It is well known that focal hypothesis tests in psychology journals nearly always reject the null-hypothesis (Sterling, 1959; Sterling et al., 1995). However, meta-analyses often contain a fairly large number of non-significant results. To my knowledge, the emergence of non-significant results in meta-analysis has not been examined systematically (happy to be proven wrong). Here I used the extremely well-done meta-analysis of money priming studies to explore this issue (Lodder, Ong, Grasman, & Wicherts, 2019).
I downloaded their data and computed z-scores by (1) dividing Cohen’s d by sampling errror (2/sqrt(N)) to compute t-values, (2) convert the absolute t-values into two-sided p-values, and (3) converting the p-values into absolute z-scores. The z-scores were submitted to a z-curve analysis (Brunner & Schimmack, 2019).


The first figure shows the z-curve for all test-statistics. Out of 282 tests, only 116 (41%) are significant. This finding is surprising, given the typical discovery rates over 90% in psychology journals. The figure also shows that the observed discovery rate of 41% is higher than the expected discovery rate of 29%, although the difference is relatively small and the confidence intervals overlap. This might suggest that publication bias in the money priming literature is not a serious problem. On the other hand, meta-analysis may mask the presence of publication bias in the published literature for a number of reasons.
Published vs. Unpublished Studies
Publication bias implies that studies with non-significant results end up in the proverbial file-drawer. Meta-analysts try to correct for publication bias by soliciting unpublished studies. The money-priming meta-analysis included 113 unpublished studies.
Figure 2 shows the z-curve for these studies. The observed discovery rate is slightly lower than for the full set of studies, 29%, and more consistent with the expected discovery rate, 25%. Thus, there this set of studies appears to be unbiased.

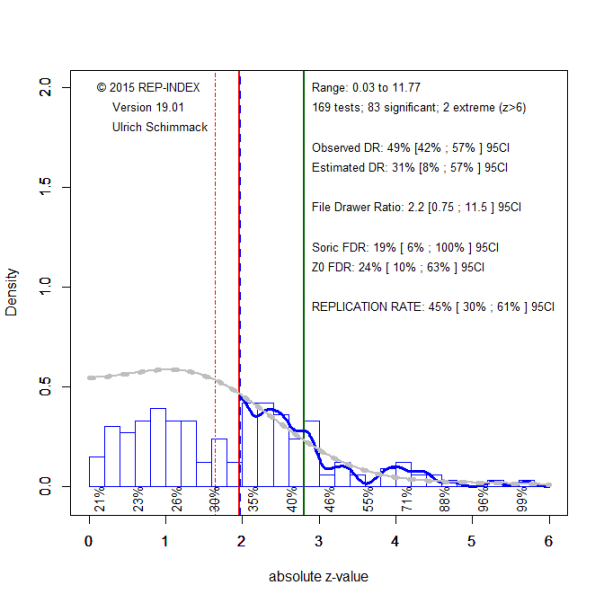
The complementary finding for published studies (Figure 3) is that the observed discovery rate increases, 49%, while the expected discovery rate remains low, 31%. Thus, published articles report a higher percentage of significant results without more statistical power to produce significant results.
A New Type of Publications: Independent Replication Studies
In response to concerns about publication bias and questionable research practices, psychology journals have become more willing to publish null-results. An emerging format are pre-registered replication studies with the explicit aim of probing the credibility of published results. The money priming meta-analysis included 47 independent replication studies.
Figure 4 shows that independent replication studies had a very low observed discovery rate, 4%, that is matched by a very low expected discovery rate, 5%. It is remarkable that the discovery rate for replication studies is lower than the discovery rate for unpublished studies. One reason for this discrepancy is that significance alone is not sufficient to get published and authors may be selective in the sharing of unpublished results.

Removing independent replication studies from the set of published studies further increases the observed discovery rate, 66%. Given the low power of replication studies, the expected discovery rate also increases somewhat, but it is notably lower than the observed discovery rate, 35%. The difference is now large enough to be statistically significant, despite the rather wide confidence interval around the expected discovery rate estimate.

Coding of Interaction Effects
After a (true or false) effect has been established in the literature, follow up studies often examine boundary conditions and moderators of an effect. Evidence for moderation is typically demonstrated with interaction effects that are sometimes followed by contrast analysis for different groups. One way to code these studies would be to focus on the main effect and to ignore the moderator analysis. However, meta-analysts often split the sample and treat different subgroups as independent samples. This can produce a large number of non-significant results because a moderator analysis allows for the fact that the effect emerged only in one group. The resulting non-significant results may provide false evidence of honest reporting of results because bias tests rely on the focal moderator effect to examine publication bias.
The next figure is based on studies that involved an interaction hypothesis. The observed discovery rate, 42%, is slightly higher than the expected discovery rate, 25%, but bias is relatively mild and interaction effects contribute 34 non-significant results to the meta-analysis.

The analysis of the published main effect shows a dramatically different pattern. The observed discovery rate increased to 56/67 = 84%, while the expected discovery rate remained low with 27%. The 95%CI do not overlap, demonstrating that the large file-drawer of missing studies is not just a chance finding.

I also examined more closely the 7 non-significant results in this set of studies.
- Gino and Mogliner (2014) reported results of a money priming study with cheating as the dependent variable. There were 98 participants in 3 conditions. Results were analyzed with percentage of cheating participants and extent of cheating. The percentage of cheating participants produced a significant contrast of the money priming and control condition, chi2(1, N = 65) = 3.97. However, the meta-analysis used the extent of cheating dependent variable, which should only a marginally significant effect with a one-tailed p-value of .07. “Simple contrasts revealed that participants cheated more in the money condition (M = 4.41, SD = 4.25) than in both the control condition (M = 2.76, SD = 3.96; p = .07) and the time condition (M = 1.55, SD = 2.41; p = .002).” Thus, this non-significant results was presented as supporting evidence in the original article.
- Jin, Z., Shiomura, K., & Jiang, L. (2015) conducted a priming studies with reaction times as dependent variables. This design is different from social priming studies in the meta-analysis. Moreover, money priming effects were examined within-participants, and the study produced several significant complex interaction effects. Thus, this study also does not count as a published failure to replicate money priming effects.
- Mukherjee, S., Nargundkar, M., & Manjaly, J. A. (2014) examined the influence of money primes on various satisfaction judgments. Study 1 used a small sample of N = 48 participants with three dependent variables. Two achieved significance, but the meta-analysis aggregated across DVs, which resulted in a non-significant outcome. Study 2 used a larger sample and replicated significance for two outcomes. It was not included in the meta-analysis. In this case, aggregation of DVs explains a non-significant result in the meta-analysis, while the original article reported significant results.
- I was unable to retrieve this article, but the abstract suggests that the article reports a significant interaction. ” We found that although money-primed reactance in control trials in which the majority provided correct responses, this effect vanished in critical trials in which the majority provided incorrect answers.”
[https://www.sbp-journal.com/index.php/sbp/article/view/3227] - Wierzbicki, J., & Zawadzka, A. (2014) published two studies. Study 1 reported a significant result. Study 2 added a non-significant result to the meta-analysis. Although the effect for money priming was not significant, this study reported a significant effect for credit-card priming and a money priming x morality interaction effect. Thus, the article also did not report a money-priming failure as the key finding.
- Gasiorowska, A. (2013) is an article in Polish.
- is a duplication of article 5
In conclusion, none of the 7 studies with non-significant results in the meta-analysis that were published in a journal reported that money priming had no effect on a dependent variable. All articles reported some significant results as the key finding. This further confirms how dramatically publication bias distorts the evidence reported in psychology journals.
Conclusion
In this blog post, I examined the discrepancy between null-results in journal articles and in meta-analysis, using a meta-analysis of money priming. While the meta-analysis suggested that publication bias is relatively modest, published articles showed clear evidence of publication bias with an observed discovery rate of 89%, while the expected discovery rate was only 27%.
Three factors contributed to this discrepancy: (a) the inclusion of unpublished studies, (b) independent replication studies, and (c) the coding of interaction effects as separate effects for subgroups rather than coding the main effect.
After correcting for publication bias, expected discovery rates are consistently low with estimates around 30%. The main exception are the independent replication studies that found no evidence at all. Overall, these results confirm that published money priming studies and other social priming studies cannot be trusted because the published studies overestimate replicability and effect sizes.
It is not the aim of this blog post to examine whether some money priming paradigms can produce replicable effects. The main goal was to explain why publication bias in meta-analysis is often small, when publication bias in the published literature is large. The results show that several factors contribute to this discrepancy and that the inclusion of unpublished studies, independent replication studies, and coding of effects explain most of these discrepancies.
2 thoughts on “Where Do Non-Significant Results in Meta-Analysis Come From?”