Social psychology is based on the fundamental assumption that brief situational manipulations can have dramatic effects on behavior. This assumption seemed to be justified by sixty years of research that often demonstrated large effects of subtle and sometimes even subliminal manipulations of the situation. However, since 2011 it has become clear that these impressive demonstrations were a sham. Rather than reporting the actual results of studies, social psychologists selectively reported results that were statistically significant, and because they used small samples, effect sizes were inflated dramatically to produce significant results. Thus, selective reporting of results from between-subject experiments with small samples ensured that studies could only provide evidence for the power of the situation.
Most eminent social psychologists who made a name for themselves using this flawed scientific method have been silent and have carefully avoided replicating their cherished findings from the past. In a stance of defiant silence, they pretend that their published results are credible and should be taken seriously.
A younger generation of social psychologists has responded to the criticism of old studies by improving their research practices. The problem for these social psychologists is that subtle manipulations of situations at best have subtle effects on behavior. Thus, the results are no longer very impressive, and even with larger samples, it is difficult to provide robust evidence for them. This is illustrated with an article by Van Dessel , Hughes, and De Houwer (2018) in Psychological Science, 2018.
The article has all the feature of the new way of doing experimental social psychology. The article received badges for sharing materials, sharing data, and preregistration of hypotheses. The authors also mention an a-priori power analysis that assumed a small to medium effect size.

The OSF materials provide further information about power calculations in the Design documents of each study (https://osf.io/wjz3u/). I compiled this information in the Appendix. It shows that the authors did not take attrition due to exclusion criteria into account and that they computed power for one-tailed significance tests. This would lead to lower power in post-hoc power analyses with two-tailed significance tests that are used in the article. The authors also assumed a stronger effect size for Studies 3 and 4, although these studies tested riskier hypotheses (actual behavior, one-day delay between manipulation and measurement of dependent variables). Most important, the authors powered studies to have 80% power for each individual hypothesis tests, which means that they can at best expect to find 80% significant results in their tests of multiple hypotheses (Schimmack, 2012).
Indeed, the authors found some non-significant results. For example, the IAT did not show the predicted effect in Study 1. However, Studies 1 and 2 mostly showed the predicted results, but they lack ecological validity because they examined responses to novel, fictional stimuli.
Studies 3 and 4 are more important for understanding actual human behaviors because they examined health behaviors with cookies and carrots as stimuli. The main hypothesis was that a novel Goal-Relevant Avatar-Consequences Task would shift health behaviors intentions, and attitudes. Table 3 shows means for several conditions and dependent variables that produce 12 hypothesis tests.
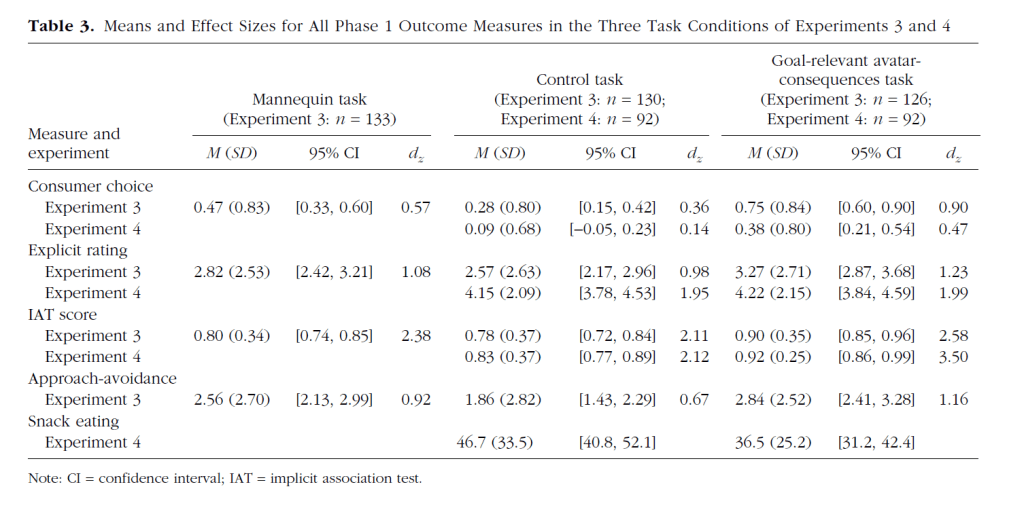
The next table shows the t-values for the 12 hypothesis tests. These t-values can be converted into p-values, z-scores, and observed power. The last column records whether the result is significant with alpha = .05.
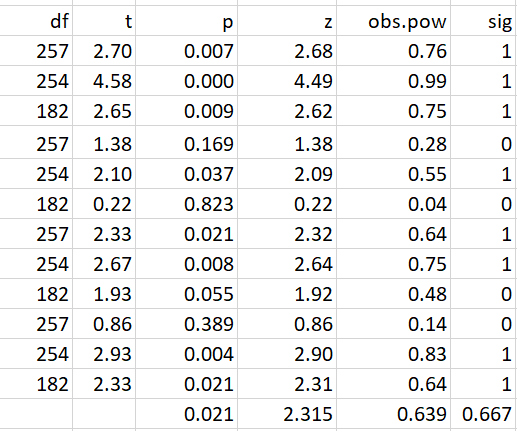
The most important result is that median observed power is 64% and matches the success rate of 67%. Thus, the results are credible and there is no evidence to suggest that QRPs were used to produce significant results. However, the consistent estimates also suggest that the studies did not have 80% power as the authors intended based on their a prior assumption that effect sizes would be small to moderate. In fact, the average effect size is d = .29. An a priori power analysis with this effect size shows that n = 188 participants per cell (total N = 376) are needed to achieve 80% power. Thus all studies were underpowered. .
Power can be improved by combining theoretically equivalent cells. This produces significant results for consumer choice, d = .36, t(571) = 4.21, the explicit attitude measure, d = .24, t(571) = 2.83, and the IAT, d = .33, t(571) =3.81.
Thus, the results show that the goal-relevant avatar-consequence task can shift momentary behavioral intentions and attitudes. However, it is not clear whether it actually changes behavior. The reason is that Study 4 was underpowered with only 92 participants in each cell and the snack eating effect was just significant, p = .018. This finding first needs to be replicated with an adequate sample.
Study 3 aimed to demonstrate that the effects of a brief situational manipulation can have lasting effects. As a result, participants completed a brief survey on the next day. The results are reported in Table 3.

This table allows for 10 hypothesis tests. The results are shown in the next table.

First, I did not include the question about difficulty because it is difficult to say how the situational manipulation should affect it. The item also produced the weakest evidence. The remaining 8 tests showed three significant results. The success rate of 38% is matched by the average observed power, 35%. Thus, once more there is no evidence that QRPs were used to produce significant results. At the same time, the power estimate shows that the study did not have 80% power. One reason is that the average effect size is weaker, d = .22. An a priori power analysis shows that n = 326 participants per cell would be needed to have 80% power. Thus, the actual cell frequencies of n = 99 to 108 were too small to expect consistent results.
The inconsistent results make it difficult to interpret the results. It is possible that the manipulation had a stronger effect on ratings of unhealthy behaviors than on healthy behaviors, but it is also possible that the pattern of means changes in a replication study.
The authors conclusion, however, highlights statistically significant results as if non-significant results are theoretically irrelevant.
“Compared with a control training, consequence-based approach-avoidance training (but not typical approach-avoidance training) reduced self-reported unhealthy eating behaviors and increased healthy eating intentions 24 hr after training” (p. 1907).
This conclusion is problematic because the pattern of significant results was not predicted a priori and strongly influenced by random sampling error. Selecting significant results from a larger set of statistical tests creates selection bias and the results are unlikely to replicate when studies have low power. This does not mean that the conclusions are false. It only means that the results need to be replicated in a study with adequate power (N = 326 x 3 = 978).
Conclusion
Social psychologists have a long tradition of experimental research that aims to change individuals’ behaviors with situational manipulations in laboratories. In 2011, it became apparent that most results in this tradition lack credibility because researchers used small samples with between-subject designs and reported only significant results. As a result, reported effect sizes are vastly inflated and give a wrong impression of the power of situations. In response to this realization some social psychologists have embraced open science practices and report all of their results honestly. Bias tests confirmed that this article reported as many significant results as the power of studies justifies. However, the observed power was lower than the a priori power that researchers assumed they had when they planned their sample sizes. This is particularly problematic for Studies 3 and 4 that aimed to show that results last and influence actual behavior.
My recommendation for social psychologists is to take advantage of better designs (within-subject), conduct fewer studies, and to include real behavioral measures in these studies. The problem for social psychologists is that it is now easy to collect data with online samples, but these studies do not include measures of real behavior. The study of real behavior was done with a student sample, but it only had 92 participants per cell, which is a small sample size to detect the small to moderate effects of brief situational manipulations on actual behavior.
APPENDIX

1 thought on “The (not so great) Power of Situational Manipulations in the Laboratory”