
Every student in psychology is introduced to the logic of Null-Hypothesis Significance Testing (NHST). The basic idea is to establish the long-run maximum probability that a significant result is a false positive result. A false positive result is called a type-I error. The standard for an acceptable type-I error risk is 5%. Statistics programs and articles often highlight results with a p-value less than 0.05. Students quickly learn that the goal of statistical analysis is to find p-values less than .05.
NHST has been criticized for many reasons. This blog post focuses on the problem when NHST is used to hunt for significant results and when only significant results are reported. Hunting for significant results in itself is not a problem. If a researcher conducts 100 statistical tests and reports all results, the risk of a type-I error is controlled by the significance criterion. With alpha = .05, no more than 5 of the 100 tests can produce a false positive result. If, for example, 20 results are significant, it is clear that some of the significant results are true discoveries.
The problem arises when only significant results are reported (Sterling, 1959). If a researcher reports 20 significant results, it is not clear whether 20, 100, or 400 tests were conducted. However, this has important implications for the assessment of type-I errors. With 20 tests and 20 significant results, the type-I error is minimal, with 100 tests it is moderate (1 out of 4 significant results could be false positives) and with 400 tests (1 out of 20 = 5%) it is practically certain that at least some of the significant results are false positives. After all, the expected value if all 400 studies tests false hypotheses is 5%. So observing only 5% non-significant results in 400 tests suggests that some of these significant results are false positives.
The Replication Crisis and the True Type-I Error Risk
The selective publishing of only significant hypothesis tests is a major problem in psychological science (Sterling, 1959; Sterling et al., 1995), but psychologists only recently became aware of this problem (Francis, 2012; John et al., 2012; Schimmack, 2012). Once results are selected for significance, the true type-I error risk increases as a function of the actual number of tests that were conducted. While alpha is 5% in all studies, the percentage of significant results is unknown because it is unknown how many tests were conducted.
Type-I Error Risk and the File Drawer
Rosenthal (1979) introduced the concept of a file drawer. The proverbial file-drawer contains all of the unpublished studies that a researcher conducted that produced non-significant results.
If all studies had the same statistical power to produce a significant result, the size of the file-drawer would be self-evident. Studies with 50% power have a long-run probability of obtaining 50% significant results, by definition. Thus, there are also 50% studies with non-significant results. It follows that for each published significant result, there is a non-significant result in the proverbial file-drawer (File-Drawer Ratio 1:1; this simple example assumes independence of hypothesis tests).
If power were 80%, there would be only one non-significant result in the file-drawer for every 4 published significant results (File-Drawer Ratio 1:4 or 0.25 :1). However, if power is only 20%, there would be 4 non-significant results for every published significant result (File-Drawer Ratio 4:1).
Things are more complicated when studies vary in power. If we assume that some studies are true positives and others are false positives, the probability of a significant result varies across studies. Using a simple example, assume that 80 studies are false positives and 20 studies have 50% power. In this case, we expect 14 significant results; 80 * .05 = 4 + 20 * .5 = 1 == 14.
The 5% error rates is true for the 100 studies that were conducted, but it would be wrong to believe that only 5% of the selected set of 14 studies with significant results could be false positives. In this example, we would falsely assume that at most 1 of the 14 studies is a false positive; 14 * .05 = 0.7 studies. However, in this case, we know that there are actually 4 false positive results. We do get the correct estimate of the maximum number of false positives, if we start with the actual number of studies that were conducted, which gives a false positive risk of 5 studies, which would be a percentage of 5/14 = 36%. Thus, up to 36% of the reported 14 studies could be false positives. Thus, the actual risk is 7 times larger than the claim p < .05 suggests.
In short, we need to know the size of the file-drawer to estimate the percentage of reported results that could be false positives.
Estimating the Size of the File Drawer
Brunner and Schimmack (2018) developed a statistical method, z-curve, that can estimate mean power for a set of studies with heterogeneity in power, including some false positive results. The main purpose of the method was to estimate mean power for the set of published studies that produced significant results. However, the article also contained some theorems that make it possible to estimate the size of the file drawer.
Z-curve is a mixture model that models the distribution of observed test statistics (z-scores) as a mixture of studies with different levels of power. Bruner and Schimmack (2018) introduced a model with varying non-centrality parameters and weights. However, it is also possible to keep the non-centrality parameters constant and only the weights are free model parameters. The fixed non-centrality parameters can include a value of 0 to model the presence of false positive results. The latest version of z-curve uses fixed values of 0, 1, 2, 3, 4, 5, and 6. Values greater than 6 are not needed because z-curve treats all observed z-scores greater than 6 as having a power of 1.
The power values corresponding to these fixed non-centrality parameters are 5%, 17%, 52%, 85%, 98%, 99.9%, and 100%. Only the lower power values are important for the estimation of the file-drawer because high values imply that nearly all attempts produce significant results.
To illustrate the method, I focus on the lowest three power values: 5%, 17% and 52%. Assume that we observe 100 significant results with the following mixture of power values: 30 studies have 5% power, 34 studies have 17% power, and 26 studies have 52% power, and we want to know the size of the file drawer.
To get from the observed number of studies to the study that were actually run, we need to divide the number of observed studies by power (see Brunner & Schimmack, 2018, for a mathematical proof). With 5% power (i.e., false positive results), it requires 1/0.05 = 20 studies to produce 1 significant result in the long run. Thus, if 30 significant results were obtained with 5% power, 600 studies had to be run (600 * 0.05 = 30). With 17% power, it would require 200 studies to produce 34 significant results. And with 52% power, it would require 50 studies to produce 26 significant results. Thus, the total number of studies that are needed to obtain 100 significant results is 600 + 200 + 60 = 850. It follows that 750 (850 – 100) non-significant results are in the file drawer.
The following simulation illustrates how z-curve estimates the size of the file-drawer. Data are generated using standard normal distributions with means 0, 1, and 2. To achieve large sample accuracy, there are 800,000 observations (M = 0, k = 800,000; M = 1, k = 200,000; & M = 2, k = 50,000).
Only significant results (to the right of the red line at z = 1.96) were used to fit the model. The non-significant results are shown to see how well the model predicts the size of the file drawer.
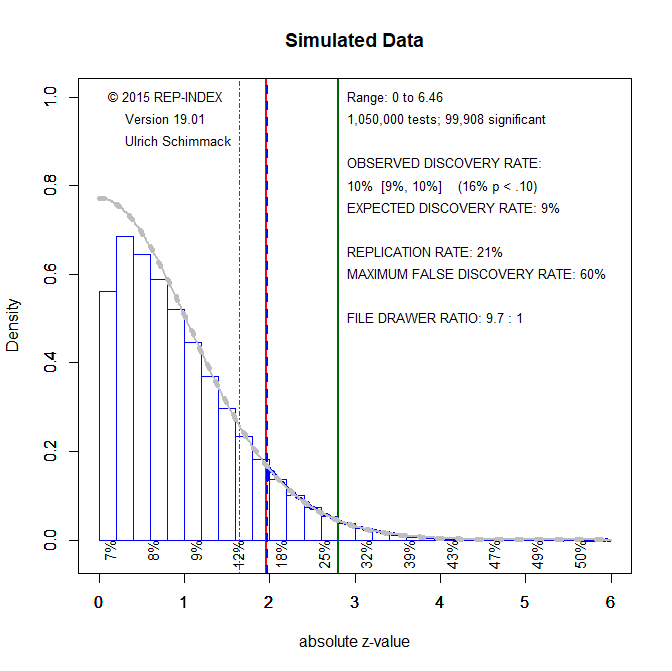
The gray line shows the predicted distribution by the model. It shows that the predicted distribution of non-significant results matches the observed distribution of non-significant results, although the model slightly overestimates the size of the file-drawer.
The Expected Discovery Rate is the percentage of significant results for all studies including the file-drawer. The actual discovery rate is given by the number of studies (k = 1,050,000) and the actual number of significant results (k = 99,908), which is 99,908/1,050,000 = 9.52. The expected discovery rate is 9%, a fairly close match given the size of the file drawer.
Another way to look at the size of the file-drawer is the file-drawer ratio. That is, how many studies with non-significant results are in the file drawer for every significant result. The actual file-drawer ratio is (1,050,000 – 99,908)/99,908 = 9.51. That is, for every significant result, 9 to 10 non-significant results were not reported. The estimated file-drawer ratio is 9.7, a fairly close match.
The next example shows how z-curve performs when mean power is higher and the file-drawer is smaller. In this example, there were 100000 cases with z = 0, 200000 cases with z = 1, 400000 cases with z = 2, and 300000 cases with z = 3. The expected discovery rate for this simulation is 50%. With mean power of 50%, the file-drawer ratio is 1:1. That is, for each significant result there is one non-significant result.
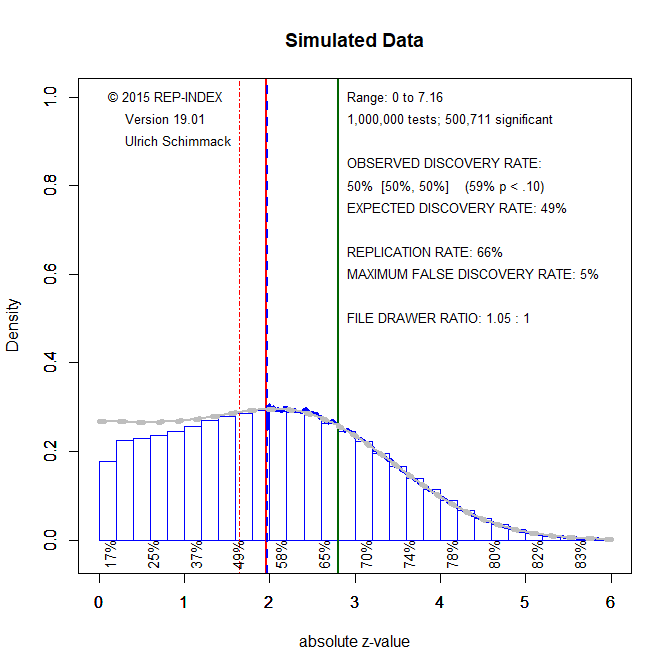
The grey line shows that z-curve slightly overestimates the size of the file-drawer. However, this bias is small. The expected discovery rate is estimated to be 49% and the file-drawer ratio is estimated to be 1.05 : 1. These estimates closely match the actual results.
If power is greater than 50%, the file-drawer ratio is less than 1:1. The final simulation assumes that researchers have 80% power to test a true hypothesis, but that 20% of all studies are false positives. The mixture of actual power is 200,000 cases with M = 0, 100,000 cases with M = 2, 400,000 cases with M = 3, and 300,000 cases with M = 4. The mean power is 70%.
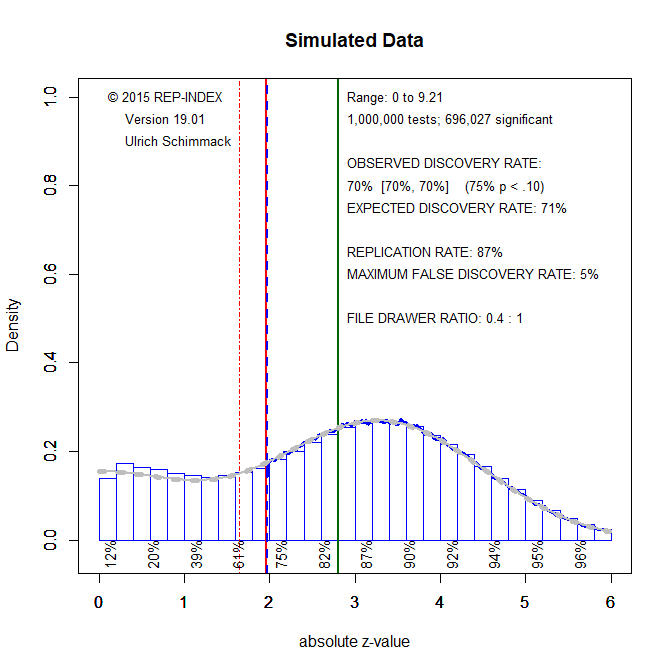
Once more, z-curve fits the actual data quite well. The expected discovery rate of 71% matches the actual discovery rate of 70% and the estimated file-drawer ratio of 0.4 to 1 also matches the actual file-drawer ratio of 0.44 to 1.
More extensive simulations are needed to examine the performance of z-curve. With smaller sets of studies, random sampling error alone will produce some variability in estimates. However, large differences in file-drawer estimates such as 0.4:1 versus 10:1 are unlikely to occur by chance alone.
Real Examples
To provide an illustration with real data, I fitted z-curve to Roy F. Baumeister’s results in his most influential studies (see Baumeister audiT for the data).
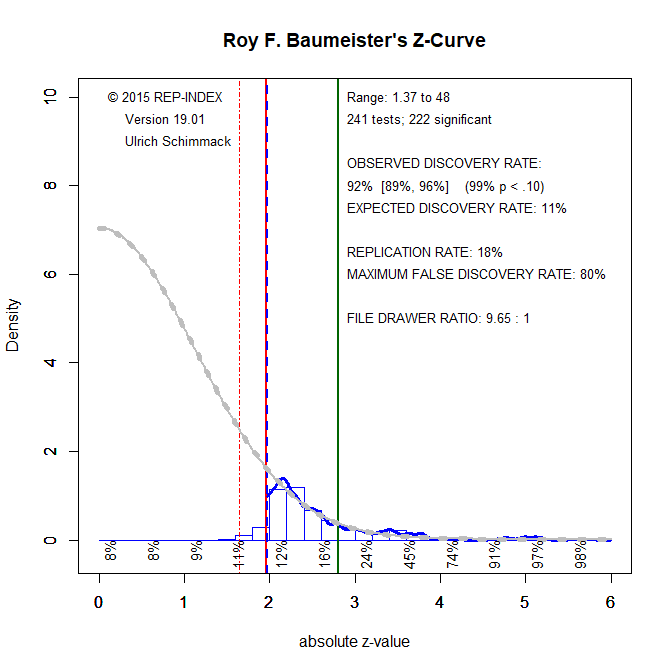
Visual inspection shows that Roy F. Baumeister’s z-curve matches most closely to the first simulation. The quantitative estimates confirm this impression. The expected discovery rate is estimated to be 11% and the file-drawer ratio is estimated to be 9.65 : 1. That is, for every published significant result, z-curve predicts 9 unpublished results with non-significant results. The figure shows that only a few non-significant results were reported in Baumeister’s articles. However, all of these non-significant results cluster in the region of marginally significant results (z > 1.65 & z < 1.96) and were interpreted as support for a hypothesis. Thus, all non-confirming evidence remained hidden in a fairly large file-drawer.
It is rare that social psychologists comment on their research practices, but in a personal communication Roy Baumeister confirmed that he has a file-drawer with non-significant results.
“We did run multiple studies, some of which did not work, and some of which worked better than others. You may think that not reporting the less successful studies is wrong, but that is how the field works.” (Roy Baumeister, personal email communication)
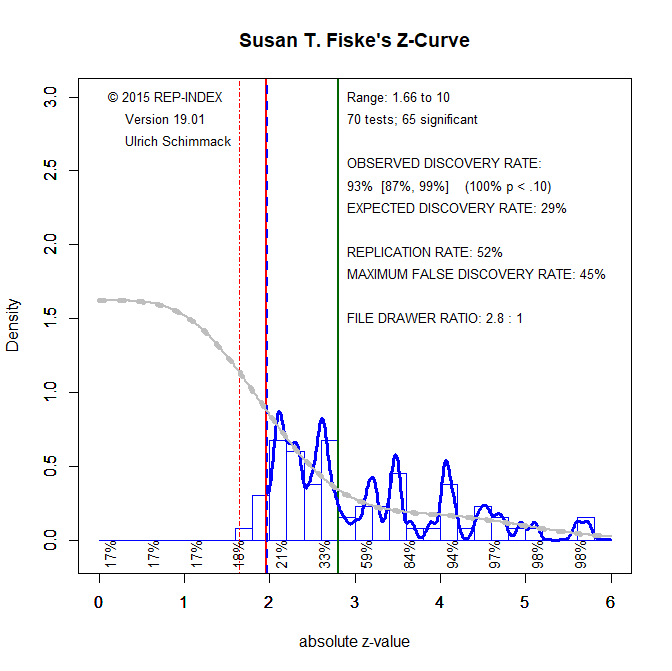
Other social psychologists have a smaller file-drawer. For example, the file-drawer ratio for Susan T. Fiske is only 2.8 : 1, which is only a third of Roy F. Baumeister’s file-drawer. Thus, while publication bias ensures that virtually everybody has a file-drawer, the size of the file-drawer can vary considerably across labs.
File Drawer of Statistical Analysis Rather than Entire Studies
It is unlikely that actual file-drawers are as large as z-curve estimates. Dropping studies with non-significant results is only one of several questionable research practices that can be used to report only significant results. For example, including several dependent variables in a study can help to produce a significant result for a single dependent variable. In this case, most studies can be published. Thus, it is more accurate to think of the file-drawer as being filled with statistical outputs with non-significant results rather than entire studies. This does not reduce the problem of questionable research practices. Undisclosed multiple comparisons within a single data set undermine the replicability of published results just as much as failures to disclose results from a whole study.
Nevertheless, z-curve estimates should not be interpreted too literally. If there were such a thing as a Replicability Bureau of Investigation (RBI), and the RBI would raid the labs of a researcher, the actual size of the file-drawer may differ from the z-curve prediction because it is impossible to know which questionable research practices were actually use to report only confirming results. However, the estimated file-drawer provides some information about the credibility of the published results. Estimates below the ratio of 1:1 suggest that the data are credible. The higher the file-drawer ratio is, the less credible the published results become.
File-Drawer Estimates and Open Science
The main advantage of being able to estimate file-drawers is that it is possible to monitor research practices in psychology labs without the need of an RBI. Reforms such as a priori power calculations, preregistration and more honest reporting of non-significant results should reduce the size of file-drawers. Requirements to share all data ensure open file-drawers. Z-curve can be used to evaluate whether these reforms are actually improving psychological science.
Dear Uli,
how to deal with the negative z values due to results opposite the alternative hypothesis?
z-curve is not designed for sets of studies where all effects have a predicted direction (standard effect size meta-analysis). However, as only significant values are used, you can perform a z-curve analysis by including only significant z-scores in the right direction in the analysis.