Methodologists have criticized psychological research for decades (Cohen, 1962; Gigerenzer & Sedlmeier, 1989; Maxwell, 2004; Sterling, 1959). A key concern is that psychologists conduct studies that are only meaningful when they reject the nil-hypothesis that results were not just a chance finding; p < .05, and that many studies had low statistical power to do so. As a result, many studies that were conducted remained unpublished, while studies that were published obtain significance only with the help of chance. Despite repeated attempts to educate psychologists about statistical power, there has been little evidence that researchers increased power of their studies. The main reason is that power analyses often showed that large samples were required that would require sometimes years of data collection for a single study. However, pressure to publish increased and nobody could simply work on a study without publishing. Therefore, psychologists found ways to produce significant results with smaller samples. The problem is that these questionable practices inflate effect sizes and make it difficult to replicate results. This produced the replication crisis in psychology (see Schimmack, 2020, for a review). So far, the replication crisis has played out mostly in social psychology because social psychologists have conducted the most attempts to replicate findings and produced a pile of replication failures in the 2010s. The replication crisis has produced a lot of discussion about reforms and many suggestions to increase statistical power. However, the incentive structure has not changed. Graduate students today are required to have a CV with many original articles to be competitive on the job market. Thus, strong forces counteract reforms of research practices in psychology.
In this blog post, I examine whether psychologists have changed their research practices in ways that increase statistical power. To do so, I use automatically extracted test statistics from 121 psychology journals that cover a broad range of psychology, including social, cognitive, personality, developmental, clinical, physiological, and brain sciences. With help of undergraduate students, I downloaded all articles from these journals from 2010 to 2019. To keep this post short, I am only presenting the results for 2010 and 2019. The latest year is particularly important because reforms require times and the latest year provides the best opportunity to see the effects of reforms.
All test-statistics are converted into absolute z-scores. A bigger z-score shows that a test-statistic showed stronger evidence against the nil-hypothesis that there is no effect. The higher the z-score, the greater the power of a study to reject the nil-hypothesis. Thus, any increase in power would result in a distribution of z-scores that is moved to the right. Z-curve (Brunner & Schimmack, 2019; Bartos & Schimmack, 2020), uses the distribution of significant z-scores (z > 1.96) to estimate several statistics. One statistic is the expected replication rate. This is the percentage of significant results that would be significant again if the studies were replicated exactly. Another statistic is the expected discovery rate (EDR). The EDR is the rate of significant results that is expected given the distribution of significant results. The EDR can be lower than the observed discovery rate (ODR) if there is selection for significance.
Figure 1 shows the results for 2010.
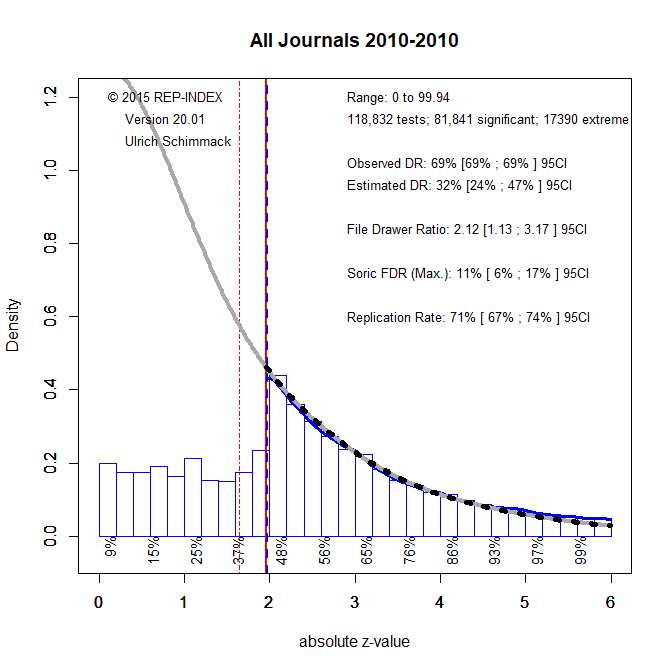
First, visual inspection shows clear evidence of the use of questionable research practices as there are a lot fewer z-scores just below 1.96 (not significant) than above 1.96. Figure 1 shows with the grey curve the distribution of non-significant results that is expected. The amount of selection is reflected in the discrepancy between the observed discovery rate of 69% and the expected discovery rate of 32%, 95%CI = xx to xx.
The expected replication rate is 71%, 95%CI = xx xx . This is much higher than the estimate of 37% based on the Open Science Collaboration project (Science, 2015). However, there are two caveats. First, the present analysis is based on all reported statistical tests, including manipulation checks that should produce very strong evidence against the null-hypothesis. Results for focal and risky hypothesis tests will be lower. Second, the ERR assumes that studies can be replicated exactly. This is typically not the case in psychology (Lykken, 1968; Stroebe & Strack, 2014). Bartos and Schimmack (2020) found that the EDR was a better predictor of actual replication outcomes. Assuming that this finding generalizes, the present estimate of 32% would be consistent with the Open Science Collaboration results of 37%.
Figure 1 establishes baseline results for 2010 at the beginning of the replication crisis in psychology. Figure 2 shows the results nine years later.
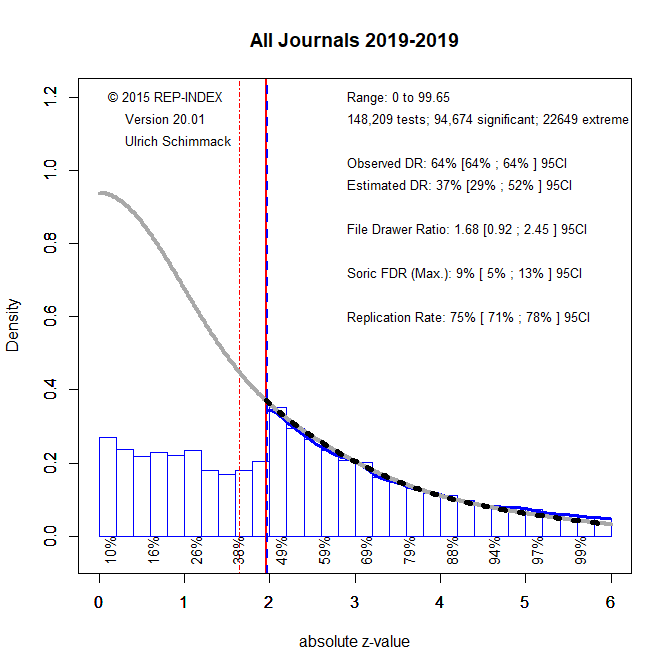
A comparison of the results shows a small improvement. The Observed Discovery Rate decreased from 69% to 64%. This means that researchers are reporting more non-significant results. The EDR increased from 32% to 37%. The ERR also increased from 71% to 75%. However, there is still clear evidence that questionable research practices inflate the percentage of significant results in psychology journals and the small increase in EDR and ERR predicts only a small increase in replicability. Thus, if the Open Science Collaboration Project were repeated with studies from 2019, it is still likely to produce fewer than 50% successful replications.
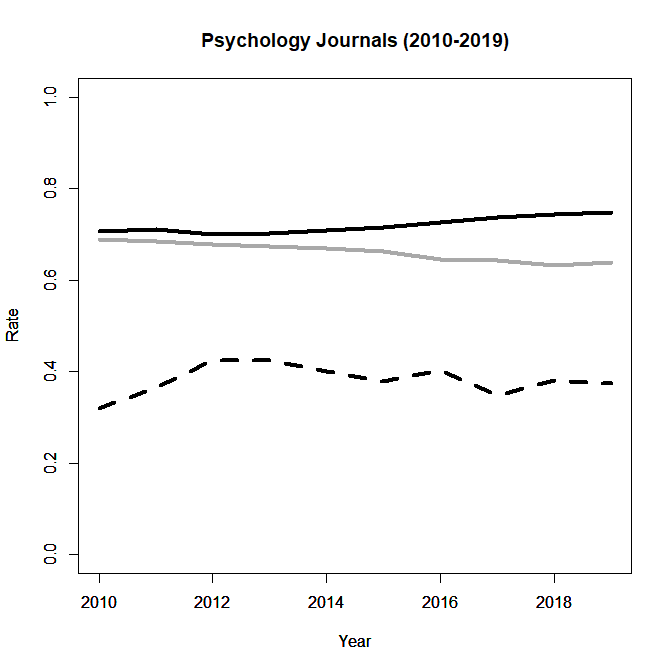
Figure 3 shows the ERR (black), ODR (grey), and EDR (black, dotted) for all 10 years. The continues trend for the ERR suggests that power is increasing a bit, at least in some areas of psychology. However, the trend for the EDR shows no consistent improvement, suggesting that editors are unwilling or unable to reject manuscripts that used QRPs to produce just-significant results. A simple solution might be to ask either for (a) pre-registration with clear power analysis that is followed exactly or (b) simply demand a more stringent criterion of significance, p < .005, to compensate for the hidden multiple-comparisons.
Conclusion
These results provide important scientific evidence about research practices in psychology. Dozens of articles have discussed the replication crisis. Dozens of editorials by new editors have introduced new policies to increase the replicability of psychological results. However, without hard evidence claims about progress are essentially projective tests that say more about the authors than about the state of psychology as a science. The present results provide no evidence that psychology as a field has successfully addressed problems that are decades old, or can be considered a leader in openness and transparency.
Most important, there is no evidence that researchers listen to Cohen’s famous saying “Less is more, except for sample size.” Instead, they are publishing more and more studies in more and more articles, which leads to more and more citations, which looks like progress on quantitative indicators like Impact Factors. However, most of these findings are only replicated in conceptual replication studies that are also selected for significance, giving false evidence of robustness (Schimmack, 2012). Thus, it is unclear which results are replicable and which results are not.
It would require enormous resources to follow up on these questionable results with actual replication studies. To improve psychology, psychologists need to change the incentive structure. To do so, we need to quantify strength of evidence and stop treating all results that are p < .05 as equally significant. A z-score of 2 is just significant, while a z-score of 5 corresponds to the criterion in particle physics that is used to claim a decisive result. Investing resources in decisive studies needs to be rewarded because a single well-designed experiment with z > 5 provides stronger evidence than many weak studies with z = 2, especially if just-significant results may be obtained with questionable practices that inflate effect sizes.
The only differences between my criticism and previous criticism of low powered studies is that technology now makes it possible to track the research practices of psychologists in real time. Students downloaded the articles for 2019 at the beginning of February and the processing of this information took a couple of days (mainly to convert PDFs into txt files). Running a z-curve analysis with bootstrapped confidence intervals takes only a couple of minutes. Therefore, we have hard empirical evidence about research practices in 2019 and the results show that questionable research practices continue to be used to publish more significant results than the power of studies warrants. I hope that demonstrating and quantifying the use of these practices helps to curb their use and to reward researchers who conduct well-powered studies.
A simple way to change the incentive structure is to ban QRPs and treat them like other research fraud. John et al. (2012) introduced the term “scientific doping” for questionable research practices. If sports organizations can ban doping to create fair competitions, why couldn’t scientists do the same. The past decade has shown that they are unable to self-regulate. It is time for funders and consumers (science journalists, undergraduate students, textbook writers) to demand transparency about research practices and the end of fishing for significance.