Social psychology has an open secret. For decades, social psychologists conducted experiments with low statistical power (i.e., even if the predicted effect is real, their study could not detect it with p < .05), but their journals were filled with significant (p < .05) results. To achieve significant results, social psychologists used so-called questionable research practices that most lay people or undergraduate students consider to be unethical. The consequences of these shady practices became apparent in the past decade when influential results could not be replicated. The famous reproducibility project estimated that only 25% of published significant results are replicable. Most undergraduate students who learn about this fact are shocked and worry about the credibility of results in their social psychology textbooks.
Today, there are two types of social psychologists. Some are actively trying to improve the credibility of social psychology by adopting open science practices such as preregistration of hypothesis, sharing open data, and publishing non-significant results rather than hiding these findings. However, other social psychologists are actively trying to deflect criticism. Unfortunately, it can be difficult for lay people, journalists, or undergraduate students to make sense of articles that make seemingly valid arguments, but only serve the purpose to protect the image of social psychology as a science.
As somebody who has followed the replication crisis in social psychology for the past decade, I can provide some helpful information. In the blog post , I want to point out that Duane T. Wegener and Leandre R. Fabrigar have made numerous false arguments against critics of social psychology, and that their latest article “Evaluating Research in Personality and Social Psychology: Considerations of Statistical Power and Concerns About False Findings” ignores the replication crisis in social psychology and the core problem of selectively publishing significant results from underpowered studies.
The key point of their article is that “statistical power should be de-emphasized in
comparison to current uses in research evaluation” (p. 1105).
To understand why this is a strange recommendation, it is important to understand that power is simply the probability of producing evidence for an effect, when an effect exists. When the criterion for evidence is a p-value below .05, it means the probability of obtaining this desired outcome. One advantage of high power is that researchers get the correct result. In contrast, a study with low power is likely to produce the wrong result called a type-II error. While the study tested a correct hypothesis, the results fail to provide sufficient support for it. As these failures can be due to many reasons (low power or the theory is wrong), they are difficult to interpret and to publish. Often these studies remain unpublished, the published record is biased, and resources were wasted. Thus, high power is a researcher’s friend. To make a comparison, if you could gamble on a slot machine with a 20% chance of winning or an 80% chance of winning, which machine would you pick? The answer is simple. Everybody would rather want to win. The problem is only that researchers have to invest more resources in a single study to increase power. They may not have enough money or time to do so. So, they are more like desperate gamblers. You need a publication, you don’t have enough resources for a well-powered study, so you do a low powered study and hope for the best. Of course, many desperate gamblers lose and are then even more desperate. That is where the analogy ends. Unlike gamblers in a casino, researchers are their own dealers and can use a number of tricks to get the desired outcome (Simmons et al., 2011). Suddenly, a study with only 20% power (chance of winning honestly) can have a chance of winning of 80% or more.
This brings us to the second advantage of high-powered studies. Power determines the outcome of a close replication study. If a researcher conducted a study with 20% power and found some tricks to get significance, the probability of replicating the result honestly is again only 20%. Many unsuspecting graduate students have wasted precious years trying to build on studies that they were not able to replicate. Unless they quickly learned the dark art of obtaining significant results with low power, they did not have a competitive CV to get a job. Thus, selective publishing of underpowered studies is demoralizing and rewards cheating.
None of this is a concern for Wegener and Fabrigar, who do not cite influential articles about the use of questionable research practices (John et al., 2012) or my own work that uses estimates of observed power to reveal those practices (Schimmack, 2012; see also Francis, 2012). Instead, they suggest that “problems with the overuse of power arise when the pre-study concept of power is used retrospectively to evaluate completed research” (p. 1115). The only problem that arises from estimating actual power of completed studies, however, is the detection of questionable practices that produce more reported significant results (often 100%) than one would expect given the low power to do so. Of course, for researchers who want to use QRPs to produce inflated evidence for their theories, this is a a problem However, for consumers of research, the detection of questionable results is desirable so that they can ignore this evidence in favor of honestly reported results based on properly powered studies.
The bulk of Wegener and Fabrigar’s article discusses the relationship between power and the probability of false positive results. A false positive result occurs when a statistically significant result is obtained in the absence of a real effect. The standard criterion of statistical significance, p < .05, states that a researcher that tests 100 false hypothesis without a real effect is expected to obtain 95 non-significant results and 5 false positive results. This may sound sufficient to keep false positive results at a low level. However, the false positive risk is a conditional probability based on a significant result. If a researcher conducts 100 studies, obtains 5 significant results, and interprets these results as real effects, the researcher has a false positive rate of 100% because 5 significant results are expected by chance along. An honest researcher would conclude from a series of studies with only 5 out of 100 significant results that they found no evidence for a real effect.
Now let’s consider a researcher that conducted 100 studies and obtained 24 significant results. As 24 is a lot more than the expected 5 studies by chance along, the researcher can conclude that at least some of the 24 significant results are caused by real effects. However, it is also possible that some of these results are false positives. Soric (1989 – not cited by Wegener and Fabrigar – derived a simple formula to estimate the false discover risk. The formula makes the assumption that studies of real effects have 100% power to detect a real effect. As a result, there are zero studies that fail to provide evidence for a real effect. This assumption makes it possible to estimate the maximum percentage of false positive results.

In this simple example, we have 4 false positive results and 20 studies with evidence for a real effect. Thus, the false positive risk is 4 / 24 = 17%. While 17% is a lot more than 5%, it is still pretty low and doesn’t warrant claims that “most published results are false” (Ioannidis, 2005). Yet, it is also not very reassuring if 17% of published results might be false positives (e.g., 17% of cancer treatments actually do not work). Moreover, based on a single study, we do not know which of the 24 results are true results and false results. With a probability of 17% (1/6), trusting a result is like playing Russian roulette. The solution to this problem is to conduct a replication study. In our example, the 20 true effects will produce significant results again because they were obtained with 100% power to do so. However, the chance to replicate one of the 4 false positive results is only 5/100 * 5 / 100 = 25 / 10,000 = 0.25%. So, with high-powered studies, a single replication study can separate true and false original findings.
Things look different in a world with low powered studies. Let’s assume that studies have only 25% power to produce a significant result, which is in accordance with the success rate in replication studies in social psychology (Open Science Collaboration, 2005).

In this scenario, there is only 1 false positive result and the false positive risk is only 1 out of 21, ~ 5%. Of course, researchers do not know this and have to wonder whether some of 21 significant results are false positives. When they conduct a replication study, only 6 (25/100 * 25/100) of their 20 significant results replicate. Thus, a single replication study does not help to distinguish true and false findings. This leads to confusion and the need for additional studies to separate true and false findings, but low power will produce inconsistent results again and again. The consequences can be seen in the actual literature in social psychology. Many literatures are a selected set of inconsistent results that do not advance theories.
In sum, high powered studies quickly separate true and false findings, whereas low powered studies produce inconsistent results that make it difficult to separate true and false findings (Maxwell, 2004, not cited by Wegener & Fabrigar).
Actions speak louder than Words
Over the past decade, my collaborators and I I have developed powerful statistical tools to estimate the power of studies that were conducted (Bartos & Schimmack, 2021; Brunner & Schimmack, 2022; Schimmack, 2012). In combination with Soric’s (1989) formula, estimates of actual power can also be used to estimate the real false positive risk. Below, I show some results when this method is applied to social psychology. I focus on the journal Personality and Social Psychological Bulletin for two reasons. First, Wegener and Fabrigar were co-editors of this journal right after concerns about questionable research practices and low power became a highly discussed topic and some journal editors changed policies to increase replicability of published results (e.g., Steven Lindsay at Psychological Science). Examining the power of studies published in PSPB when Wegener and Fabrigar were editors provides objective evidence about their actions in response to concerns about replication failures in social psychology. Another reason to focus on PSPB is that Wegener and Fabrigar published their defense of low powered research in this journal, suggesting a favorable attitude towards their position by the current editors. We can therefore examine whether the current editors changed standards or not. Finally, PSPB was edited from 2017 to 2021 by Chris Crandall, who has been a vocal defender of results obtained with questionable research practices on social media.
Let’s start with the years before concerns about replication failures became openly discussed. I focus on the years 2000 to 2012.
Figure 1 shows a z-curve plot of automatically extracted statistical results published in PSPB from 2000 to 2012. All statistical results are converted into z-scores. A z-curve plot is a histogram that shows the distribution of z-scores. One important aspect of a z-curve plot is the percentage of significant results. All z-scores greater than 1.96 (the solid vertical red line) are statistically significant with p < .05 (two-sided). Visual inspection shows a lot more significant results than non-significant results. More precisely, the percentage of significant results (i.e., the Observed Discovery Rate, EDR) is 71%.
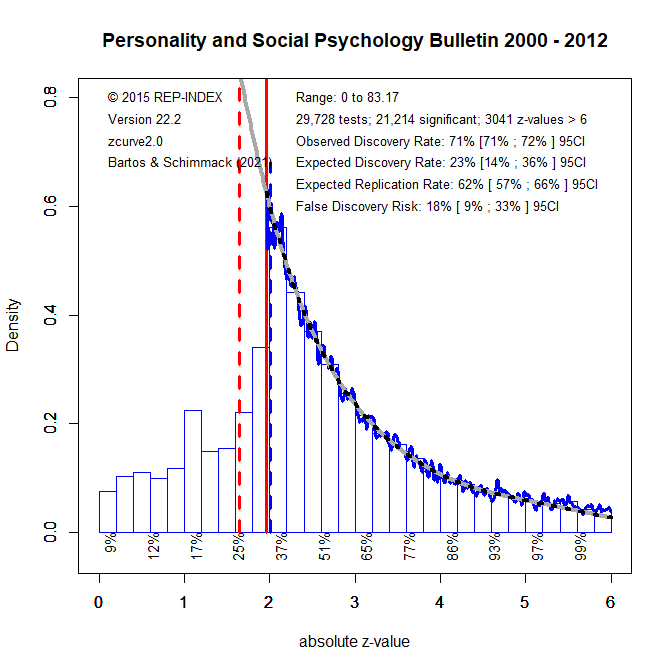
Visual inspection of the histogram also shows a strange shape to the distribution of z-scores. While the peak of the distribution is at the point of significance, the shape of the distribution shows a rather steep drop of z-scores just below z = 1.96. Moreover, some of these z-scores are still used to claim support for a hypothesis often called marginally significant. Only z-scores below 1.65 (p < .10, two-sided or .0 5 one-sided, the dotted red line) are usually interpreted as non-significant results. The distribution shows that these results are less likely to be reported. This wonky distribution of z-scores suggests that questionable research practices were used.
Z-curve analysis makes it possible to estimate statistical power based on the distribution of statistically significant results only. Without going into the details of this validated method, the results suggest that the power of studies (i.e., the expected discovery rate, EDR) would only produce 23% significant results. Thus, the actual percentage of 71% significant results is inflated by questionable practices. Moreover, the 23% estimate is consistent with the fact that only 25% of unbiased replication studies produce a significant result (Open Science Collaboration, 2005). With 23% significant results, Soric’s formula yields a false positive risk of 18%. That means, roughly 1 out of 5 published results could be a false positive result.
In sum, while Wegener and Fabrigar do not mention replication failures and questionable research practices, the present results confirm the explanation of replication failures in social psychology as a consequence of using questionable research practices to inflate the success rate of studies with low power (Schimmack, 2020).
Figure 2 shows the z-curve plot for results published during Wegener and Fabrigar’s reign as editors. The results are easily summarized. There is no significant change. Social psychologists continued to publish ~70% significant results with only 20% power to do so. Wegener and Fabrigar might argue that there was not enough time to change practices in response to concerns about questionable practices. However, their 2022 article provides an alternative explanation. They do not consider it a problem when researchers conduct underpowered studies. Rather, the problem is when researchers like me estimate the actual power of studies and reveal that massive use of questionable practices.

The next figure shows the results for Chris Chrandall’s years as editor. While the percentage of significant results remained at 70%, power to produce these results increased to 32%. However, there is uncertainty about this increase and the lower limit of the 95%CI is still only 21%. Even if there was an increase, it would not imply that Chris Crandall caused this increase. A more plausible explanation is that some social psychologists changed their research practices and some of this research was published in PSPB. In other words, Chris Crandall and his editorial team did not discriminate against studies with improved power.

It is too early to evaluate the new editorial team lead by Michael D. Robinson, but for the sake of completeness, I am also posting the results for the last two years. The results show a further increase in power to 48%. Even the lower limit of the confidence interval is now 36%. Thus, even articles published in PSPB are becoming more powerful, much to the dismay of Wegener and Fabrigar, who believe that “the recent overemphasis on statistical
power should be replaced by a broader approach in which statistical and conceptual forms of validity are considered together” (p. 1114). In contrast, I would argue that even an average power of 48% is ridiculously low. An average power of 48% implies that many studies have even less than 48% power.

Conclusion
More than 50 years ago, famous psychologists Amos Tversky and Daniel Kahneman (1971) wrote “we refuse to believe that a serious investigator will knowingly accept a .50 risk of failing
to confirm a valid research hypothesis” (p. 110). Wegener and Fabrigar prove them wrong. Not only are they willing to conduct these studies, they even propose that doing so is scientific and that demanding more power can have many negative side-effects. Similar arguments have been made by other social psychologists (Finkel, Eastwick, Reis, 2017).
I am siding with Kahneman, who realized too late that he placed too much trust in questionable results produced by social psychologists and compared some of this research to a train wreck (Kahneman, 2017). However, there is no consensus among psychologists and readers of social psychological research have to make up their own mind. This blog post only points out that social psychology lacks clear scientific standards and no proper mechanism to ensure that theoretical claims rest on solid empirical foundations. Researchers are still allowed to use questionable research practices to present overly positive results. At this point, the credibility of results depends on researchers’ willingness to embrace open science practices. While many young social psychologists are motivated to do so, Wegener and Fabrigar’s article shows that they are facing resistance from older social psychologists who are trying to defend the status quo of underpowered research.