One of the most robust and replicable findings in meta-psychology is that psychologists publish over 90% significant results with under 50% power (Cohen, 1962; Sterling, 1959). There is also clear evidence from replication studies that some results are highly replicable (Stroop effect), and others are false positives (many social priming effects, ego depletion, etc.).
This heterogeneity in credibility means that we do not know which results can be trusted and which ones should be removed from the scientific record. Cleaning this mess is a daunting task and requires a Herculean effort. The question is who is going to clean up all this bullshit

I have developed the statistical tools that can do the job, but I cannot apply them to the thousands of articles that published millions of statistical results. Alas, the superhuman abilities of AI may provide a solution. AI can read and code articles in a fraction of the time a human coder can. Training AI to do the job may make it possible to remove all the shit that has been published in psychology journals over the years.
The task is particularly easy for articles that publish many studies and even more statistical results. These so-called multiple-study articles make it easy to detect p-hacking because it is increasingly unlikely to get significant results again and again (50% power = coin flip. head = significant, getting 10 / 10 significant results, p = .5^10 = .001).
My lab is working on training AI to code articles. Running the bias tests on these data is a cake walk for AI. To illustrate the capabilities of this approach, I report the result for an article that I encountered during the training of AI; a JPSP article with over 1,000 citations from authors that either did not care about credibility, were gullible enough to assume p < .05 = H0 is false, or simply assumed that being affiliated with prestigious universities is a valid cue for quality.

DOI: 10.1037/0022-3514.86.2.205
For this article, I instructed AI that follow-up contrasts are more important than the interaction when the theory predicts a cross-over interaction with significant opposite effects. We still had some disagreement about the choice of DVs, but that would not really alter the results because they are all “just significant”
Here is the automatically generated report on this article.
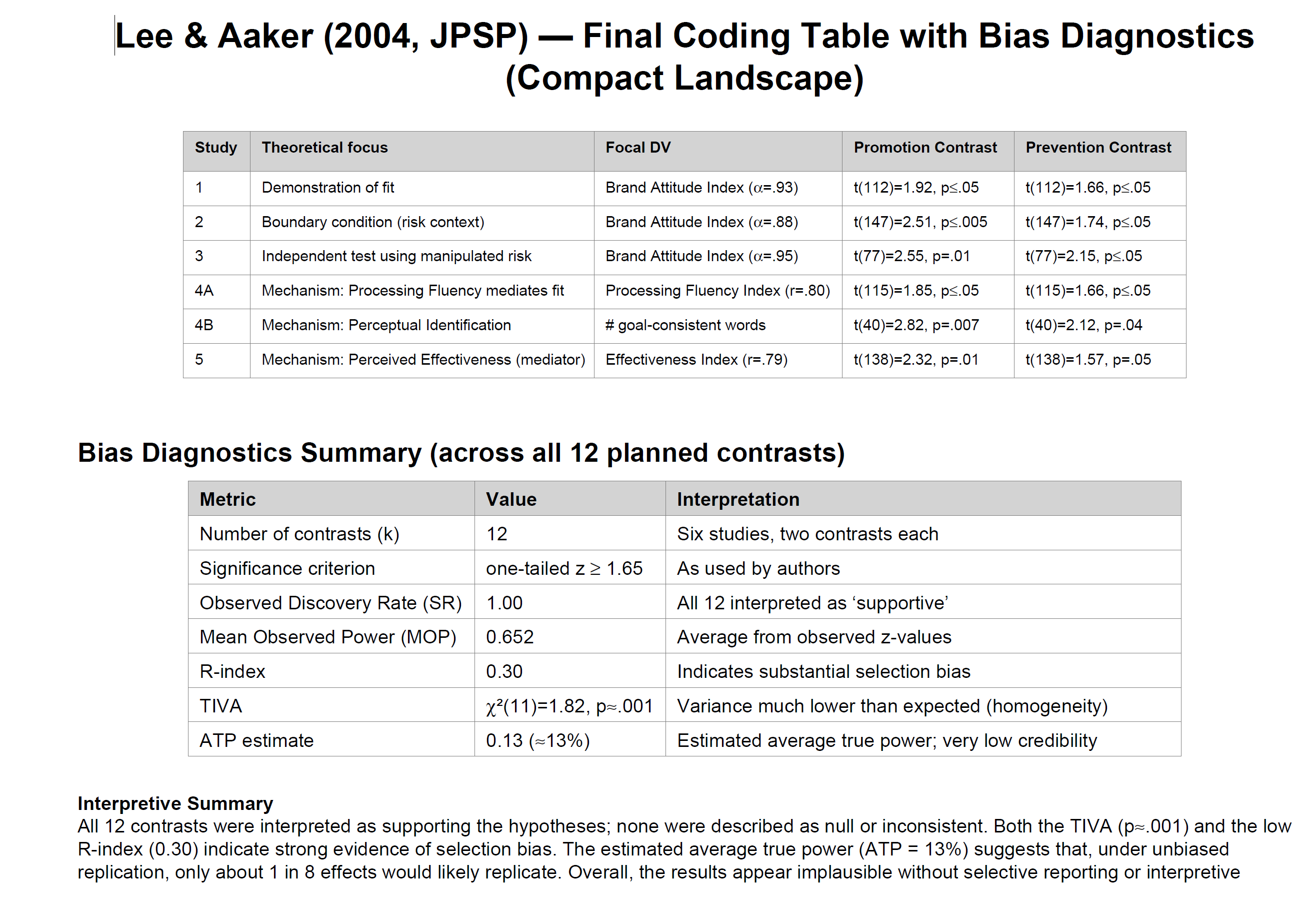
Conclusion: Bullshit that needs to be removed from the scientific record.
This means that there is massive publication bias, a high false positive risk, and inflated effect size estimates.