However, the relatively good fit of the SNR-model is incidental. Figure 2 shows the histogram of a subset of studies from vanZwet et al. (2023) that compared treatments to placebo. The mean of the distribution shifts towards negative values because more studies tested outcomes where negative values imply clinical benefits of a treatment. Z-curve fits the data well, but SFN-curve does not fit the data well because it makes the unreasonable assumption that the observed data have a mode at zero.

Figure 2 makes it clear that vanZwet et al.’s new SFN-model is suboptimal. There is no reason to use their approach to fit distributions of z-scores because z-curve fits the data as well or better.
Examining Cochrane Clinical Trials with Z-Curve
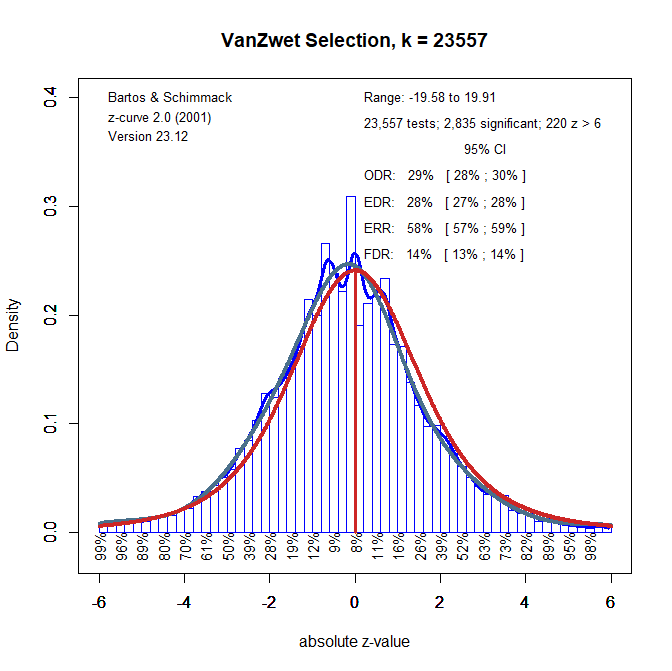
The previous analyses used positive and negative z-scores to allow for a direct comparison of z-curve and SFN-curve. However, the sign of z-scores in vanZwet’s dataset has no meaning and it is easier to use z-curve with the absolute z-scores that only show how strong the evidence against the null-hypothesis is (larger z-scores are less likely to occur when the the null-hypothesis is true). Figure 3 shows the z-curve with absolute z-values as data.

One interesting results of z-curving the Cochrane data is that the observed discovery rate (i.e., the percentage of significant results, p < .05) is practically identical to the estimated discovery rate (i.e., average power), ODR = 29%, EDR = 27%. This is a noteworthy empirical finding that vanZwet et al. (2023) fail to mention. The finding is even more remarkable because Schimmack and Bartos (2023) found evidence of publication bias in abstracts of leading medical journals. An interesting question for future research is how Cochrane reviews debias results from original articles. For now, it is important that z-curve is a simple tool that can be used to assess publication bias in sets of statistical results and that effect size estimates in Cochrane reviews are not inflated by selection for significance.
A second noteworthy finding is that the EDR in Cochrane reviews (29% including all studies used by vanZwet et al., see Figure 1) is similar to the EDR estimate based on abstracts in medical journals (30%). While this may be a coincidence, it suggests that z-curve provides reasonable estimates of the EDR even when selection bias is present. Future research should compare z-curve estimates based on the Cochrane database with matching original studies.
In his critique of Jager and Leek’s article, Goodman’s (2014) pointed out that it is more important to find the alpha level that limits the false discovery risk at a reasonably low level (say 5%) rather than estimating the false discovery risk at the traditional alpha level of .05. Schimmack & Bartos found that the false positive risk is 14%. Figure 3 replicates this finding with the Cochrane data because FDR is based on the EDR and the EDRs are the same. Thus, there is converging evidence that the percentage of false positive results is 14% or less. A simple change of alpha shows that an EDR of 30% produces a false positive risk below 5% if alpha is set to .01. Thus, to answer Goodman’s question, we are recommending alpha = .01 to maintain a reasonably low false positive risk.
vanZwet et al. (2023) do not provide estimates of the false positive risk, but they do estimate the risk of sign errors, which is closely related to the false positive risk. Sign errors depend on the magnitude of the population effect sizes, but in the limit when all effects are positive or negative, but the magnitude is close to zero, the risk of sign errors approaches the type-I error rate. In other words, the false positive risk is the worst case scenario where observed effect sizes have a different sign than the population effect size (effect size estimate is positive when population effect size is zero or negative and vice versa). Interestingly, vanZwet et al. estimate that significant results have only a 2% risk of being sign errors, which also implies a false positive risk around 2%. This is much lower than the 14% estimate obtained with z-curve.
The reason for this difference is the conservative nature of FDR estimates with z-curve. Using Soric’s approach, the false positive risk assumes that the expected discovery rate is a mixture of null-hypotheses and true hypotheses tested with 100% power. Assuming lower power, reduces the false positive risk. For example, if power is only 50%, twice as many true hypotheses need to be tested to get the same number of true positive results. As a result, fewer false hypotheses are tested and there are fewer false positives. With 50% power, the false discovery risk is only 6%, which is still higher than vanZwet et al.’s estimate of 2%. .A false discovery rate of 2% can be obtained with a scenario where researchers test 80% true hypotheses with 35% power. This scenario is strikingly different from Ioannidis’s (2005) scenarios that often assume researchers are testing more false hypotheses than true hypotheses. In short, although vanZwet et al. (2023) do not comment on Ioannidis’s famous prediction, their estimate of only 2% false positive results in Cochrane clinical trials is noteworthy and further challenges Ioannidis’s assumptions about the credibility of clinical trials.
Ignoring Heterogeneity
The main purpose of vanZwet et al.’s article was to propose to interpret results from new clinical trials in the context of the power of previous clinical trials. The main problem with this recommendation is that their database is a heterogeneous set of clinical trials that examined radically different treatments. We suggest that researchers conduct z-curve analyses of specific studies that more closely match their research topic and study designs. We recommend z-curve simply because the SFN-model makes assumptions that are typically violated in these subsets of studies (see Figure 2). To illustrate the use of z-curve for specific meta-analyses, we picked the Cochrane review #CD001886 that examined “Anti‐fibrinolytic use for minimizing perioperative allogeneic blood transfusion.” This review was chosen because the distribution of z-scores with positive and negative signs was clearly not symmetrical (90% negative, 10% positive, Median = -1.97, Mean = 2.24) and because there were many efficacy outcomes (k = 719).

Figure 4 shows the z-curve results. First, once more there is no evidence of publication bias (ODR = 51%, EDR = 50%). Second, the higher discovery rate implies a lower false positive risk. No more than 5% of statistically significant results can be false positive results. The distribution of z-scores and the implied parameters differ from those for vanZwet et al.’s (2023) data. Evidently, it would be a mistake to use vanZwet et al.’s results to interpret results in these clinical trials and the same would be true for other subsets of data. We recommend that researchers conduct their own z-curve analyses of theoretically relevant studies rather than using vanZwet et al.’s results. The key problem with these results is that the “inclusion of a trial in the Cochrane Database largely depends on whether someone happens to be interested in a particular treatment or intervention, so the database is not a random sample from the population of all trials” (vanZwet et al., 2023, p. 6).
We also believe that it is unreasonable to adjust effect size estimates based on their results. While it is true that selection on significance inflates point estimates of effect sizes, it is a fallacy to interpret point estimates of effect sizes, especially in small samples. Fortunately, medical researchers routinely report results with confidence intervals that provide information about uncertainty in these point estimates. Even conditioned on significance, confidence intervals will often include the true population effect size. Moreover, the most notable finding was that there is no evidence of selection bias in the Cochrane database. Thus, there is no selection bias that inflates effect size estimates in the Cochrane reviews. Thus, effect size estimates in meta-analyses do not need to be corrected using vanZwet et al.’s or other correction methods. Rather, these methods are more likely to lead to underestimation of treatment effects. Thus, the most useful information that is provided by z-curve analyses is the examination of publication bias in the studies at hand.
Conclusion
One decade after Jager and Leek’s seminal study of p-values in medical research, two articles built on their seminal work using two different datasets and two different methods. The following conclusions can be drawn from these new studies.
First, the z-curve method is superior and more applicable to different datasets than the SFN model that fits only one dataset by chance. As both methods have the same goal of fitting a density distribution of z-scores, we recommend z-curve as the statistical tool of choice.
The two datasets produce surprisingly similar estimates of mean power to produce significant results (i.e., the expected discovery rate). About 1/3 of clinical trials are expected to produce p-values below .05. Thus, many clinical trials have low statistical power. It is therefore important to avoid the fallacy of confusing the absence of evidence (a non-significant result with a treatment effect) with evidence for the absence of an effect.
An expected discovery rate of 30%, implies a relatively low false positive risk between 10% and 15%. Even this modest estimate is based on a worst case scenario and the actual false positive rate is likely to be much lower. Thus, it is much more likely that a statistically significant result reveals a true effect than being a false positive result. The results from the Cochrane database avoid many of the criticism raised by Ioannidis against results reported in abstracts. Thus, evidence is accumulating that his estimate of 50% or more false positives is based on unrealistic scenarios and false assumptions (Schimmack & Bartos, 2023). This is an important finding in a time of widespread science skepticism. Moreover, lowering alpha to .01 can reduce the false positive risk to less than 5%.
The biggest statistical threat to the validity of meta-analysis is selection bias. Thus, it is essential to ensure that studies are not selected for significance or to correct for selection bias when it is present. Z-curve provides a simple way to estimate not only the presence of selection bias, but also to quantify selection bias. The interesting finding is that abstracts in journal articles show large selection bias whereas Cochrane reviews show no evidence of selection bias at all. Future research needs to examine how selection bias is reduced when original studies are entered into Cochrane reviews.
Overall, the results from both studies provide converging evidence that clinical trials produce robust and credible evidence about the effectiveness of treatments that can guide medical practices. The problem of low power is mitigated by the publication of many non-significant results that help to produce unbiased effect size estimates in Cochrane reviews. As researchers who have become interested in the replication crisis in psychology, we look at these results with envy and believe that the enforcement of preregistration and the high quality of Cochrane reviews can serve as an example for psychological science that is only starting to encourage preregistration and does not have rigorous standards to evaluate biases in meta-analyses. While medical research is clearly not without problems, the overly negative image that has been created by Ioannidis’s (2005) influential article is clearly not supported by empirical data (Jager & Leek, 2014; Schimmack & Bartos, 2023; vanZwet et al., 2023).
> In this communication it became clear that Erik’s method can be fitted to absolute z-scores. So, the comparison of the two methods with positive and negative z-scores is no longer relevant.
Some background: I had to write many emails and suffer many insults before Schimmack finally understood that fitting a mixture of zero-mean normals to the signed z-statistics is EQUIVALENT to fitting a mixture of half-normals to the absolute z-statistics.
> Z-curve fits the data well, but SFN-curve does not fit the data well because it makes the unreasonable assumption that the observed data have a mode at zero.
Scratch my previous comment. Schimmack still doesn’t understand (or pretends not to understand) that I’m estimating the distribution of the absolute z-statistics.
> However, the article did not provide any information about model fit.
The estimated distribution of the (absolute) z-statistics was obtained in an earlier paper with Schwab and Senn (2021). The quality of the fit may be assessed from Figure 1 in that paper.
> First, the z-curve method is superior and more applicable to different datasets than the SFN model that fits only one dataset by chance.
The weirdest criticism: “Yes, your model fits the data, but that’s just luck so it doesn’t count.”
> As both methods have the same goal of fitting a density distribution of z-scores, we recommend z-curve as the statistical tool of choice.
Really? Who would have thought!
**Disclaimer** There are many claims in this post that I haven’t commented on. That doesn’t mean I agree with them; it only means my patience with this bs is limited.
Wow, talk about delayed response. The main problem of your method is that it only works for data like Cochrane that do not have publication bias. It is not a selection model. So, we can safely ignore it for 90% of datasets.