This is part 2 of a series of blog posts that introduce a “monster model” of well-being. The first part explained how to build measurement models of affect and how to predict life-satisfaction from affect (Part 1). The key finding was that happiness and sadness are strongly negatively correlated, independently contribute to the prediction of well-being, and together account for about two-thirds of the variance in well-being. This means that about one-third (33%) of the variance in well-being is not explained by feelings.

While it has been known for over two decades that well-being has unique variance that is not explained by affect (Lucas et al, 1996), and the literature on well-being has increased exponentially in the 2000s, nobody has examined predictors of the unique variance in well-being that is not explained by affect. Part 2 examines this question.
When well-being research took off in the 1960, social scientists also started to measure well-being by asking separate questions about satisfaction with specific life domains (e.g., marriage, work, housing, income, etc.). It was commonly assumed that global life-satisfaction judgments are a summary of information about satisfaction with important domains (Andrews & Withey, ithey, 1976). However, this assumption was challenged by psychologists, who proposed that global judgments are rooted in personality and that global happiness creates a halo that colors the evaluation of life-domains (Diener, 1984). Influential review articles emphasized the importance of personality and downplayed the relevance of life domains (Diener et al., 1999; Heller et al., 2004). This changed in the 2000s, when longitudinal panel studies with representative samples showed that life-evens and circumstances matter a lot more than studies with small student samples suggested (Diener, Lucas, & Scollon, 2006). However, empirical research practices did not change and domain satisfaction remained neglected in psychological research. To my knowledge, there are only two datasets that used multiple methods (self-ratings and informant ratings) to measure domain satisfaction (Schneider & Schimmack, 2010; Payne & Schimmack, 2020). One of them is the Mississauga Family study.
Having mutli-method data of domain satisfaction makes it possible to add domain satisfaction as additional predictors of well-being to the model. The interesting novel question is whether domain satisfaction adds information about well-being that is not reflected in affective experiences. For example, is romantic satisfaction (marital satisfaction for parents) a predictor of life-satisfaction simply because a happy marriage makes life more pleasurable or are there aspects of marital life that influence well-being independent of its influence on affective experiences.
Rather than just adding all domain satisfaction measures in one step, it is useful to add these measures slowly, just like in cooking you don’t just toss all ingredients into a big pot at the same time.
Let’s start with romantic satisfaction. Only social psychologists could believe that marital satisfaction has no influence on well-being (Kahneman, 2011; Strack et al., 1988), exactly because it goes against anything that makes sense and would prove grandma wrong. The boring truth is that marital satisfaction is strongly correlated with well-being measures (Heller et al., 2004).
As a first step, we can also be agnostic about the relationship between marital satisfaction and affect and simply let all predictors correlate with each other. This is simply multiple regression with unobserved variables that control for measurement error. This model had good fit, CFI = .984, RMSEA = .028.
The figure shows the autogenerated model, which looks very messy because of all the correlated residual variances among ratings by the same rater as well as between informant ratings of mothers and fathers. This is another problem for publishing this work. Reviers may be vaguely familiar with SEM and able to follow a diagram, but complex models at some point can no longer be presented with a nice figure. When results are just a list of parameters, most psychologists lose interested very quickly (please send to a specialized journal for nerds, but these nerds are not interested in happiness).

Although a measurement model can be very messy and complex, the real hypothesis that was tested here is very simple, and the next figure shows the results. Romantic satisfaction had a significant (z = 4.99) unique effect on well-being. The unexplained variance decreased from 37% to 34% by three-percentage points.

Trying this for several domain satisfaction judgments revealed unique effects for work/academics, .3, goal-progress, .6, health, .2, housing, .4, recreation, .3, friendships, .2, and finances, .4. The only domains that did not add unique variance were weather and commute. However, just because domains predicted well-being above and beyond affect does not mean that they really contribute to well-being. The reason is that domain satisfactions are not independent of each other. It is therefore necessary to include them as simultaneous predictors of well-being.
A model with all of the significant domains and affect as predictors had good fit, CFI = .992, RMSEA = .015. The results showed that goal progress dominated as a unique predictor, .6. The only other significant (alpha = .05) predictors were housing, .2, and love, .2. The only other predictor with an effect size greater than .1 was money, p = .08. The residual variance in well-being in this model was reduced to 10%. Thus, domains make a substantial contribution to well-being above the influence of affect.
Most psychologists are used to multiple regression and focus now on the predictors that have a unique significant contribution. However, these results depend strongly on the choice of predictors. The fact that work/academics is not a unique predictor could simply reflect that this domain is important but its influence on well-being is fully captured by the measure of goal progress. It is therefore necessary to examine the relationships among the predictor variables. The correlations are shown in the next table.

The first observation is that everything is correlated with everything at non-trivial levels (all z > 5; all r > .1). This is not just a simple response style, because the measurement model removes rater specific biases. It is, however, possibel that some response styles are shared across family members.
The second observation is that there is clearly a structure to these correlations. Some correlations are notably stronger than others. For example, a very strong correlation is obtained for work/academics and goal progress, r = .8. Thus, the fact that work/academics was not a unique predictor does not mean that it is not an important life domain. Rather, it is a strong predictor of overall goal progress, which was a strong predictor of well-being. Another high correlation exists for friendships and recreation. Adding both as unique predictors can be a problem because most of the satisfaction with recreation may overlap with the satisfaction with friendship. A simple regression model only shows these effects in the explained variance, when the unique effects can be small and non-significant.
The first decision that has to be made is what to do with goal progress. It is not a specific life domain,but rather a broad measure that focuses on a specific type of satisfaction that arises from goal-related activities. One possibility is to simply not include it in the monster model (Payne et al., 2013; Zou et al., 2013). However, a monster model doesn’t try to be simple and easy. Moreover, excluding this predictor increased the residual variance in well-being from 10% to 17%. So, I decided to keep it and to allow specific domains to contribute to goal progress and goal progress to mediate the effects of these domains on life-satisfaction. The new question now is how much specific domains contribute to goal progress.
The overall model fit is not changed by modifying the relationship of goal progress to the other domains. The main finding was that work/academics was by far the strongest predictor of goal progress, .7 (z = 21). The only other significant (alpha = .05) effect would be love with a small effect size, .1 (z = 2.4). When, I modified the model and let work/academics be the only predictor of goal progress, the relationship strengthened to the point that there is little discriminant validity, .9. This still leaves the question why goal progress predicted unique variance in well-being. One possibility is shared method variance or top-down effects. That is, when raters make judgments of goal-progress they partly rely on overall life-satisfaction. In fact, modification indices suggested that model fit could be improved by allowing for a residual correlation between the goal progress and life-satisfaction factors.
The complex story for goal progress is instructive, but would be difficult to publish in a traditional journal that likes to pretend that scientists are clairvoyant and can predict everything ahead of time. Of course, most articles are written after researchers explored their data (Kerr et al., 1998). Here we see how the sausage is made, like in a restaurant where you can see the chef prepare your meal.
In short, goal progress is out after careful inspection of the correlations among the predictor variables. In this model, love (.2), work (.2), housing (.2) and money (.2) were all significant predictors (z > 3). However, remember that recreation and friendship were highly correlated. To see whether the shared variance between them adds to the prediction of well-being it is necessary to remove only one of them as predictors and see whether the other becomes significant. Although recreation showed a slightly stronger effect size, I chose friendship because recreation can happen at home and with one’s spouse. Table 3 does also show higher correlations with other domains for recreation than friendship. As expected, removing recreation as a predictor, increased the effect size for friendship, but it was still small (.1) and not significant. with a sampling error of .05, we can say that in this sample friendships did not matter as much as other domains. So, neither recreation nor friendship seem to be contributing to well-being (if you think that doesn’t make sense and you are getting crazy because Covid-19 doesn’t let you enjoy life, please wait till the final discussion. For UofT students and their parents work matters more than fun).
In this model, 17% of the variance in well-being is unexplained, compared to the model with only affect as predictor that left 37% unexplained. However, this does not mean that life domains explain 20% of the variance and affect explains 63%. We could reverse the order of predictors and suddenly life domains would explain the bulk of the variance in well-being. So, how important are our feelings really for well-being?
To answer this question, we have to make assumptions about the causal relationship of domain satisfaction and affect. Conceptually, affect is supposed to reflect the overall amount of happiness and sadness that people experience in their lives. This can happen at work, while hanging out with friends and while spending time at home with one’s spouse. Ideally, we would have measured affect during these different situations, but we didn’t. So, we have to assume that domain satisfaction judgments reflect how things are going in a domain and that how things are going in a domain can contribute to overall affect. Based on this reasoning, we assume that causality runs from domain satisfaction to affect, which in turn can influence well-being directly because we care about our feelings. If feelings matter, they should make a unique contribution to well-being and even sources of affect that are not influenced by life domains (e.g., affective dispositions) should contribute to life-satisfaction.
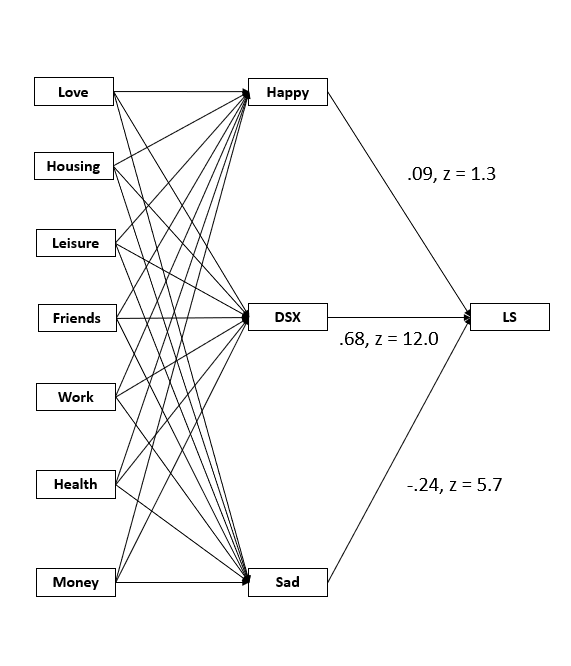
With some tricks, we can create unobserved variables that represents the variance in happiness and sadness that is not explained by life domains and then test the indirect effect of these variables on well-being. (the trick is to create a residual and remove the default residuals. Then the created residual can be treated like any other latent variable and be specified in the model indirect function). The results show virtually no effect for the unique variance in happiness, r = .05, z = 1.3 , but a small and significant effect for the unique variance in sadness, r = -.19, z = 5.6. This shows that the hedonic model of well-being has some serious problems (Schimmack et al., 2002). Rather than relying on their feelings to judge their lives, individuals seem to feel happy or sad when their lives are going well in important life domains.
The final model for today shows the main results, CFI = .991, RMSEA = .016. Combined, the life domains make a strong unique contribution to well-being. Happiness alone has a small effect that is not significant in this sample. Sadness makes a reliable but also relatively small unique contribution. The important results are the effects of the domains on happiness, sadness and life-satisfaction. It is easier to make sense of these results in a table.

The numbers in the table are not very meaningful in isolation. This is another problem of univariate meta-analysis that estimate effect sizes and nobody knows that to do with this information. Here we can use the numbers to see how much domains contribute to happiness, sadness, and the weighted average of domains that predicts life-satisfaction independently of affect.
One notable finding is that recreation and friendship are the strongest predictors of happiness. However, happiness was not a unique predictor of life-satisfaction judgments and these two domains also made a very small direct contribution to life-satisfaction judgments. Thus, these two domains seem to be rather unimportant for well-being. In contrast, financial satisfaction has no unique effect on affect, but a direct effect on life-satisfaction. This finding has also been observed in other studies, although with questionable measures of affect (Kahneman et al., 2006). The fact that even a multi-method model replicates this finding is notable. So, based on the present results, we would conclude that money or at least financial satisfaction matters for well-being, but friendships or health for that matter do not (see also Payne & Schimmack, 2020).
A big caveat is that this conclusion rests on the assumption that life-satisfaction judgments reflect the optimal weighing of information (Andrews & Withey, 1976). This is a strong assumption with surprisingly little support. In fact, studies with importance ratings of life domains consistently fail to confirm the prediction that more important domains are weighted more heavily, especially at the level of individuals (Rohrer & Schmukle, 2018). If we abandon this assumption, we are losing the ability to measure well-being because it is no longer clear how life domains should be weighted or we fall back to the assumption that well-being is nothing more than pleasure minus pain and use hedonic balance as our well-being measure. This is not an ideal solution because it makes well-being objective. Scientists are imposing a criterion on individuals that they are not actually find ideal. As a result, well-being science would give invalid advice about the predictors of well-being. Thus, for now we are stuck with the assumption that global life-satisfaction judgments are reasonably valid indicators of individuals’ typical concerns.
This concludes Part 2 of the monster model series. We covered a lot of ground today and had to deal with some of the most difficult questions in research on well-being that pushed us to consider the possibility that the most widely used measure of well-being, a simple global rating of life-satisfaction, may not be as valid as most well-being researchers think.
We also found out that individuals, at least those in this sample, seem to be much less hedonistic than I assumed twenty years ago (Schimmack et al., 2002). Twenty years ago it made sense to me that everything that matters is how were are feeling because I was very high in affect intensity (Larsen & Diener, 1987). I have come to realize that some people are relatively clam and don’t look at their lives through the affective lens. I have also become a bit calmer myself. So, I am happy to revise my earlier model and to see emotions more as guides that help us to realize how things are going. Thus, they are strongly related to well-being because they reflect to some extent whether our lives are good or not. However, affect that is elicited by other sources seems to have a relatively small effect on evaluations of our lives.
Part 3 will examine how all of this fits with theories that assume heritable and highly stable personality traits like neuroticism and extraversion influence well-being. To examine this question, I will add measures of the Big Five personality traits to the monster model.
Continue here to part 3.
Regarding the difference between goal progress and work/academics, maybe it reflects how much one sets goals on work/academics vs on something else?
It seems like one thing that could be interesting would be to model would be variation in preferences. Though probably also quite hard, as it would make the well-being model nonlinear.
Preferences have been ignored in well-being research. Definitely something to include.
I’ve been reading a lot about measurement, validity and strong theories recently, and it has made me think a lot about the basics of these things. One thing that I see mentioned is that in order to measure something, one needs to define what to measure – and define it properly, so as to make a strong theory!
Both because you’ve written about well-being here, and because I’ve had to use it as a secondary part of some models I’ve been wanting to use, I’ve had to think about how to properly define well-being and derive strong predictions from it. My sketch would be something like:
People have certain preferences. (Technically these could vary from individual to individual, but at the same time it would probably not be *terrible* to model them as constant.) These preferences might be understood very similarly to utility functions in economics, though quite possibly because humans are not rational, they might not work exactly the same. Still, in practice they might involve being more or less satisfied with various situations. Well-being is then satisfaction with one’s current/expected future situation.
People try to improve their own well-being. This gives us a lot of predictions, but they’re not of the kind you’d usually see, namely correlations of variables between people. Instead what you would see is that there are some situations people could be in that people almost never are in, and these are the same situations that contradict people’s preferences. So basically, it predicts something about means and variances.
Furthermore, sometimes people’s situations change. So you would expect their well-being to change accordingly. But with subtleties – since people try to improve their own well-being, cases where their situation apparently changes negatively would not actually reduce well-being if the change was under their control, as then presumably they wouldn’t have made that change. So you would mainly expect to see people’s well-being change as a result of external factors changing their situation, rather than as a result of personal choice changing their situation.
(… I remember reading about people claiming that people end up happier if they blame themselves rather than others for their situation. This is usually given as a conservative life advice. But could that just be an artifact of the above? I.e. if people have some tradeoff that they willingly make because it improves their situation, then presumably they will be more willing to blame themselves for the downsides of that tradeoff simply because it *is* themselves who chose it. So maybe actually one doesn’t get happier from blaming oneself, but instead one just mainly tends to blame oneself in the cases where it was worth it.)
Basically I’m thinking that with careful study, one could identify a whole bunch of micro structure here, and test all of this. This could give much more subtle theories of how everything is going to change, which would confirm the theories much more strongly.
Uhm, just to clarify, this isn’t meant as a critique of what you’re doing, just some musing about how one could create a very detailed (and very expensive I guess) model.
interesting ideas. I have defined well-being as preference realizations at some point. I think it is important that they differ across individuals despite some human universals (basic needs). I also think Diener’s item “My life is close to my ideal” is a good way to think about well-being. Ideals can vary but for everybody well-being depends on the discrepancy between the actual and ideal life.
> This means that about one-third (33%) of the variance in well-being is not explained by feelings.
I am sorry, should it be 37% or is this some other figure?