
Evaluations of individual researchers, departments, and universities are common and arguably necessary as science is becoming bigger. Existing rankings are based to a large extent on peer-evaluations. A university is ranked highly if peers at other universities perceive it to produce a steady stream of high-quality research. At present the most widely used objective measures rely on the quantity of research output and on the number of citations. These quantitative indicators of research quality work are also heavily influenced by peers because peer-review controls what gets published, especially in journals with high rejection rates, and peers decide what research they cite in their own work. The social mechanisms that regulate peer-approval are unavoidable in a collective enterprise like science that does not have a simple objective measure of quality (e.g., customer satisfaction ratings, or accident rates of cars). Unfortunately, it is well known that social judgments are subject to many biases due to conformity pressure, self-serving biases, confirmation bias, motivated biases, etc. Therefore, it is desirable to complement peer-evaluations with objective indicators of research quality.
Some aspects of research quality are easier to measure than others. Replicability rankings focus on one aspect of research quality that can be measured objectively, namely the replicability of a published significant result. In many scientific disciplines such as psychology, a successful study reports a statistically significant result. A statistically significant result is used to minimize the risk of publishing evidence for an effect that does not exist (or even goes in the opposite direction). For example, a psychological study that shows effectiveness of a treatment for depression would have to show that the effect in the study reveals a real effect that can be observed in other studies and in real patients if the treatment is used for the treatment of depression.
In a science that produces thousands of results a year, it is inevitable that some of the published results are fluke findings (even Toyota’s break down sometimes). To minimize the risk of false results entering the literature, psychology like many other sciences, adopted a 5% error rate. By using a 5% as the criterion, psychologists ensured that no more than 5% of results are fluke findings. With thousands of results published in each year, this still means that more than 50 false results enter the literature each year. However, this is acceptable because a single study does not have immediate consequences. Only if these results are replicated in other studies, findings become the foundation of theories and may influence practical decisions in therapy or in other applications of psychological findings (at work, in schools, or in policy). Thus, to outside observers it may appear safe to trust published results in psychology and to report about these findings in newspaper articles, popular books, or textbooks.
Unfortunately, it would be a mistake to interpret a significant result in a psychology journal as evidence that the result is probably true. The reason is that the published success rate in journals has nothing to do with the actual success rate in psychological laboratories. All insiders know that it is common practice to report only results that support a researcher’s theory. While outsiders may think of scientists as neutral observers (judges), insiders play the game of lobbyist, advertisers, and self-promoters. The game is to advance one’s theory, publish more than others, get more citations than others, and win more grant money than others. Honest reporting of failed studies does not advance this agenda. As a result, the fact that psychological studies report nearly exclusively success stories (Sterling, 1995; Sterling et al., 1995) tells outside observers nothing about the replicability of a published finding and the true rate of fluke findings could be 100%.
This problem has been known for over 50 years (Cohen, 1962; Sterling, 1959). So it would be wrong to call the selective reporting of successful studies an acute crisis. However, what changed is that some psychologists have started to criticize the widely accepted practice of selective reporting of successful studies (Asendorpf et al., 2012; Francis, 2012; Simonsohn et al., 2011; Schimmack, 2012; Wagenmakers et al., 2011). Over the past five years, psychologists, particularly social psychologists, have been engaged in heated arguments over the so-called “replication crisis.”
One group argues that selective publishing of successful studies occurred, but without real consequences on the trustworthiness of published results. The other group argues that published results cannot be trusted unless they have been successfully replicated. The problem is that neither group has objective information about the replicability of published results. That is, there is no reliable estimate of the percentage of studies that would produce a significant result again, if a representative sample of significant results published in psychology journals were replicated.
Evidently, it is not possible to conduct exact replication studies of all studies that have been published in the past 50 years. Fortunately, it is not necessary to conduct exact replication studies to obtain an objective estimate of replicability. The reason is that replicability of exact replication studies is a function of the statistical power of studies (Sterling et al., 1995). Without selective reporting of results, a 95% success rate is an estimate of the statistical power of the studies that achieved this success rate. Vice versa, a set of studies with average power of 50% is expected to produce a success rate of 50% (Sterling, et al., 1995).
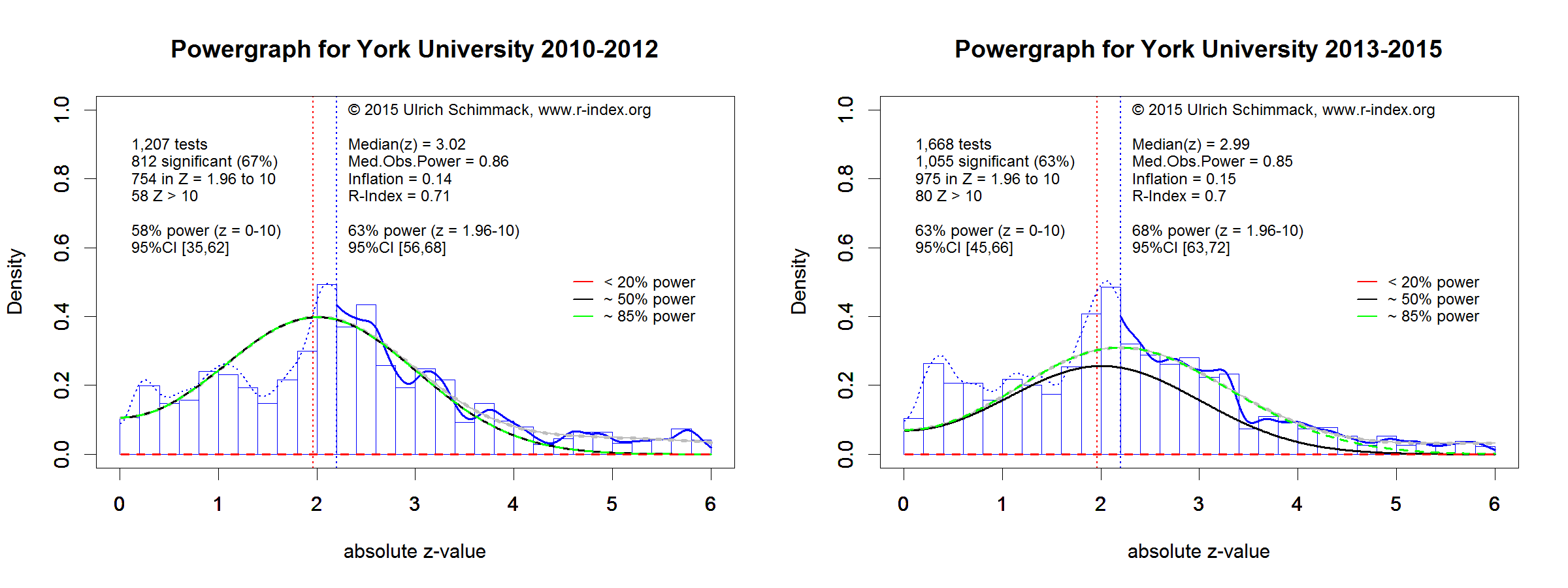
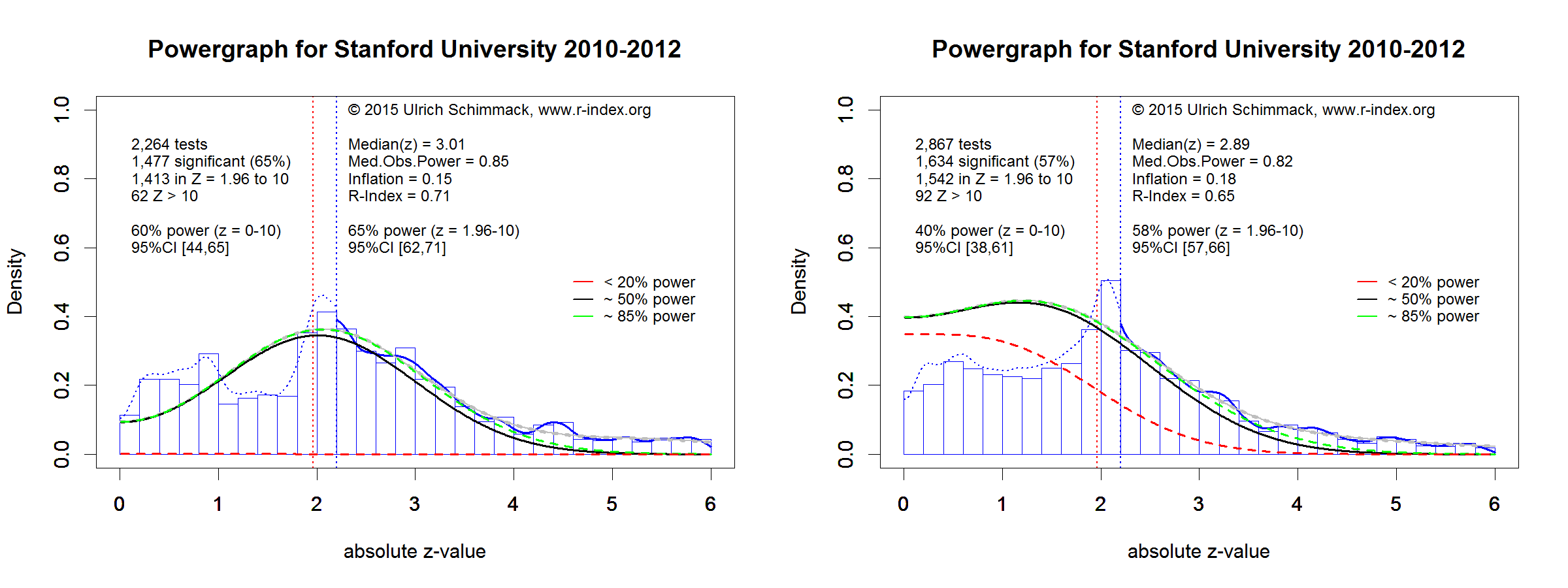
Although selection bias renders success rates uninformative, the actual statistical results provide valuable information that can be used to estimate the unbiased statistical power of published results. Although selection bias inflates effect sizes and power, Brunner and Schimmack (forcecoming) developed and validated a method that can correct for selection bias. This method makes it possible to estimate the replicability of published significant results on the basis of the original reported results. This statistical method was used to estimate the replicabilty of research published by psychology departments in the years from 2010 to 2015 (see Methodology for details).
The averages for the 2010-2012 period (M = 59) and the 2013-2015 period (M = 61) show only a small difference, indicating that psychologists have not changed their research practices in accordance with recommendations to improve replicability in 2011 (Simonsohn et al., 2011). For most of the departments the confidence intervals for the two periods overlap (see attached powergraphs). Thus, the more reliable average across all years is used for the rankings, but the information for the two time periods is presented as well.
There are no obvious predictors of variability across departments. Private universities are at the top (#1, #2, #8), the middle (#24, #26), and at the bottom (#44, #47). European universities can also be found at the top (#4, #5), middle (#25) and bottom (#46, #51). So are Canadian universities (#9, #15, #16, #18, #19, #50).
There is no consensus on an optimal number of replicability. Cohen recommended that researchers should plan studies with 80% power to detect real effects. If 50% of studies tested real effects with 80% power and the other 50% tested a null-hypothesis (no effect = 2.5% probability to replicate a false result again), the estimated power for significant results would be 78%. The effect on average power is so small because most of the false predictions produce a non-significant result. As a result, only a few studies with low replication probability dilute the average power estimate. Thus, a value greater than 70 can be considered broadly in accordance with Cohen’s recommendations.
It is important to point out that the estimates are very optimistic estimates of the success rate in actual replications of theoretically important effects. For a representative set of 100 studies (OSC, Science, 2015), Brunner and Schimmack’s statistical approach predicted a success rate of 54%, but the success rate in actual replication studies was only 37%. One reason for this discrepancy could be that the statistical approach assumes that the replication studies are exact, but actual replications always differ in some ways from the original studies, and this uncontrollable variability in experimental conditions posses another challenge for replicability of psychological results. Before further validation research has been completed, the estimates can only be used as a rough estimate of replicability. However, the absolute accuracy of estimates is not relevant for the relative comparison of psychology departments.
And now, without further ado, the first objective rankings of 51 psychology departments based on the replicability of published significant results. More departments will be added to these rankings as the results become available.
| Rank | University | 2010-2015 | 2010-2012 | 2013-2015 |
|---|---|---|---|---|
| 1 | U Penn | 72 | 69 | 75 |
| 2 | Cornell U | 70 | 67 | 72 |
| 3 | Purdue U | 69 | 69 | 69 |
| 4 | Tilburg U | 69 | 71 | 66 |
| 5 | Humboldt U Berlin | 67 | 68 | 66 |
| 6 | Carnegie Mellon | 67 | 67 | 67 |
| 7 | Princeton U | 66 | 65 | 67 |
| 8 | York U | 66 | 63 | 68 |
| 9 | Brown U | 66 | 71 | 60 |
| 10 | U Geneva | 66 | 71 | 60 |
| 11 | Northwestern U | 65 | 66 | 63 |
| 12 | U Cambridge | 65 | 66 | 63 |
| 13 | U Washington | 65 | 70 | 59 |
| 14 | Carleton U | 65 | 68 | 61 |
| 15 | Queen’s U | 63 | 57 | 69 |
| 16 | U Texas – Austin | 63 | 63 | 63 |
| 17 | U Toronto | 63 | 65 | 61 |
| 18 | McGill U | 63 | 72 | 54 |
| 19 | U Virginia | 63 | 61 | 64 |
| 20 | U Queensland | 63 | 66 | 59 |
| 21 | Vanderbilt U | 63 | 61 | 64 |
| 22 | Michigan State U | 62 | 57 | 67 |
| 23 | Harvard U | 62 | 64 | 60 |
| 24 | U Amsterdam | 62 | 63 | 60 |
| 25 | Stanford U | 62 | 65 | 58 |
| 26 | UC Davis | 62 | 57 | 66 |
| 27 | UCLA | 61 | 61 | 61 |
| 28 | U Michigan | 61 | 63 | 59 |
| 29 | Ghent U | 61 | 58 | 63 |
| 30 | U Waterloo | 61 | 65 | 56 |
| 31 | U Kentucky | 59 | 58 | 60 |
| 32 | Penn State U | 59 | 63 | 55 |
| 33 | Radboud U | 59 | 60 | 57 |
| 34 | U Western Ontario | 58 | 66 | 50 |
| 35 | U North Carolina Chapel Hill | 58 | 58 | 58 |
| 36 | Boston University | 58 | 66 | 50 |
| 37 | U Mass Amherst | 58 | 52 | 64 |
| 38 | U British Columbia | 57 | 57 | 57 |
| 39 | The University of Hong Kong | 57 | 57 | 57 |
| 40 | Arizona State U | 57 | 57 | 57 |
| 41 | U Missouri | 57 | 55 | 59 |
| 42 | Florida State U | 56 | 63 | 49 |
| 43 | New York U | 55 | 55 | 54 |
| 44 | Dartmouth College | 55 | 68 | 41 |
| 45 | U Heidelberg | 54 | 48 | 60 |
| 46 | Yale U | 54 | 54 | 54 |
| 47 | Ohio State U | 53 | 58 | 47 |
| 48 | Wake Forest U | 51 | 53 | 49 |
| 49 | Dalhousie U | 50 | 45 | 55 |
| 50 | U Oslo | 49 | 54 | 44 |
| 51 | U Kansas | 45 | 45 | 44 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Do you think the size of the department would matter? That is, could it be that as the department gets bigger (i.e., more graduate students and faculty members), there’s a greater chance that published effects by a given researcher have lower replicability?
I looked at this and there is no correlation with # faculty members, r = .04.
Thank you!
Is Carnegie Mellon just the psych department or does that include Social and Decision Sciences?
only faculty listed on the Psychology Department website. If Social and Decision sciences is a separate department, it is not included.
It is a separate department and covers all the behavioral econ types. i’d be curious what that looks like (obviously)
I’ll add it to the to-do-list. Thanks for pointing this out.
I was wondering whether the differences between departments could be due to the fact that some departments mainly focus on experimental work (often smaller samples), whereas others rely on large-scale/national longitudinal samples involving several thousands of participants?
There are few departments that focus on one type of research, but there are differences between departments in the type of research that is being done (e.g., OSU has a lot of social psychologists, Dartmouth is all neuroscience). When the sample is larger (I am hoping to rank at least 200 universities eventually), I will look for discipline and other variables as predictors of variability. Stay tuned.
Perhaps we’re too small for this, but I’d love to see how DePaul University and University of Southern Indiana fare.