

A small literature suggests that babies can add and subtract. Wynn (1992) showed 5-month olds a Mickey Mouse doll, covered this toy, and placed another doll behind the cover to imply addition (1 + 1 = 2). A second group of infants saw two Mickey Mouse dolls, that were covered and then one Mickey Mouse was removed (2 – 1 = 1). When the cover was removed, either 1 or 2 Mickeys were visible. Infants looked longer at the incongruent display, suggesting that they expected 2 Mickeys in the addition scenario and one Mickey in the subtraction scenario.
Both studies produced just significant results; Study 1, t(30) = 2.078, p = .046 (two-tailed), Study 2 , t(14) = 1.795, p = .047 (one-tailed). Post-2011, these just significant results raise a red flag about the replicability of these results.


This study produced a small literature that was meta-analyzed by Christodoulou, Lac, and Moore (2017). The headline finding was that a random-effects meta-analysis showed a significant effect, d = .34, “suggesting that the phenomenon Wynn originally reported is reliable.”
The problem with effect-size meta-analysis is that effect sizes are inflated when published results are selected for significance. Christodoulou et al. (2017) examined the presence of publication bias using a variety of statistical tests that produced inconsistent results. The Incredibility Index showed that there were just as many significant results (k = 12) as one would predict based on median observed power (k = 11). Trim-and-fill suggested some bias, but the corrected effect size estimate would still be significant, d = .24. However, PEESE showed significant evidence of publication bias, and no significant effect after correcting for bias.
Christodoulou et al. (2017) dismiss the results obtained with PEESE that would suggest the findings are not robust.
For instance, the PET-PEESE has been criticized on grounds that it severely penalizes samples with a small N (Cunningham & Baumeister, 2016), is inappropriate for syntheses involving a limited number of studies (Cunningham & Baumeister, 2016), is sometimes inferior in performance compared to estimation methods that do not correct for publication bias (Reed, Florax, & Poot, 2015), and is premised on acceptance of the assumption that large sample sizes confer unbiased effect size estimates (Inzlicht, Gervais, & Berkman, 2015). Each of the other four tests used have been criticized on various grounds as well (e.g., Cunningham & Baumeister, 2016)
These arguments are not very convincing. Studies with larger samples produce more robust results than studies with smaller samples. Thus, placing a greater emphasizes on larger samples is justified by the smaller sampling error in these studies. In fact, random effects meta-analysis gives too much weight to small samples. It is also noteworthy that Baumeister and Inzlicht are not unbiased statisticians. Their work has been criticized as unreliable using PEESE and their responses are at least partially motivated by defending their work.
I will demonstrate that the PEETSE results are credible and that the other methods failed to reveal publication bias because effect-size meta-analyses fail to reveal the selection bias in original articles. For example, Wynn’s (1992) seminal finding was only significant with a one-sided test. However, the meta-analysis used a two-sided p-value of .055, which was coded as a non-significant result. This is a coding mistake because the result was used to reject the null-hypothesis with a different alpha level. A follow-up study by McCrink and Wynn (2004) reported a significant interaction effect with opposite effects for addition and subtraction, p = .016. However, the meta-analysis coded addition and subtraction separately, which produced one significant, p = .01, and one non-significant result, p = .504. The coding by subgroups is common in meta-analysis to conduct moderator analyses. However, this practices mutes the selection bias, which makes it more difficult to detect selection bias. Thus, bias tests need to be applied to the focal tests that supported authors’ main conclusions.
I recoded all 12 articles that reported 14 independent tests of the hypothesis that babies can add and subtract. I found only two articles that reported a failure to reject the null-hypothesis. Wakeley,Rivera, and Langer’s (2000) article is a rare example of an article in a major journal that reported a series of failed replication studies before 2011. “Unlike Wynn, we found no systematic evidence of either imprecise or precise adding and subtracting in young infants” (p. 1525). Moore and Cocas (2006) published two studies. Study 2 reported a non-significant result with an effect in the opposite direction. They clearly stated that this result failed to replicate Wynn’s results. “This test failed to reveal a reliable difference between the two groups’ fixation preferences, t(87) = -1.31, p = .09” However, they continued to examine the data with an Analysis of Variance that produced a significant four-way interaction, F(1, 85) = 4.80, p = .031. If this result had been used as the focal test, there would be only 2 non-significant results. However, I coded the study as reporting a non-significant result. Thus, the success rate across 14 studies in 12 articles is 11/14 = 78.6%. Without Wakeley et al.’s exceptional report of replication failures, the success rate would have been 93%, which is the norm in psychology publications (Sterling, 1959; Sterling et al., 1995).
The mean observed power of the 14 studies was MOP = 57%. The binomial probabilty of obtaining 11 or more significant results in 14 studies with 57% power is p = .080. This shows significant bias with the typical alpha level of .10 for bias tests due to the low power of these tests in small samples.
I also developed a more powerful bias tests that corrects for the inflation in the estimate of observed mean power that is based on the replicability index (Schimmack, 2016). Simulation studies show that this method has higher power, while maintaining good type-I error rates. To correct for inflation, I subtract the difference between the success rate and observed mean power from the observed mean power (simulation studies show that the mean is superior to the median that was used in the 2016 manuscript). This yields a value of .57 – (.79 – .57) = .35. The binomial probability of obtaining 11 out of 14 significant results with just 35% power is p = .001. These results confirm the results obtained with PEESE that publication bias contributes to the evidence in favor of babies’ math abilities.
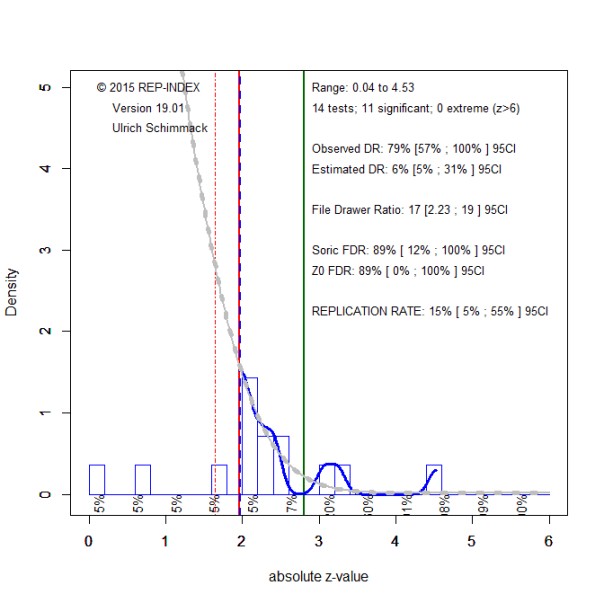
To examine the credibilty of the published literature, I submitted the 11 significant results to a z-curve analysis (Brunner & Schimmack, 2019). The z-curve analysis also confirms the presence of publication bias. Whereas the observed discovery rate is 79%, 95%CI = 57% to 100%, the expected discovery rate is only 6%, 95%CI = 5% to 31%. As the confidence intervals do not overlap, the difference is statistically significant. The expected replication rate is 15%. Thus, if the 11 studies could be replicated exactly only 2 rather than 11 are expected to be significant again. The 95%CI included a value of 5% which means that all studies could be false positives. This shows that the published studies do not provide empirical evidence to reject the null-hypothesis that babies cannot add or subtract.

Meta-analyses also have another drawback. They focus on results that are common across studies. However, subsequent studies are not mere replication studies. Several studies in this literature examined whether the effect is an artifact of the experimental procedure and showed that performance is altered by changing the experimental setup. These studies first replicate the original finding and then show that the effect can be attributed to other factors. Given the low power to replicate the effect, it is not clear how credible this evidence is. However, it does show that even if the effect were robust, it does not warrant the conclusion that infants can do math.
Conclusion
The problems with bias tests in standard meta-analysis are by no means unique to this article. It is well known that original articles publish nearly exclusively confirmatory evidence with success rates over 90%. However, meta-analyses often include a much larger number of non-significant results. This paradox is explained by the coding of original studies that produces non-significant results that were either not published or not the focus of an original article. This coding practices mutes the signal and makes it difficult to detect publication bias. This does not mean that the bias has disappeared. Thus, most published meta-analysis are useless because effect sizes are inflated to an unknown degree by selection for significance in the primary literature.
1 thought on “Baby Einstein: The Numbers Do Not Add Up”